【Linux进程通信】管道,FIFO
简介
进程通信最基本的一种通信机制,是进程之间一个单向数据流:一个进程写入管道的所有数据都由内核定向流入到另外一个进程。(如果多进程使用管道通信,则需要通过锁来控制)。
管道的特点:
- 基于一组VFS对象,因而没有对应的磁盘映像(匿名管道对用户不可见,但是FIFO是以终端用户认可的文件存在的)
- POSIX只定义半双工管道,因而简历通信管道时,每个管道的文件描述符是单向的。所以pipe系统调用需要返回两个描述符,一个用于写,一个用于读。
分类:
管道:匿名管道
FIFO:命名管道
匿名管道
特征:
- 匿名,在文件系统中间不可见
- 传输的是无格式的字节码流
- 只支持半双工通信,在操作一个读管道柯写管道,必须保证只有一个管道打开。
- 此通信方式发生在两个有亲缘关系的进程之间
以shell中间管道的使用为例,可以看出两个进程通信的流程以及原理:
此处缺省一个流程图介绍 shell 指令: ls|more
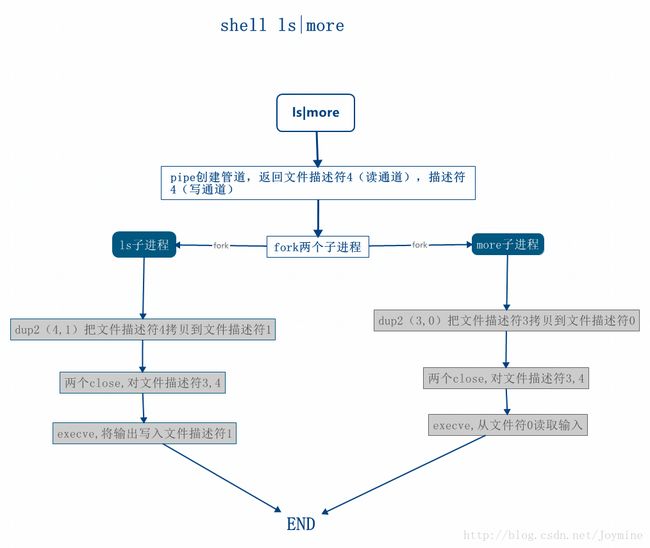
管道的操作流程:
1,创建管道
API 1:
int pipe(int pipefd[2]);
pipefd[2]是一个长度为2的文件描述符数组,pipefd[0]是读端,pipefd[1]是写端,因为pipe是半双工。返回值小于0表示创建失败
API 2:
*FILE *popen(const char *command, const char *type);
int pclose(FILE stream);
作用:popen, pclose - pipe stream to or from a process打开或者关闭一个pipe
其中 popen接收的参数:
@command :可以理解为可执行文件的路径
@type:数据的传输方向
使用popen的实质是发生了如下流程:
- pipe()系统调用创建管道
- a, 创建一个新进程根据type确定pipe流方向,以及相应的数据流对应;b,关闭pipe返回文件描述符;c使用execve系统调用可执行文件
- 关闭读/写 pipe通道的文件描述符
- 返回FILE指针,指向仍然打开的管道所涉及的任一文件描述符
FIFO 实名管道
匿名管道的缺点是无法打开已经存在的管道,这是任意两个进程不能共享一个管道,也就是只用管道由同一个祖先创建。实名管道存在的意义就业就是如此。实名管道就是一个设备文件,是要知道该设备文件的地址,进程就可以利用这个管道进行通信。
FIFO相比匿名管道:
- FIFO索引节点出现在系统文件目录树,而非pipefs
- FIFO 是双向通信管道,可以读/写 同一个管道
实名管道的创建:
int mknod(const char *filename, mode_t mode | S_IFIFO, (dev_t)0);
int mkfifo(const char *filename, mode_t mode); 【POSIX引入】
相关结构体
参考文件:kernel/include/linux/pipe_fs_i.h
创建一个pipe,实际上是需要一个管道描述符,如下
/**
* struct pipe_inode_info - a linux kernel pipe
* @mutex: mutex protecting the whole thing
* @wait: reader/writer wait point in case of empty/full pipe
* @nrbufs: the number of non-empty pipe buffers in this pipe
* @buffers: total number of buffers (should be a power of 2)
* @curbuf: the current pipe buffer entry
* @tmp_page: cached released page
* @readers: number of current readers of this pipe
* @writers: number of current writers of this pipe
* @files: number of struct file refering this pipe (protected by ->i_lock)
* @waiting_writers: number of writers blocked waiting for room
* @r_counter: reader counter
* @w_counter: writer counter
* @fasync_readers: reader side fasync
* @fasync_writers: writer side fasync
* @bufs: the circular array of pipe buffers
**/
struct pipe_inode_info {
struct mutex mutex;//互斥锁
wait_queue_head_t wait;//管道FIFO等待队列
unsigned int nrbufs,/*非空管道缓存区数,也就是待读数据的缓存区数*/ curbuf,/*待读数据第一个缓存区索引*/ buffers/*缓存区总数量,值应该是2的幂*/;
unsigned int readers;/*该管道的读进程的数量,标志*/
unsigned int writers;/*该管道的写进程的数量,标志*/
unsigned int files;
unsigned int waiting_writers;/*等待队列中间睡眠的写进程数*/
unsigned int r_counter;/*类似 readers,当等待读取FIFO时使用*/
unsigned int w_counter;
struct page *tmp_page;/*高速缓存页框指针*/
struct fasync_struct *fasync_readers;//reader side fasync 用于通过信号进行的异步IO通知
struct fasync_struct *fasync_writers;//writer side fasync用于通过信号进行的异步IO通知
struct pipe_buffer *bufs;/*该管道缓存区描述符数组,实际上是一个单独的页 page*/
/*每个管道可以管理16个缓存区,可以看作是一个环形缓存区*/
};管道描述符中间,包含管道缓存区描述符,每个管道可以使用16个管道缓存区(linux2.6.11)
/**
* struct pipe_buffer - a linux kernel pipe buffer
