大数据在线分析处理和常用工具
大数据在线分析处理的特点
- . 数据源源不断的到来;
- 数据需要尽快的得到处理,不能产生积压;
- 处理之后的数据量依然巨大,仍然后TB级甚至PB级的数据量;
- 处理的结果能够尽快的展现;
以上四个特点可以总结为数据的收集->数据的传输->数据的处理->数据的展现。其中数据的处理一般涉及数据的聚合,数据的处理和展现能够在秒级或者毫秒级得到响应。
针对这些问题目前形成了 Flume + kafka + Storm / Spark + Hbase / Redis 的技术架构
Flume介绍
Flume 专注于大数据的收集和传输,用来解决在线分析处理特点,数据源源不断的到来的问题。类似的大数据开源系统有 Logstash 和 Fluentd 。
三者区别如下:
- Logstash 主要 和 Elasticsearch 、 Kibana 结合使用,俗称 ELK 框架; Logstash 主要负责将数据源的数据转换成 Elasticsearch 认识的索引结构供 Kibana 查询
- Fluentd 当前的使用者已经很少,逐渐被功能更强大的 Flume 代替了
- Flume 能够支持多种数据源并且输出到多种输出源,并且支持多种格式的数据
架构图

架构图中 Source 用来连接输出源,Sink 用来连接输出源,Channel 是 Flume 内部数据传输通道(主要包括 Memory Channel 和 File Channel)。
其中 Source 连接的输入源可以但不限于:
- Avro
- Thrift
- Exec(unix command output)
- JMS (Java Message Service)
- Kafka
- NetCat (可以使用 nc –lk port 测试)
- Syslog
- Custom
其中 Sink 连接的输出源可以但不限于:
- Hdfs
- Hive
- Avro
- Thrift
- File Roll
- Hbase
- ElasticSearch (提供的功能和 Logstash 一样,但是不如Logstash 丰富,大多数时候需要自己构造 ElasticSearch 文档和索引)
- Kafka
- Custom
Flume 也能多个 Agent 相连形成 Agent 链
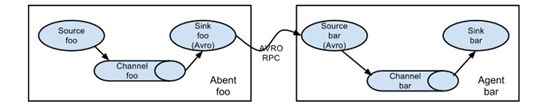
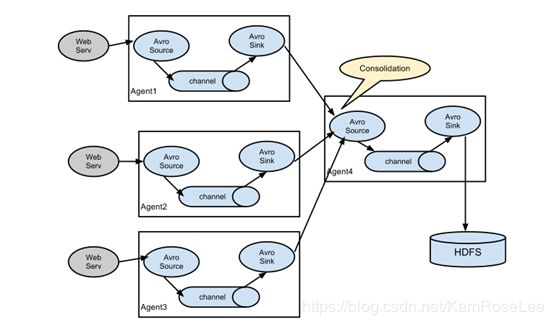
Flume 也能多个 Agent 进行数据源的合并
Spark 和 Storm 介绍
Spark (Spark Streaming) 和 Storm 专注于将数据按照时间窗口进行聚合和处理。用来解决在线分析处理特点,数据需要尽快的得到处理的问题。所以经常被称作流式处理框架。
两者的区别如下:
- Storm 提供比 Spark 更加实时的流式处理;
- Spark 提供比Storm更加多的服务,Spark 逐渐已经形成类似 Hadoop 的生态圈了。
目前Spark 生态圈包含的生态系统如下(而且还正在逐渐的壮大中):
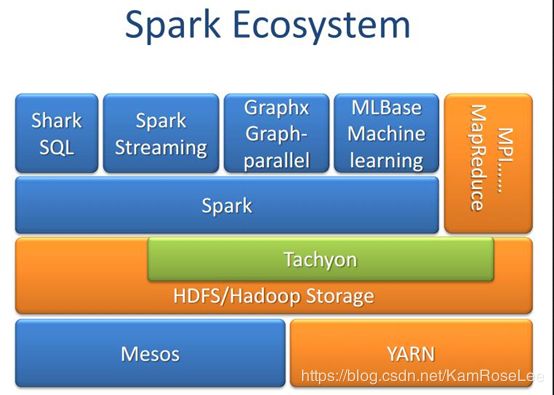
目前 Spark 有三种集群管理模式:
- Standalone:一种简单的集群管理,其包括一个很容易搭建集群的Spark;
- Apache Mesos :一种通用的集群管理,可以运行Hadoop MapReduce和服务应用的模式;
- Hadoop YARN : Hadoop2.0中的资源管理模式。
其中第二种和第三种都是使用 Spark 做任务管理和调度,Mesos 和 Yarn 做资源管理和调度
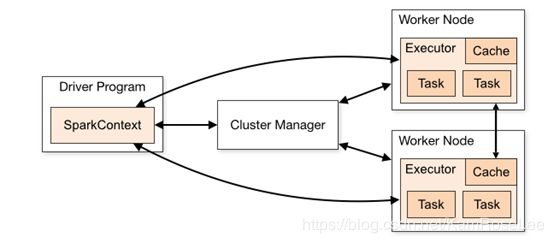
Spark 工作组件
Strom 结构图
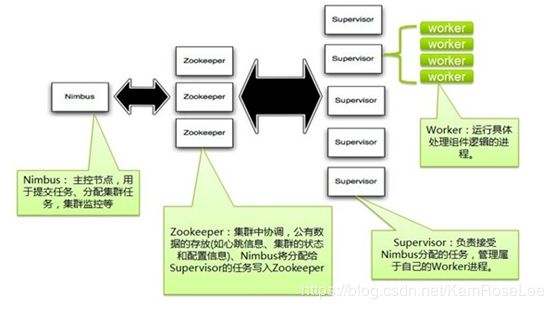
Storm 的工作组件:
- topology:一个拓扑是一个个计算节点组成的图,每个节点包换处理的逻辑,节点之间的连线表示数据流动的方向;
- spout:表示一个流的源头,产生tuple;
- bolt: 处理输入流并产生多个输出流,可以做简单的数据转换计算,复杂的流处理一般需要经过多个bolt进行处理。
Strom 拓扑topology的组成


