Python数据扩展包之Scikit-learn
- 官方网站:https://scikit-learn.org/stable/index.html
- 官方中文版:http://sklearn.apachecn.org/#/
- 莫烦课程:https://morvanzhou.github.io/tutorials/machine-learning/sklearn/
- Scikit-Learn高清全景图:http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
- 数据集:http://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
scikit-learn(简记sklearn),是用python实现的机器学习算法库。sklearn可以实现数据预处理、分类、回归、降维、模型选择等常用的机器学习算法。sklearn是基于NumPy, SciPy, matplotlib的。
- NumPy python实现的开源科学计算包。它可以定义高维数组对象;矩阵计算和随机数生成等函数。
- SciPy python实现的高级科学计算包。它和Numpy联系很密切,Scipy一般都是操控Numpy数组来进行科学计算,所以可以说是基于Numpy之上了。Scipy有很多子模块可以应对不同的应用,例如插值运算,优化算法、图像处理、数学统计等。
- matplotlib python实现的作图包。使用matplotlib能够非常简单的可视化数据,仅需要几行代码,便可以生成直方图、功率谱、条形图、错误图、散点图等。
Sklearn 包含了很多种机器学习的方式:
- Classification 分类
- Regression 回归
- Clustering 非监督分类
- Dimensionality reduction 数据降维
- Model Selection 模型选择
- Preprocessing 数据预处理

安装
安装 Scikit-learn (sklearn) 最简单的方法就是使用 pip 安装它.
首先确认自己电脑中有安装
- Python (>=2.6 或 >=3.3 版本)
- Numpy (>=1.6.1)
- Scipy (>=0.9)
在Terminal, 输入:
# python 2+ 版本复制:
pip install -U scikit-learn
# python 3+ 版本复制:
pip3 install -U scikit-learn注: Windows 用户可以选择用 Anaconda 来安装所有 python 的科学计算模块.
学习方法
Sklearn 官网提供了一个流程图,蓝色圆圈内是判断条件,绿色方框内是可以选择的算法

从 START 开始,首先看数据的样本是否 >50,小于则需要收集更多的数据。
由图中,可以看到算法有四类,分类,回归,聚类,降维。其中 分类和回归是监督式学习,即每个数据对应一个 label。 聚类 是非监督式学习,即没有 label。 另外一类是 降维,当数据集有很多很多属性的时候,可以通过降维算法把属性归纳起来。
通用学习模式
Sklearn 把所有机器学习的模式整合统一起来了,学会了一个模式就可以通吃其他不同类型的学习模式。
例如,分类器,Sklearn 本身就有很多数据库,可以用来练习。 以 Iris 的数据为例,这种花有四个属性,花瓣的长宽,茎的长宽,根据这些属性把花分为三类。
我们要用 分类器 去把四种类型的花分开。
#/usr/bin/env.python
import numpy as np
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris = datasets.load_iris()
iris_x = iris.data
iris_label = iris.target
#test date :30%
x_train,x_test,y_train,y_test = train_test_split(iris_x,iris_label,test_size=0.3)
knn = KNeighborsClassifier()
knn.fit(x_train,y_train)
print "KNN predict",knn.predict(x_test)
print "Y_test_label:",y_test
数据库
sklearn的数据库包含2部分:加载load部分和生成generator部分
 |
 |
#/usr/bin/env.python
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
#load and fetch popular reference dataset
loaded_data = datasets.load_boston()
data_x = loaded_data.data
data_y = loaded_data.target
model = LinearRegression()
model.fit(data_x,data_y)
print model.predict(data_x[:4,:])
print data_y[:4]
# data generators
X1,y1 = datasets.make_regression(n_samples=100,n_features=1,n_targets=1,noise=10)
plt.figure()
plt.subplot(1,2,1)
l1 =plt.scatter(X1,y1)
plt.legend(loc ='upper right')
plt.legend(handles=[l1], labels=['noise=10'], loc='best')
X2,y2 = datasets.make_regression(n_samples=100,n_features=1,n_targets=1,noise=50)
plt.subplot(1,2,2)
l2=plt.scatter(X2,y2)
plt.legend(loc ='upper right')
plt.legend(handles=[l2], labels=['noise=50'], loc='best')
plt.show()#load and fetch popular reference dataset
loaded_data = datasets.load_boston()
data_x = loaded_data.data
data_y = loaded_data.target
