克服反爬虫机制爬取智联招聘网站
一、实验内容
1、爬取网站:
智联招聘网站(https://www.zhaopin.com/)
2、网站的反爬虫机制:
在我频繁爬取智联招聘网站之后,它会出现以下文字(尽管我已经控制了爬虫的爬取速度):
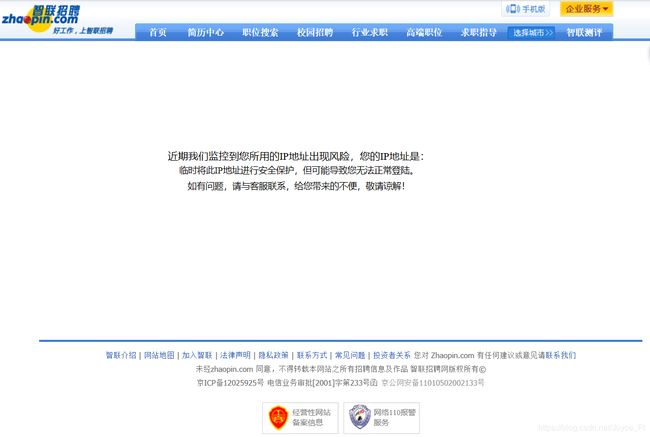
因此,我准备使用代理IP池爬取数据。网上多为付费的代理IP池,免费的IP池不稳定,因此我准备通过爬取有关代理IP池的网站上的IP地址搭建自己的代理IP池。
3、备注:
(1)通过分析智联招聘的AJAX接口,模拟AJAX请求直接获取json数据的方法爬取数据。
(2)如果两次请求的地址和参数相同,在不刷新页面的情况下,浏览器会缓存第一次请求的内容,服务端更新后浏览器仍然显示第一次的内容,这将会导致我们得不到最新的数据。因此我研究了智联招聘网站的url中的部分参数(下面会详细介绍)以使得我们爬取到的是最新数据,而不是浏览器中的缓存数据。
(3)当我们输入大于12的页数时,网站会自动修改为12。当我们浏览第12页时,可以看到“下一页”这个按钮变灰了。也就是说,智联招聘网站对于所有的搜索最多只显示12页的数据。这就导致我们得不到足够的数据量。因此我决定采用对多个关键字进行搜索来增加得到的数据量,当然这可能导致得到的数据冗余和重复,但是不管怎样我们都会对数据进行清洗(包括去重),所以这些重复的数据都会在去重中去掉。
![]()
二、实验步骤
1、分析智联招聘的AJAX接口
(1)找到数据所在的url
我使用的是谷歌浏览器。打开网页后,右击选择“检查”,再选择“Network”,我们可以浏览几页的内容,来观察页面出现了什么变化,如图出现了多个url:
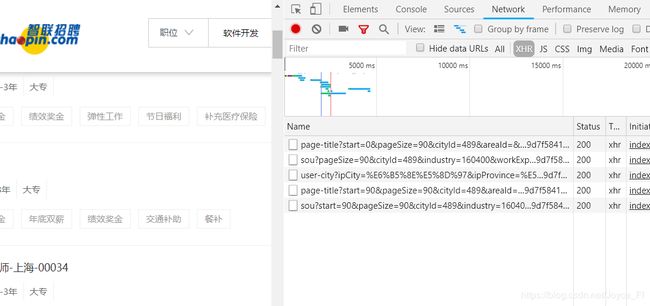
观察我们可以看出,url有三种:
一种是page-title开头的,我们单击之后查看一下它的Preview,如图:

我们可以知道该url中是网页的标题、描述之类的信息,并没有我们需要的数据。
一种是user-city开头的,我们单击之后查看一下它的Preview,如图:

我们可以知道该url中主要是是用户的地址信息等,也没有我们需要的数据。
还有一种是sou?开头的,如图:
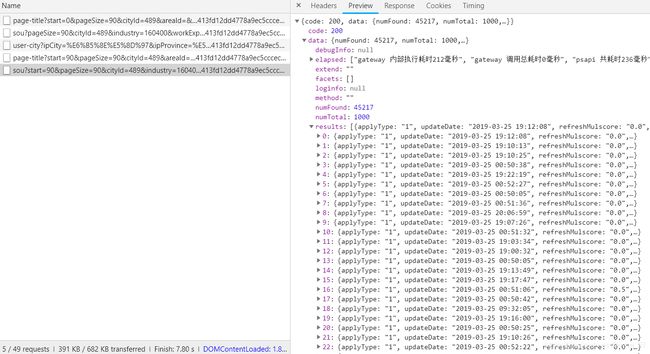
我们所需要的数据在这种url中。
(2)分析url的Headers
我们可以看到Request URL便是像这样拼接起来的。
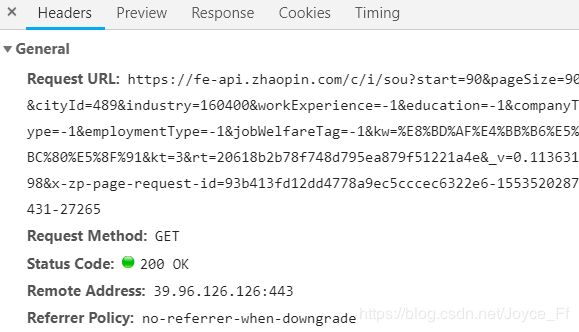
我们来逐一分析一下各参数的含义:
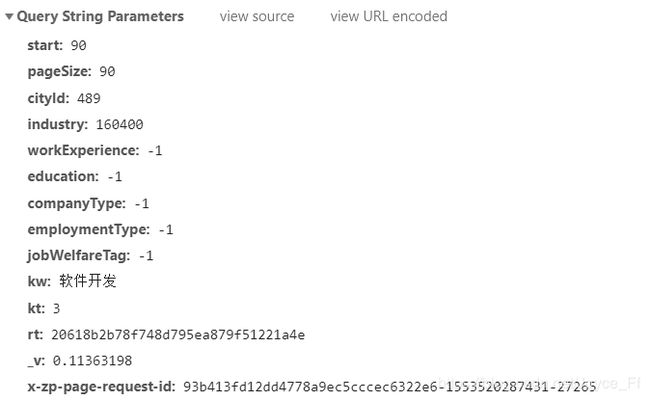
经过分析,可以知道:
start: 90是指每一页开始的数据偏移量,start等于90说明是第二页,
pageSize: 90是指每一页的数据数,
cityId: 489是城市的编号,这里默认全国,
industry、workExperience、education、companyType、employmentType、jobWelfareTag、kt均为默认值,
kw是关键词,
_v和x-zp-page-request-id便是开篇提到的用以防止浏览器显示缓存数据的参数。
_v是一个随机的8位小数。
x-zp-page-request-id 由三部分组成,32位随机数据通过md5简单加密得到+ 当前时间戳 + 随机数6位。
在了解url各参数的含义之后,我们来分析一下Headers

这里的Host、Origin、Referer、User-Agent在以后会有用。
2、编写爬虫
(1)生成_v和x-zp-page-request-id
# 经过分析_v就是一个随机的8位小数
# x-zp-page-request-id 由三部分组成,32位随机数据通过md5简单加密得到+ 当前时间戳 + 随机数6位
# 想办法用python简单实现所谓的加密算法x-zp-page-request-id
# 1、生成一个随机32位数id
md5 = hashlib.md5()
id = str(random.random())
md5.update(id.encode('utf-8'))
random_id = md5.hexdigest()