HBase介绍
HBase 专注于大数据存储和提供查询,用来解决在线分析处理特点,数据经过处理后数据量依然巨大的存储和展现问题。类似的大数据开源系统有 Cassandra 。
两者区别如下:
- Cassandra 满足可用性和分区容忍性,允许数据的不一致(不同客户端可能看到不一样的情况)、 Cassandra 提供了类似 SQL 的 CQL 查询语言,查询方便;
- HBase 满足一致性和分区容忍性,拥有强大的记录集一致性。HBase不支持 SQL 需要使用者部署第三方服务来支持 SQL (如 Apache Phoenix);
架构图
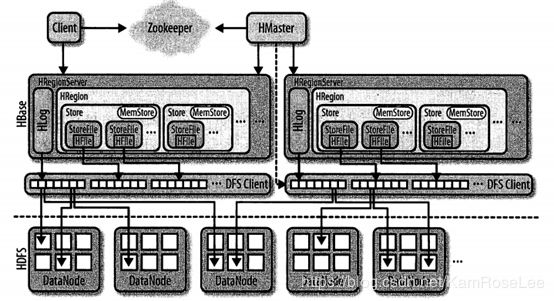
组成部件说明:
- Client:使用HBase RPC机制与HMaster和HRegionServer进行通信;
- Zookeeper: 存储hbase:meta 表等元数据信息;HRegionServer把自己以Emphedral方式注册到Zookeeper中,HMaster随时感知各个HRegionServer的健康状况;Zookeeper避免HMaster单点问题;
- HMaster: 主要负责Table和Region的管理工作:
管理用户对表的增删改查操作
管理HRegionServer的负载均衡,调整Region分布
Region Split后,负责新Region的分布
在HRegionServer停机后,负责失效HRegionServer上Region迁移
- HRegionServer:HBase中最核心的模块,主要负责响应用户I/O请求,向HDFS文件系统中读写数据:
HRegionServer管理一些列HRegion对象;
每个HRegion对应Table中一个Region,HRegion由多个HStore组成;
每个HStore对应Table中一个Column Family的存储;
客户端写数据过程图

