神经网络中常用激活函数总结
好久没写博客和学习笔记了,感觉最近总是没有学习状态呀,就很烦。虽说确实是有在看一些视频课程但是总是精神有力,每天过得也好快总感觉啥都没学时间就过去了阿西。还是得逼最近写写笔记才能不那么恍惚。前几天开始学习Coursera上吴恩达的深度学习课程,然后顺便做做笔记吧。
神经元的结构如下图所示,其中f就是激活函数(activation function),它的输入是x的线性组合,然后对其进行某种固定的数学操作后输出到下一个神经元。
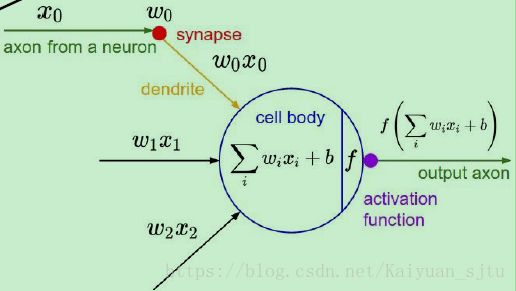
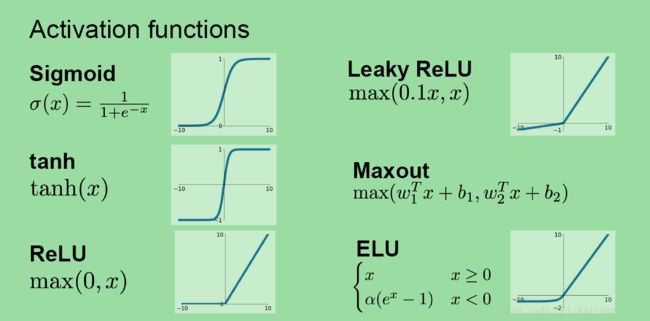
常用的神经元激活函数主要有以下几种:
- sigmoid
- tanh
- ReLU
- Leaky ReLU
- Maxout
- ELU
一、sigmoid激活函数
sigmoid非线性函数的数学公式是:![]()
函数图像如下图所示。它输入实数值并将其“挤压”到0到1范围内。更具体地说,很大的负数变成0,很大的正数变成1。
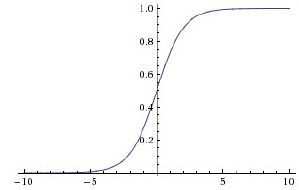
在历史上,sigmoid函数非常常用,这是因为它对于神经元的激活频率有良好的解释:从完全不激活(0)到在求和后的最大频率处的完全饱和(saturated)的激活(1)。然而现在sigmoid函数已经不太受欢迎,实际很少使用了,这是因为它有两个主要缺点:
(1)Sigmoid函数饱和使梯度消失。
sigmoid神经元有一个不好的特性,就是当神经元的激活在接近0或1处时会饱和:在这些区域,梯度几乎为0。回忆一下,在反向传播的时候,这个(局部)梯度将会与整个损失函数关于该门单元输出的梯度相乘。因此,如果局部梯度非常小,那么相乘的结果也会接近零,这会有效地“杀死”梯度,几乎就有没有信号通过神经元传到权重再到数据了。还有,为了防止饱和,必须对于权重矩阵初始化特别留意。比如,如果初始化权重过大,那么大多数神经元将会饱和,导致网络就几乎不学习了。
(2)Sigmoid函数的输出不是零中心的。
这个性质并不是我们想要的,因为在神经网络后面层中的神经元得到的数据将不是零中心的。这一情况将影响梯度下降的运作,因为如果输入神经元的数据总是正数,那么关于的梯度在反向传播的过程中,将会要么全部是正数,要么全部是负数(具体依整个表达式而定)。这将会导致梯度下降权重更新时出现z字型的下降。然而,可以看到整个批量的数据的梯度被加起来后,对于权重的最终更新将会有不同的正负,这样就从一定程度上减轻了这个问题。因此,该问题相对于上面的神经元饱和问题来说只是个小麻烦,没有那么严重。
(3)exp()指数计算复杂度较大
二、Tanh激活函数
对上述sigmoid函数的缺点进行修正得到tanh激活函数。具体表达式为

数学图像如下图所示。
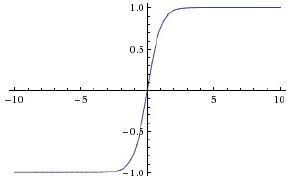
它将实数值压缩到[-1,1]之间。和sigmoid神经元一样,它也存在饱和问题,但是和sigmoid神经元不同的是,它的输出是零中心的。因此,在实际操作中,tanh非线性函数比sigmoid非线性函数更受欢迎。注意tanh神经元是一个简单放大的sigmoid神经元,具体说来就是:
![]()
但不足的是,tanh函数仍未解决梯度消失问题。
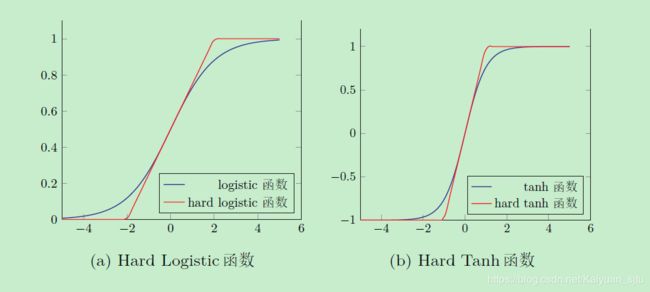
Hard-Logistic和Hard-Tanh函数
三、ReLU激活函数
ReLu函数的全称为Rectified Linear Units,函数表达式为y=max(0,x)。数学图像如下图所示。
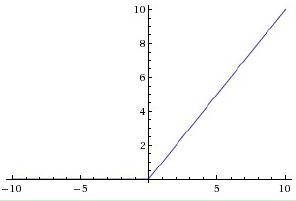