# 2、生成当前时间戳
now_time = int(time.time() * 1000)
# 3、生成随机6位数
randomnumb = int(random.random() * 1000000)
# 组合代码生成x-zp-page-request-id
x_zp_page_request_id = str(random_id) + '-' + str(now_time) + '-' + str(randomnumb)
# print(x_zp_page_request_id)
# 生成_v
url_v = round(random.random(), 8)
# print(url_v)
(2)组成url发送请求,返回数据
get_page(start, key):两参数分别为起始偏移量和关键词。根据我们在1中的分析,将各参数放在params中,然后调用urlencode()函数将各参数拼接起来得到url,将该url传给download_retry()函数。
download_retry(url):接收一个url,调用requests.get()发送请求,如果返回来的结果状态码是200,说明服务器成功返回网页,接收数据并返回。
def get_page(start, key):
params = {
"start": str(start),
"pageSize": "90",
"cityId": "489",
"industry": "160400",
# "salary": str("0,0"),
"workExperience": "-1",
"education": "-1",
"companyType": "-1",
"employmentType": "-1",
"jobWelfareTag": "-1",
"kw": key, # 关键词
"kt": "3",
"at": "d47e5b2c03e74fa7afa8df838182f953",
"rt": "20618b2b78f748d795ea879f51221a4e",
'_v': url_v,
"userCode": "1029652508",
'x-zp-page-request-id': x_zp_page_request_id
}
# print()
url = "https://fe-api.zhaopin.com/c/i/sou?" + urlencode(params, encoding='GBK')
newurl = url.replace("25", "")
# print(url.replace("25", ""))
# ajax请求头参数
# 这里的headers是一个全局变量,在该函数内为headers赋值
headers = {
"Host": "fe-api.zhaopin.com",
"Origin": "https://sou.zhaopin.com",
"Referer": "https://sou.zhaopin.com/?jl=489&in=160400&sf=0&st=0&kw=" + key + "&kt=3",
"User-Agent": 'Baiduspider', # "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Accept-Encoding": "gzip, deflate, br"
}
result_json = download_retry(newurl)
return result_json
def download_retry(url):
try:
# 此时的数据库中的IP地址都是经过测试可用的
# 从数据库中随机选择一个IP地址
random_ip = 'SELECT proxy_type,ip, port FROM proxy_ip ORDER BY RAND() LIMIT 1;'
cursor.execute(random_ip)
proxy_type, ip, port = cursor.fetchone()
proxies = {proxy_type: proxy_type + '://' + ip + ':' + port}
requests.packages.urllib3.disable_warnings()
response = requests.get(url, headers=headers, proxies=proxies, timeout=5)