Region的 Split 和 StoreFile 的 Compact:
Client写入 -> 存入MemStore,一直到MemStore满 -> Flush成一个StoreFile,直至增长到一定阈值 -> 触发Compact合并操作 -> 多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除 -> 当StoreFiles Compact后,逐步形成越来越大的StoreFile -> 单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split成2个Region,Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer 上,使得原先1个Region的压力得以分流到2个Region上。
由此过程可知,HBase只是增加数据,有所得更新和删除操作,都是在Compact阶段做的,所以,用户写操作只需要进入到内存即可立即返回,从而保证I/O高性能;
大数据离线处理和常用工具
大数据离线处理特点
- 数据量巨大且保存时间长;
- 在大量数据上进行复杂的批量运算;
- 数据在计算之前已经完全到位,不会发生变化;
- 能够方便的查询批量计算的结果;
不像在线计算当前呈现的各种框架和架构,离线处理目前技术上已经成熟,大家使用的均是: 使用 Hdfs 存储数据,使用 MapReduce 做批量计算,计算完成的数据如需数据仓库的存储,直接存入 Hive , 然后从Hive 进行展现。
Hdfs 介绍
Hdfs 是一种分布式文件系统,和任何文件系统一样 Hdfs 提供文件的读取,写入,删除等操作。Hdfs 是能够很好的解决离线处理中需要存储大量数据的要求。Hdfs和本地文件系统的区别如下:
- Hdfs 不支持随机读写;
- Hdfs 是分布式文件系统,支持数据多备份;
Hdfs 多备份数据存放策略: 第一个副本放在和client所在的node里(如果client不在集群范围内,则这第一个node是随机选取的,当然系统会尝试不选择哪些太满或者太忙的node);第二个副本放置在与第一个节点不同的机架中的node中(随机选择);第三个副本和第二个在同一个机架,随机放在不同的node中。如果还有更多的副本就随机放在集群的node里。
架构图

客户端读取数据流程图

客户端写入数据流程图

MapReduce 介绍
MapReduce 是一种分布式批量计算框架,分为 Map 阶段和 Reduce 阶段。 MapReduce 能够很好的解决离线处理中需要进行大量计算的要求。 MapReduce 从出现到现在经历了第一代 MapReduce v1 和 第二代 MapReduce Yarn。
Yarn 框架相对于老的 MapReduce 框架有以下优势:
- 减小了 JobTracker的资源消耗,之前JobTracker 既负责资源分配,也负责任务监控,Yarn 将这两项任务分别交给了 ResourceManager 和 ApplicationMaster ,减少了之前 JobTracker 单点失败的风险;
- MRv1 将资源分别 Map slot 和 Reduce slot 而且相互之前不能使用,Yarn将资源分别CPU、内存,相互之前能够通用,更加灵活也更加合理;
架构图

