1.遗传算法之Matlab实现(1):从下载工具箱到实现,极详细,保证一看就会!!!
本文找了两个遗传算法的例子,分别是求一元函数和二元函数的最大值,用MATLAB进行了实现,以下是具体过程:
(1)下载遗传算法需要的工具箱,Genegic Algorithm Toolbox(GA工具箱)。下载方法:在百度中输入关键字“Genegic Algorithm 官网”,然后点击第二个(Genegic Algorithm Toolbox)网页进入后,点击Download即下载完毕,下载后的文件后面有。
(2)批量修改GA工具箱的文件后缀名。由于下载的GA工具箱文件后缀都为.M,会导致后面用不了里面的函数,所以需要修改文件后缀为.m。修改方法:
把一个文件格式转化为另外一种格式普遍方法为:在文件列表中新建一个txt文档,在里面输入ren *.(原文件后缀) *.(将要改的后缀),然后把txt改为bat即可。在这里要将M文件改为m文件,需要先以jpg为铺垫,先把M改为jpg,再将jpg修改为m。具体方法如下:先新建一个txt文档。在里面输入ren *.M *.jpg,然后点击保存后修改该txt后缀为bat,点确定可以看到M文件全变为jpg文件。再新建一个txt文件,输入ren *.jpg *.m,然后点击保存后修改该txt后缀为bat,点确定可以看到jpg文件全变为m文件。
(3)添加工具箱到matlab中。先把工具箱文件夹gatbx复制到matlab安装路径下的toolbox文件夹中(也可以省略此步找到路径直接添加也可),然后在MATLAB中点击File-Set path-Add with Subfolders,找到gatbx文件夹的路径-save即可。
(4)检验工具箱添加是否成功。在MATLAB命令行输入help reins(可随意输入GA工具箱中任意的一个函数检验),出现该函数的用法说明等则表示添加成功,若没有添加成功会提示not found。,
(5)遗传算法一元函数MATLAB实现。
实例:用遗传算法求函数f(x)=x*cos(5*pi*x)+3.5在区间[-1,2.5]上的最大值。(注:pi表示π)
先在工作区建立上面函数的一个m文件输入以下代码并保存,保存M文件时默认为函数名命名,所以不需要修改文件名,同时注意M文件的保存路径要与当前的工作空间保持一致,不然在运行命令文件时会找不到该函数,导致出错。
function y=fun_sigv(x)
y=x.*cos(5*pi*x)+3.5;然后在命令行输入以下代码运行即可:
opt_minmax=1; %目标优化类型:1最大化、0最小化
num_ppu=50; %种群规模即个体个数 初始种群的大小一般是20-100,这里选择的是50个
num_gen=60; %最大遗传代数
len_ch=20; %基因长度
gap=0.9; %代沟(Generation gap) 代沟是父代中需要经过选择、交叉、变异得到下一代的比例,例如父代有100个个体,代沟为0.9表示有90个个体被选中进行上述一系列操作进化到下一代,剩下10%个不变直接进入下一代,即下一代还是100个个体
sub=-1; %变量取值下限
up=2.5; %变量取值上限 由题目中变量的取值区间可以知道
cd_gray=1; %是否选择格雷码编码方式:1是、0否 格雷码属于可靠性编码,是一种错误最小化的编码方式,它相比自然二进制码减少了出错的可能性。
sc_log=0; %是否选择对数标度:1是、0否 对数标度坐标x-logy 算数标度坐标x-y 增长方式不同,一个均匀增长,一个对数增长
trace=zeros(num_gen,2); %遗传迭代性能跟踪器 trace是代数*2的二维矩阵,存储各子代种群的最优解和各子代种群的平均值
fieldd=[len_ch;sub;up;1-cd_gray;sc_log;1;1]; %区域描述器 有的书中叫译码矩阵,矩阵第一行表示每一个个体的染色体的基因数目,最后两行分别表示包不包含上下边界,0不包含,1包含。fieldd是区域描述器,有的书中也叫译码矩阵。其结构为
FieldD=[len,lb,ub,code,scale,lbin,ubin]';('代表转置,也就是FieldD是列向量)
len是每个chrom的长度,lb和ub是行向量,分别指明每个变量使用的下界和上界。 code是二进制行向量,code(i)=1为标准二进制编码,code(i)=0为格雷码。
scale是二进制行向量,指明每个子串是否使用对数或算数刻度。0为算数刻度,1为对数刻度。
lbin和ubin是二进制行向量,指明表示范围中是否包含每个边界。选择lbin=0或ubin=0,从表示范围中去掉边界;lbin=0或ubin=1则表示包含边界。