#result = json.loads(response.text)
#print(result)
if response.status_code == 200:
result = response.json()
else:
result = None
except:
raise ConnectionError
return result
(3)解析json数据,写入excel表格
def get_content(json):
if json is not None:
items = []
result_items = json.get("data").get("results")
#print(result_items)
for item in result_items:
dic = {}
dic['job_name'] = item['jobName']
dic['company_name'] = item['company']['name']
dic['work_place'] = item['city']['display']
dic['salary'] = item['salary']
dic['education'] = item['eduLevel']['name']
dic['experience'] = item['workingExp']['name']
dic['welfare'] = item['welfare']
dic['job_href'] = item['positionURL']
dic['company_href'] = item.get("company").get("url")
items.append(dic)
# print(items)
return items
def write_excel_xls_append(items):
index = len(items) # 获取需要写入数据的行数
workbook = xlrd.open_workbook("Job1.xls") # 打开工作簿
sheets = workbook.sheet_names() # 获取工作簿中的所有表格
worksheet = workbook.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个表格
rows_old = worksheet.nrows # 获取表格中已存在的数据的行数
new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象
new_worksheet = new_workbook.get_sheet(0) # 获取转化后工作簿中的第一个表格
for i in range(0, index):
item = items[i]
# 追加写入数据,注意是从i+rows_old行开始写入
new_worksheet.write(i+rows_old, 0, item['job_name'])
new_worksheet.write(i+rows_old, 1, item['company_name'])
new_worksheet.write(i+rows_old, 2, item['work_place'])
new_worksheet.write(i+rows_old, 3, item['salary'])
new_worksheet.write(i+rows_old, 4, item['education'])
new_worksheet.write(i+rows_old, 5, item['experience'])
# str = ','.join(company_href[i]) # 用,将各福利连接起来
new_worksheet.write(i+rows_old, 6, item['welfare'])
new_worksheet.write(i+rows_old, 7, item['job_href'])
new_worksheet.write(i+rows_old, 8, item['company_href'])
new_workbook.save("Job1.xls") # 保存工作簿
print("追加数据成功!")