model = LinearRegression()
model.fit(data_x,data_y)
print model.predict(data_x[:4,:])
print data_y[:4]
# data generators
X1,y1 = datasets.make_regression(n_samples=100,n_features=1,n_targets=1,noise=10)
plt.figure()
plt.subplot(1,2,1)
l1 =plt.scatter(X1,y1)
plt.legend(loc ='upper right')
plt.legend(handles=[l1], labels=['noise=10'], loc='best')
X2,y2 = datasets.make_regression(n_samples=100,n_features=1,n_targets=1,noise=50)
plt.subplot(1,2,2)
l2=plt.scatter(X2,y2)
plt.legend(loc ='upper right')
plt.legend(handles=[l2], labels=['noise=50'], loc='best')
plt.show()
Model的属性和功能
#/usr/bin/env.python
#_*_coding:utf-8_*_
from sklearn import datasets
from sklearn.linear_model import LinearRegression
dataIris = datasets.load_iris()
x_data = dataIris.data
y_label = dataIris.target
model = LinearRegression()
model.fit(x_data,y_label) #功能fit
print "功能 predict:",model.predict(x_data[:4,:])
print "属性 斜率 coef_:",model.coef_
print "属性 截距 intercept_:",model.intercept_
print "属性get_params:",model.get_params() #取出之前定义的参数
print "属性 精确度 score:",model.score(x_data,y_label) #对 Model 用 R^2 的方式进行打分Normalization
#/usr/bin/env.python
#_*_coding:utf-8_*_
from sklearn import preprocessing
import numpy as np
from sklearn.cross_validation import train_test_split
# 生成适合做classification的模块
from sklearn.datasets.samples_generator import make_classification
# SVM中的Support Vector Classifier
from sklearn.svm import SVC
import matplotlib.pyplot as plt
#生成具有2种属性的300个数据
x,y = make_classification(
n_samples=300, n_features=2 ,
n_redundant=0,n_informative=2,
random_state=22,n_clusters_per_class=1,
scale=100 )
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3)
clf = SVC()
clf.fit(x_train,y_train)
print clf.score(x_test,y_test)
x = preprocessing.scale(x)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3)
clf = SVC()
clf.fit(x_train,y_train)
print clf.score(x_test,y_test)OUT:
0.644444444444 #正规化前
0.944444444444 #正规化
0.644444444444 #正规化前
0.944444444444 #正规化
Evaluation
1、Training data and Test data
2、Error curve
3、Accuracy curve
4、Normalization
5、Cross-Validation
交叉验证:
#/usr/bin/env.python
#_*_coding:utf-8_*_
from sklearn.datasets import load_iris
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.cross_validation import cross_val_score #k折交叉验证
import matplotlib.pyplot as plt
dataIris = load_iris()
x_data = dataIris.data
y_label = dataIris.target
#基础验证
x_train,x_test,y_train,y_test = train_test_split(x_data,y_label,random_state=4)
knn = KNeighborsClassifier(n_neighbors=5) # k=5
knn.fit(x_train,y_train)
print knn.score(x_test,y_test)
#交叉验证
k_ranges=range(1,31)
k_scores = []
loss_scores = []
for k in k_ranges:
knn = KNeighborsClassifier(n_neighbors=k)
#classification
scores = cross_val_score(knn,x_data,y_label,cv=10,scoring='accuracy')
#regression:平均方差(Mean squared error)用于判断回归(Regression)模型的好坏
loss =-cross_val_score(knn,x_data,y_label,cv=10,scoring="mean_squared_error")