ReLU在今年非常流行。
- 优点:相较于sigmoid和tanh函数,ReLU对于随机梯度下降的收敛有巨大的加速作用。在一定程度上缓解了神经网络的梯度消失问题。
- 优点:sigmoid和tanh神经元含有指数运算等耗费计算资源的操作,而ReLU可以简单地通过对一个矩阵进行阈值计算得到。
- 缺点:ReLU输出非零中心化
- 缺点:在训练的时候,ReLU单元比较脆弱并且可能“死掉”。举例来说,当一个很大的梯度流过ReLU的神经元的时候,可能会导致梯度更新到一种特别的状态,在这种状态下神经元将无法被其他任何数据点再次激活。如果这种情况发生,那么从此所以流过这个神经元的梯度将都变成0。也就是说,这个ReLU单元在训练中将不可逆转的死亡,因为这导致了数据多样化的丢失。例如,如果学习率设置得太高,可能会发现网络中40%的神经元都会死掉(在整个训练集中这些神经元都不会被激活)。通过合理设置学习率,这种情况的发生概率会降低。
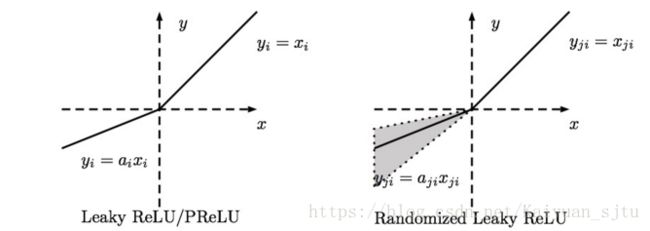
四、Leaky ReLU
Leaky ReLU是为解决“ReLU死亡”问题的尝试。ReLU中当x<0时,函数值为0。而Leaky ReLU则是给
出一个很小的负数梯度值,比如0.01。其函数表达式为:
其中gamma为一个很小的常量。
五、Maxout激活函数
Maxout是对ReLU和leaky ReLU的一般化归纳,它的数学表达式为:![]()
这样Maxout神经元就拥有ReLU单元的所有优点(线性操作和不饱和),而没有它的缺点(死亡的ReLU单元)。然而和ReLU对比,它每个神经元的参数数量增加了一倍,这就导致整体参数的数量激增。
六、ELU激活函数
ELU函数的全称是EXPONENTIAL LINEAR UNITS,其数学表示式如下:
其中α是一个可调整的参数,它控制着ELU负值部分在何时饱和。
在论文(FAST AND ACCURATE DEEP NETWORK LEARNING BY EXPONENTIAL LINEAR UNITS (ELUS))中给出四种激活函数(ELU,LReLU,ReLU,SReLU)比较图如下
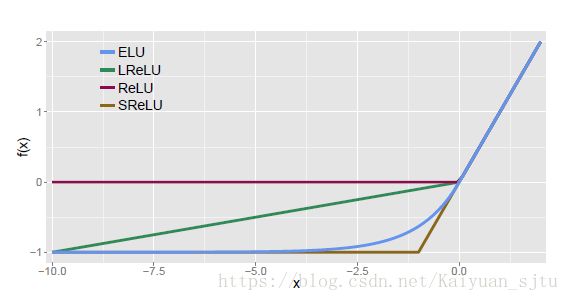
ELU通过在正值区间取输入x本身减轻了梯度弥散问题(x>0区间导数处处为1),这一点特性这四种激活函数都具备。四者当中只有ReLU的输出值没有负值,所以输出的均值会大于0,当激活值的均值非0时,就会对下一层造成一个bias,如果激活值之间不会相互抵消(即均值非0),会导致下一层的激活单元有bias shift。如此叠加,单元越多时,bias shift就会越大。相比ReLU,ELU可以取到负值,这让单元激活均值可以更接近0,类似于Batch Normalization的效果但是只需要更低的计算复杂度。虽然LReLU和PReLU都也有负值,但是它们不保证在不激活状态下(就是在输入为负的状态下)对噪声鲁棒。反观ELU在输入取较小值时具有软饱和的特性,提升了对噪声的鲁棒性。
简而言之,ELU具有以下的优点:
1、将前面单元输入的激活值均值控制在0
2、让激活函数的负值部分也可以被使用了(这意思应该是之前的激活函数,负值部分几乎不携带信息,特别是ReLU)
小结
总结了那么多常用的激活函数,那么到底在实际应用中该选择哪一个呢?
用ReLU非线性函数。注意设置好学习率,或许可以监控你的网络中死亡的神经元占的比例。如果单元死亡问题困扰你,就试试Leaky ReLU或者Maxout,不要再用sigmoid了。也可以试试tanh,但是其效果应该不如ReLU或者Maxout。总有一款适合你!
以上~
2018.05.30