(4)执行结果
执行程序后,用户可以无限输入关键词爬取数据,直到输入#表示程序退出。
在这里,我们输入“web”进行测试。(数据量大,只截图了开始和结束。)


此时的excel表格,我们可以看出数据已经追加成功。

3、建立代理IP池
(1)爬取西刺的免费IP代理保存到数据库中
获取当前的免费IP地址,端口,以及协议及速度。
import pymysql
import requests
from scrapy.selector import Selector
# 数据库连接
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='web_crawler', charset='utf8')
cursor = conn.cursor()
def crawl_ips():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/59.0.3071.115 Safari/537.36"}
for i in range(1, 1001):
url = 'http://www.xicidaili.com/wt/{0}'.format(i)
req = requests.get(url=url, headers=headers)
selector = Selector(text=req.text)
all_trs = selector.xpath('//*[@id="ip_list"]//tr') # 共同前缀
ip_lists = []
for tr in all_trs[1:]:
speed_str = tr.xpath('td[7]/div/@title').extract()[0]
if speed_str:
speed = float(speed_str.split('秒')[0])
ip = tr.xpath('td[2]/text()').extract()[0]
port = tr.xpath('td[3]/text()').extract()[0]
proxy_type = tr.xpath('td[6]/text()').extract()[0].lower()
ip_lists.append((ip, port, speed, proxy_type))
for ip_info in ip_lists:
cursor.execute(
f"INSERT proxy_ip(ip,port,speed,proxy_type) VALUES('{ip_info[0]}','{ip_info[1]}',{ip_info[2]},"
f"'{ip_info[3]}') "
)
conn.commit()
#crawl_ips()
(2)从数据库中随机取免费的IP地址,并且判断该IP地址的可用性。
class GetIP(object):
# 删除无效的免费ip信息
def delete(self, ip):
delete_sql = 'DELETE FROM proxy_ip WHERE ip="{0}"'.format(ip)
cursor.execute(delete_sql)
conn.commit()
return True
def valid_ip(self, ip, port, proxy_type):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/59.0.3071.115 Safari/537.36"}
try:
proxies = {proxy_type: proxy_type + '://' + ip + ':' + port}
req = requests.get('http://ip.chinaz.com/getip.aspx', headers=headers, proxies=proxies, timeout=5)
except:
print('invalid ip and port')
self.delete(ip)
return False
else:
if 200 <= req.status_code < 300:
# print('{0} effective ip~'.format(proxies))
print(req.text)
return True
else:
print('invalid ip and port')
self.delete(ip)
return False
# 随机从数据库中取ip地址
@property
def get_random_ip(self):
random_ip = 'SELECT proxy_type,ip, port FROM proxy_ip ORDER BY RAND() LIMIT 1;'
cursor.execute(random_ip)
proxy_type, ip, port = cursor.fetchone()
# 把获取到的ip地址通过拆包的方式分别复制给协议,IP以及端口,
# 然后把这三个参数送给valid_ip方法做验证
valid_ip = self.valid_ip(ip, port, proxy_type)
if valid_ip:
return {proxy_type: proxy_type + '://' + ip + ':' + port}
else:
return self.get_random_ip
proxy = GetIP()
print(proxy.get_random_ip)
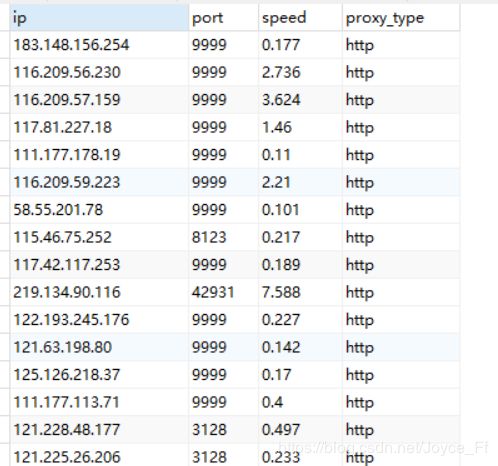
得到的IP地址(部分):
有人问全部的源码,其实上面就是所有的代码了,再加几个函数调用就行了。
def input_page_and_keyword():
str = input("请输入关键词:(若停止输入,请输入#)")
# print(type(str))
while str != "#":
write_excel_xls_append(crawler(12, str))
input_page_and_keyword()
if str == "#":
print("程序退出。")
input_page_and_keyword()