在Pandas中像写SQL一样做数据分析
在python中可以使用pandas包来进行类似SQL的数据查询,这篇文章就给出一些用pandas去做类似SQL的操作的例子。首先导入numpy和pandas包。
import numpy as np
import pandas as pd本文使用tips数据集用来讲解类似SQL操作的例子,首先导入以DataFrame的形式的tips数据集
url = 'https://raw.github.com/pandas-dev/pandas/master/pandas/tests/data/tips.csv'
tips = pd.read_csv(url)可以使用head()来展示数据集中的前5列数据
tips.head()
print(tips.head())可以得到如下结果:

这里就取出了tips数据集中的前五行数据。
同样可以使用tail()来展示数据集中的后面5列数据
tips.tail()
print(tips.tail())运行结果如下:

下面举例说明几种常见的SQL操作以及相对应的pandas中的操作。
(1)pandas的select操作:在SQL中,如果我们要从tips中选取前五行total_bill, tip, smoker和time几列数据,SQL的语法为:
select total_bill, tip, smoker, time
from tips
limit 5在pandas操作中,这几列数据可以通过在DataFrame中写出要选取的列,语法如下:
tips[['total_bill', 'tip', 'smoker', 'time']].head(5)
print(tips[['total_bill', 'tip', 'smoker', 'time']].head(5))运行结果如下:
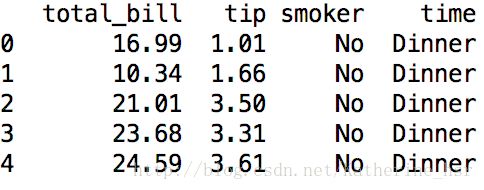
如果要选取所有的列,就不需要在DataFrame中填写参数,就像SQL的select *操作
2)pandas中的where操作:在SQL中,where操作语法为:
select * from tips where time = 'dinner' limit 5pandas语法如下:
tips[tips['time'] == 'Dinner'].head(5)
print(tips[tips['time'] == 'Dinner'].head(5))运行结果如下:

如果我们想知道tips数据集中有多少条数据是符合我们所要查找数据要求的,可以用如下操作:
is_dinner = tips['time'] == 'Dinner'
is_dinner.value_counts()运行结果如下:
True 176
False 68
Name: time, dtype: int64
从输出结果中可以看出有176条数据满足time是Dinner的条件,有68条数据不满足该条件
select操作也可以写为:
tips[is_dinner].head()(3) pandas中的and和or操作:现在如果要查找time为Dinner并且tip大于5的数据,SQL语法为:
select * from tips where time = 'Dinner' and tip > 5在pandas中的相对应的语法为:
tips[(tips['time'] == 'Dinner') & (tips['tip'] > 5)]or可以在pandas对应为|,例子如下:
tips[(tips['time'] == 'Dinner') | (tips['tip'] > 5)](4)查找空值:pandas中查找是否为空值可以用 notna()和isna() ,frame数据集如下
frame = pd.DataFrame({'col1': ['A', 'B', np.NaN, 'C', 'D'], 'col2': ['F', np.NaN, 'G', 'H', 'I']})如果要在数据集中的满足col2为空的数据,SQL语法为:
select * frame where col2 is null对应的pandas语法为:
frame[frame['col2'].isna()](5)group by操作:在pandas中可以用groupby()方法来实现group by操作
例如,以性别来分组查找各分组的数量,SQL语法为:
select sex, count(*) from tips group by sex对应的pandas语法为:
tips.groupby('sex').size()运行结果如下:
sex
Female 87
Male 157
dtype: int64
这里面我们使用size()方法来计数而没有使用count()方法,因为size()方法会返回所有的数量,而count()方法的返回值为每一个列的不为空的数量
tips.groupby('sex').count()运行结果如下:
total_bill tip smoker day time size
sex
Female 87 87 87 87 87 87
Male 157 157 157 157 157 157
可以使用count()方法来计算某一列的数量,例子如下:
tips.groupby('sex')['total_bill'].count()运行结果如下:
sex
Female 87
Male 157
Name: total_bill, dtype: int64
以day来分组,计算tip的数量和平均值,SQL可以写为:
select day, avg(tip), count(*) from tips group by day对应的pandas可以使用agg()方法来实现多种多个方法,语法如下:
tips.groupby('day').agg({'tip': np.mean, 'day': np.size})运行结果如下:
day tip
day
Fri 19 2.734737
Sat 87 2.993103
Sun 76 3.255132
Thur 62 2.771452
要实现多个属性的分组,SQL可以写为:
select smoker, day, avg(tip), count(*) from tips group by smoker, daypandas中可以写为:
tips.groupby(['smoker', 'day']).agg({'tip': [np.size, np.mean]})运行结果如下:
tip
size mean
smoker day
No Fri 4.0 2.812500
Sat 45.0 3.102889
Sun 57.0 3.167895
Thur 45.0 2.673778
Yes Fri 15.0 2.714000
Sat 42.0 2.875476
Sun 19.0 3.516842
Thur 17.0 3.030000
(6)join操作:在pandas中join操作可以通过join()或merge()方法来实现,默认的join()方法会根据索引进行联结。
inner join,SQL语法如下:
select * from df1 inner join df2 on df1.key = df2.key对应的pandas操作如下:
pd.merge(df1, df2, on='key')运行结果如下:
key value_x value_y
0 B 0.562542 0.799541
1 D 0.757426 0.687838
2 D 0.757426 0.746944
merge()方法也可以用来用一个Dataframe的索引join另一个Dataframe的列
indexed_df2 = df2.set_index('key')
pd.merge(df1, indexed_df2, left_on='key', right_index=True)left outer join,展示所有的df1,SQL操作如下:
select * from df1 left outer join df2 on df1.key = df2.key对应的pandas操作为:
pd.merge(df1, df2, on='key', how='left')运行结果如下:
key value_x value_y
0 A 0.198997 NaN
1 B 0.562542 0.799541
2 C 0.125744 NaN
3 D 0.757426 0.687838
4 D 0.757426 0.746944
right outer join,展示所有的df2,SQL操作如下:
select * from df1 right outer join df2 on df1.key = df2.key对应的pandas操作为:
pd.merge(df1, df2, on='key', how='right')运行结果如下:
key value_x value_y
0 B 0.562542 0.799541
1 D 0.757426 0.687838
2 D 0.757426 0.746944
full join,展示所有的df1,df2数据,SQL操作如下:
select * from df1 full outer join de2 on df1.key = df2.key对应的pandas操作为:
pd.merge(df1, df2, on='key', how='outer')运行结果如下:
key value_x value_y
0 A 0.198997 NaN
1 B 0.562542 0.799541
2 C 0.125744 NaN
3 D 0.757426 0.687838
4 D 0.757426 0.746944
5 E NaN 0.169292
(7)union操作,在pandas中union all的操作可以通过concat()方法来完成
df1 = pd.DataFrame({'city': ['Chicago', 'San Francisco', 'New York City'], 'rank': range(1, 4)})
df2 = pd.DataFrame({'city': ['Chicago', 'Boston', 'Los Angeles'], 'rank': [1, 4, 5]})SQL操作如下
select * from df1 union all select * from df2pandas对应操作如下:
pd.concat([df1, df2])SQL中union与union all的区别为union会去除重复,在pandas中可以用drop_duplicates()来去除重复
pd.concat([df1, df2]).drop_duplicates()key value
0 A 0.198997
1 B 0.562542
2 C 0.125744
3 D 0.757426
0 B 0.799541
1 D 0.687838
2 D 0.746944
3 E 0.169292
(8)有偏移的前N行数据
SELECT * FROM tips
ORDER BY tip DESC
LIMIT 10 OFFSET 5;tips.nlargest(10+5, columns='tip').tail(10)运行结果如下:
total_bill tip sex smoker day time size
183 23.17 6.50 Male Yes Sun Dinner 4
214 28.17 6.50 Female Yes Sat Dinner 3
47 32.40 6.00 Male No Sun Dinner 4
239 29.03 5.92 Male No Sat Dinner 3
88 24.71 5.85 Male No Thur Lunch 2
181 23.33 5.65 Male Yes Sun Dinner 2
44 30.40 5.60 Male No Sun Dinner 4
52 34.81 5.20 Female No Sun Dinner 4
85 34.83 5.17 Female No Thur Lunch 4
211 25.89 5.16 Male Yes Sat Dinner 4
(9) 每一组的第N行
SELECT * FROM (
SELECT
t.*,
ROW_NUMBER() OVER(PARTITION BY day ORDER BY total_bill DESC) AS rn
FROM tips t
)
WHERE rn < 3
ORDER BY day, rn;(tips.assign(rn=tips.sort_values(['total_bill'], ascending=False).groupby(['day']).cumcount()+1).query('rn < 3').sort_values(['day', 'rn'])
)运行结果如下:
total_bill tip sex smoker day time size rn
95 40.17 4.73 Male Yes Fri Dinner 4 1
90 28.97 3.00 Male Yes Fri Dinner 2 2
170 50.81 10.00 Male Yes Sat Dinner 3 1
212 48.33 9.00 Male No Sat Dinner 4 2
156 48.17 5.00 Male No Sun Dinner 6 1
182 45.35 3.50 Male Yes Sun Dinner 3 2
197 43.11 5.00 Female Yes Thur Lunch 4 1
142 41.19 5.00 Male No Thur Lunch 5 2
使用rank()方法同样能达到相同的效果
SELECT * FROM (
SELECT
t.*,
RANK() OVER(PARTITION BY sex ORDER BY tip) AS rnk
FROM tips t
WHERE tip < 2
)
WHERE rnk < 3
ORDER BY sex, rnk;tips.assign(rnk=tips.groupby(['day'])['total_bill'].rank(method='first', ascending=False)).query('rnk < 3').sort_values(['day', 'rnk'])
)(10)update 方法
UPDATE tips
SET tip = tip*2
WHERE tip < 2;tips.loc[tips['tip'] < 2, 'tip'] *= 2(11)delete方法
DELETE FROM tips
WHERE tip > 9;在pandas中,我们需要选择留下来的列而不是去删除不需要的列
tips = tips.loc[tips['tip'] <= 9]