#print k,":",scores.mean()
k_scores.append(scores.mean())
loss_scores.append(loss.mean())
plt.subplot(1,2,1)
plt.plot(k_ranges,k_scores)
plt.xlabel("K")
plt.ylabel("ACCURACY")
plt.subplot(1,2,2)
plt.plot(k_ranges,loss_scores)
plt.xlabel("K")
plt.ylabel("LOSS")
plt.show()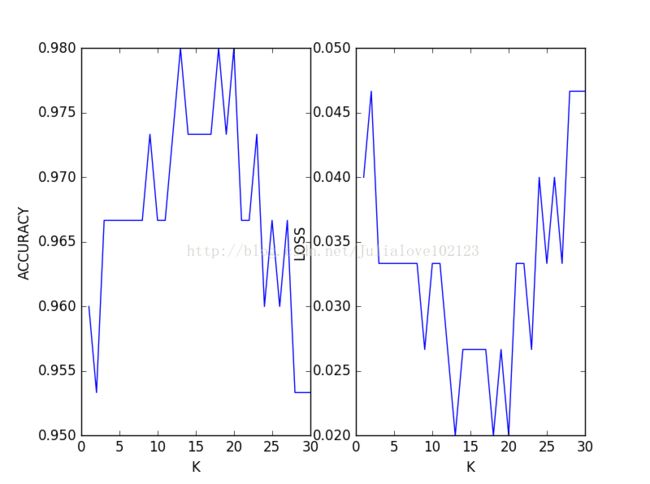
过拟合:
#/usr/bin/env.python
#_*_coding:utf-8_*_
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.learning_curve import learning_curve
import numpy as np
dataDigits = load_digits()
x_data = dataDigits.data
y_label = dataDigits.target
#Learning curve 检视过拟合
train_sizes,train_loss,test_loss = learning_curve(
SVC(gamma=0.001),x_data,y_label,cv=10,
scoring='mean_squared_error',train_sizes=[0.1,0.25,0.5,0.75,1])
train_loss_mean = -np.mean(train_loss,axis = 1)
test_loss_mean = -np.mean(test_loss,axis = 1)
plt.plot(train_sizes,train_loss_mean,'o-',color='r',label = "Training")
plt.plot(train_sizes,test_loss_mean,'o-',color='g',label = "Cross-Validation")
plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc = "best")
plt.show()
validation_curve 检视过拟合
#/usr/bin/env.python
#_*_coding:utf-8_*_
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.learning_curve import validation_curve
import numpy as np
dataDigits = load_digits()
x_data = dataDigits.data
y_label = dataDigits.target
param_range = np.logspace(-6,-2.3,5)
#validation_curve 检视过拟合
train_loss,test_loss = validation_curve(
SVC(),x_data,y_label,param_name='gamma',param_range=param_range,cv=10,
scoring='mean_squared_error')
train_loss_mean = -np.mean(train_loss,axis = 1)
test_loss_mean = -np.mean(test_loss,axis = 1)
plt.plot(param_range,train_loss_mean,'o-',color='r',label = "Training")
plt.plot(param_range,test_loss_mean,'o-',color='g',label = "Cross-Validation")
plt.xlabel("param")
plt.ylabel("Loss")
plt.legend(loc = "best")
plt.show()

保存模型
1、pickle保存与读取
2、joblib保存与读取
#/usr/bin/env.python
#_*_coding:utf-8_*_
from sklearn import svm
from sklearn import datasets
clf = svm.SVC()
iris = datasets.load_iris()
x,y = iris.data,iris.target
clf.fit(x,y)
# method 1 : pickle
import pickle
#save
with open('save/clf.pickle','wb') as f: #wb 是以写的形式打开
pickle.dump(clf,f)
#restore
with open('save/clf.pickle','rb')as f: #wb 是以读的形式打开
clf2 = pickle.load(f)
print "From pickle :",clf2.predict(x[0:1])
#method 2:joblib
from sklearn.externals import joblib
#save
joblib.dump(clf,'save/clf.pkl')
#restore
clf3 = joblib.load('save/clf.pkl')
print "From joblib :",clf3.predict(x[0:1])
# method 1 : pickle
import pickle
#save
with open('save/clf.pickle','wb') as f: #wb 是以写的形式打开
pickle.dump(clf,f)
#restore
with open('save/clf.pickle','rb')as f: #wb 是以读的形式打开
clf2 = pickle.load(f)
print "From pickle :",clf2.predict(x[0:1])
#method 2:joblib
from sklearn.externals import joblib
#save
joblib.dump(clf,'save/clf.pkl')
#restore
clf3 = joblib.load('save/clf.pkl')
print "From joblib :",clf3.predict(x[0:1])
【注:save文件夹要预先建立】