* @page: the page containing the data for the pipe buffer
* @offset: offset of data inside the @page
* @len: length of data inside the @page
* @ops: operations associated with this buffer. See @pipe_buf_operations.
* @flags: pipe buffer flags. See above.
* @private: private data owned by the ops.
**/
struct pipe_buffer {
struct page *page;/*缓存区页框描述符地址*/
unsigned int offset, len;/*页框内有效数据的当前位置,页框内有效数据的长度*/
const struct pipe_buf_operations *ops;/*该管道缓存区方法表的地址,管道缓存区为空时,为NULL*/
unsigned int flags;
unsigned long private;
};每个管道缓存区中间的方法表描述符:
/*
* Note on the nesting of these functions:
*
* ->confirm()
* ->steal()
* ...
* ->map()
* ...
* ->unmap()
*
* That is, ->map() must be called on a confirmed buffer,
* same goes for ->steal(). See below for the meaning of each
* operation. Also see kerneldoc in fs/pipe.c for the pipe
* and generic variants of these hooks.
*/
struct pipe_buf_operations {
/*
* This is set to 1, if the generic pipe read/write may coalesce
* data into an existing buffer. If this is set to 0, a new pipe
* page segment is always used for new data.
*/
int can_merge;
/*
* ->map() returns a virtual address mapping of the pipe buffer.
* The last integer flag reflects whether this should be an atomic
* mapping or not. The atomic map is faster, however you can't take
* page faults before calling ->unmap() again. So if you need to eg
* access user data through copy_to/from_user(), then you must get
* a non-atomic map. ->map() uses the kmap_atomic slot for
* atomic maps, you have to be careful if mapping another page as
* source or destination for a copy.
*/
/*访问缓存区数据之前调用*/
void * (*map)(struct pipe_inode_info *, struct pipe_buffer *, int);
/*
* Undoes ->map(), finishes the virtual mapping of the pipe buffer.
*/
/*不再访问缓存区数据时调用*/
void (*unmap)(struct pipe_inode_info *, struct pipe_buffer *, void *);
/*
* ->confirm() verifies that the data in the pipe buffer is there
* and that the contents are good. If the pages in the pipe belong
* to a file system, we may need to wait for IO completion in this
* hook. Returns 0 for good, or a negative error value in case of
* error.
*/
int (*confirm)(struct pipe_inode_info *, struct pipe_buffer *);
/*
* When the contents of this pipe buffer has been completely
* consumed by a reader, ->release() is called.
*/
/*释放管道缓存区时调用*/
void (*release)(struct pipe_inode_info *, struct pipe_buffer *);
/*
* Attempt to take ownership of the pipe buffer and its contents.
* ->steal() returns 0 for success, in which case the contents
* of the pipe (the buf->page) is locked and now completely owned
* by the caller. The page may then be transferred to a different
* mapping, the most often used case is insertion into different
* file address space cache.
*/
int (*steal)(struct pipe_inode_info *, struct pipe_buffer *);
/*
* Get a reference to the pipe buffer.
*/
void (*get)(struct pipe_inode_info *, struct pipe_buffer *);
};