fieldd在二进制串到实值转换函数bs2rv中用到:Phen=bs2rv(Chrom,FieldD),即根据译码矩阵FieldD将二进制串矩阵Chrom转换为实值向量。返回矩阵Phen包含对应的种群表现型。对于bs2rv函数,如果使用对数刻度,其范围不能包含零
chrom=crtbp(num_ppu,len_ch); %初始化生成种群
k_gen=0;
x=bs2rv(chrom,fieldd); %翻译初始化种群为10进制 二进制转化为十进制
fun_v=fun_sigv(x); %计算目标函数值
tx=sub:.01:up; % 约束条件,即变量取值范围在[-1.2.5]区间内
plot(tx,fun_sigv(tx)); %画出函数的优化结果的二维图形
xlabel('x');ylabel('y'); %标出x轴为自变量x,y轴为因变量y
title('一元函数优化结果'); %图形标题
hold on;
while k_gen上面的代码注释有的是我自己的解释,如果有错欢迎指正。直接可以运行无错的代码如下:
opt_minmax=1; %目标优化类型:1最大化、0最小化
num_ppu=50; %种群规模即个体个数
num_gen=60; %最大遗传代数
len_ch=20; %基因长度
gap=0.9; %代沟(Generation gap)
sub=-1; %变量取值下限
up=2.5; %变量取值上限
cd_gray=1; %是否选择格雷码编码方式:1是、0否
sc_log=0; %是否选择对数标度:1是、0否
trace=zeros(num_gen,2); %遗传迭代性能跟踪器
fieldd=[len_ch;sub;up;1-cd_gray;sc_log;1;1]; %区域描述器
chrom=crtbp(num_ppu,len_ch); %初始化生成种群
k_gen=0;
x=bs2rv(chrom,fieldd); %翻译初始化种群为10进制
fun_v=fun_sigv(x); %计算目标函数值
tx=sub:.01:up;
plot(tx,fun_sigv(tx));
xlabel('x');ylabel('y');
title('一元函数优化结果');
hold on;
while k_gen运行结果图如下:
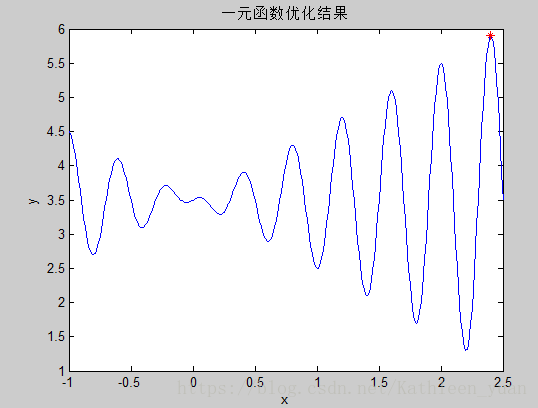
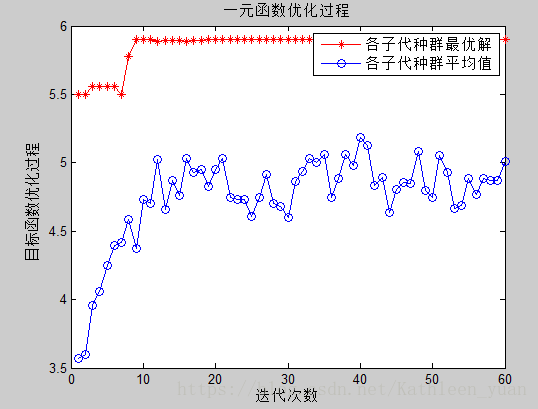
从图一可以看出从[-1,2.5]每个x对应的优化结果y,从而清晰地看出最优值;图二是用跟踪器记载了优化的过程,随着迭代次数的增加,最优值最后趋于一个稳定的值5.9008。
(6)遗传算法二元函数MATLAB实现。
求解下列二元函数的最大值:

直接在matlab命令行输入以下代码:
clc;clear all;
format long;%设定数据显示格式
%初始化参数
T=10;%仿真代数
N=4;% 群体规模
pm=0.05;pc=0.8;%交叉变异概率
umax=7;umin=1;%参数取值范围
L=3;%单个参数字串长度,总编码长度2L
bval=round(rand(N,2*L));%初始种群
bestv=-inf;%最优适应度初值
%迭代开始
for ii=1:T
%解码,计算适应度
for i=1:N
y1=0;y2=0;
for j=1:1:L
y1=y1+bval(i,L-j+1)*2^(j-1);
end
x1=(umax-umin)*y1/(2^L-1)+umin;
for j=1:1:L
y2=y2+bval(i,2*L-j+1)*2^(j-1);
end
x2=(umax-umin)*y2/(2^L-1)+umin;
obj(i)=x1.^2+x2.^2; %目标函数
xx(i,:)=[x1,x2];
end
func=obj;%目标函数转换为适应度函数
p=func./sum(func);
q=cumsum(p);%累加
[fmax,indmax]=max(func);%求当代最佳个体
if fmax>=bestv
bestv=fmax;%到目前为止最优适应度值
bvalxx=bval(indmax,:);%到目前为止最佳位串
optxx=xx(indmax,:);%到目前为止最优参数
end
Bfit1(ii)=bestv; % 存储每代的最优适应度
%%%%遗传操作开始
%轮盘赌选择
for i=1:(N-1)
r=rand;
tmp=find(r<=q);
newbval(i,:)=bval(tmp(1),:);
end
newbval(N,:)=bvalxx;%最优保留
bval=newbval;
%单点交叉
for i=1:2:(N-1)
cc=rand;
if cc注意:不是全部复制粘贴,分三步运行上面的空格就是分段处。最终结果如下:
bestv =
98
optxx =
7 7

上图中x轴为迭代次数,y轴为最优值。