Yarn 框架各个组件的功能:
- ResourceManager: 负责资源的调度,由两个组件组成: 调度器和应用管理 ApplicationsManager (ASM) ;
- ApplicationsManager (ASM) :主要用于管理AM;
- ApplicationMaster (AM) :主要用于管理其对应的应用程序,如MapReduce作业,DAG作业等;
- NodeManager (NM):主要用于管理某个节点上的task和资源;
- Container :容器中封装了机器资源,如内存,CPU, 磁盘,网络等,每个任务会被分配一个容器,该任务只能在该容器中执行,并使用该容器封装的资源
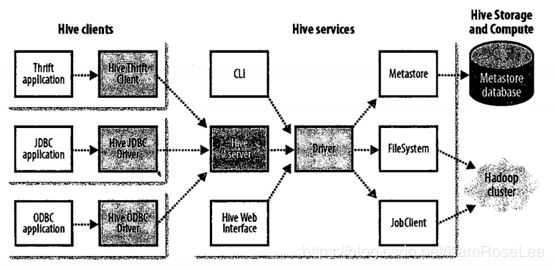
Hive 介绍
Hive 是一种数据仓库,Hive 中的数据存储于文件系统( 大部分使用 Hdfs),Hive 提供了方便的访问数据仓库中数据的 HQL 方法,该方法将 SQL 翻译成MapReduce。 能够很好的解决离线处理中需要对批量处理结果的查询。
Hive 将元数据存放在 metastore 中, Hive 的 metastore 有三种工作方式:
- 内嵌Derby方式: 在同一时间只能有一个进程连接使用数据库;
- Local方式 : 使用本地 Mysql 数据库存储元数据;
- Remote方式: 使用远程已经搭建完成的 Mysql 数据库存储元数据;
架构图
OLAP 和 OLTP处理和常用工具
OLAP 和 OLTP 特点
OLAP (联机分析处理) 和 OLTP (联机事务处理) 在查询方面的特点:
- OLTP 单次查询返回数据量小,但是经常会涉及服务器端简单的聚合操作,要求查询响应速度快,一般应用于在线处理;
- OLAP 单次查询返回数据量巨大,服务器端进行的处理复杂,经常包含上卷(从细粒度数据向高层的聚合)、下钻(将汇总数据拆分到更细节的数据)类似的操作;
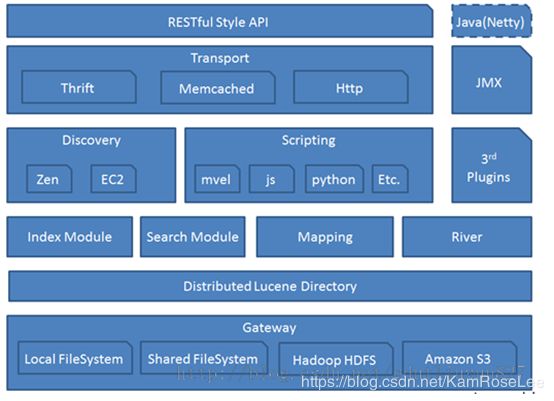
Elasticsearch 介绍
Elasticsearch 是一种基于 文档 的 底层使用 Lucene 进行检索的分布式NoSql 集群。Elasticsearch 检索大量文档类数据响应速度很快,更够为 在线 OLTP 提供支持。类似的大数据开源系统有 Solr。
两者的区别如下
- Elasticsearch是分布式的。不需要其他组件,分发是实时的,被叫做”Push replication” 并且完全支持 Apache Lucene 的接近实时的搜索;
- 建立索引时,搜索效率下降,实时索引搜索效率不高;
- 随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却不会有明显变化
所以, Solr的架构不适合实时搜索的应用,也就不适合 OLTP 处理
架构图
Impala 介绍
Impala 是 Cloudera 公司主导开发的新型查询系统,它提供 SQL 语义,能查询存储在 Hadoop 的 Hdfs 和 Hbase 中的 PB 级大数据。已有 的 Hive 系统虽然也提供了 SQL 语义,但由于 Hive 底层执行使用的是 MapReduce 引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之 下,Impala 的最大特点就是它的快速。
所以, Impala 使得在 TB 甚至 PB 级数据上进行 OLTP 分析成为可能。
架构图
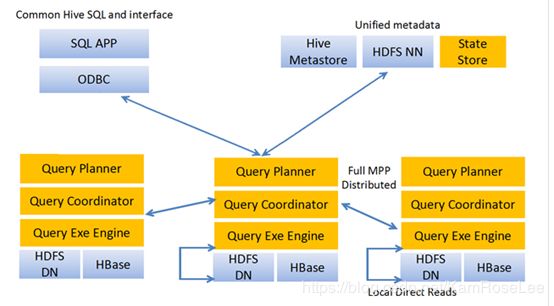
Impala 主要通过以下两种技术实现快速查询大量数据:
- 实现了嵌套型数据的列存储;
- 使用了多层查询树,使得任务可以在数千个节点上并行执行和聚合结果;
列存储可以减少查询时处理的数据量,有效提升 查询效率。多层查询树则借鉴了分布式搜索引擎的设计,查询树的根节点负责接收查询,并将查询分发到下一层节点,底层节点负责具体的数据读取和查询执行,然后将结果返回上层节点。
Kylin 介绍
Kylin 是由国人作为主要贡献者的一个旨在对 Hadoop 环境下分析流程进行加速、且能够与 SQL 兼容性工具顺利协作的解决方案,目前 Kylin 已经成功将SQL接口与多维分析机制(OLAP)引入 Hadoop,旨在对规模极为庞大的数据集加以支持。
Kylin 能够在大数据分析领域实现以下各项特性:
- 规模化环境下的极速 OLAP 引擎: 削减 Hadoop 环境中处理超过百亿行数据时的查询延迟时间;
- Hadoop上的 ANSI SQL 接口: Kylin 能够在 Hadoop 之上提供 ANSI SQL 并支持大部分 ANSI SQL查询功能;
- 利用 OLAP cube(立方体)对数百亿行数据进行查询;
架构图

Kylin 的大体设计思路:
- 从Hive当中读取数据(这些数据被保存在HDFS之上);
- 运行Map Reduce任务以实现预计算 ;
- 将cuba数据保存在HBase当中
- 利用Zookeeper进行任务协调