《数据结构》复习之线性表(顺序表和链表)
- 线性表的概念
- 线性表的比较
- 线性表的数据结构
- 顺序表的算法操作
- 双链表的补充
- 总结
1.线性表的概念
线性表的存储结构有顺序存储结构和链式存储结构两种。前者成为顺序表,后者称为链表。
- 顺序表:
顺序表就是把线性表中的所有元素按照其逻辑顺序,一次存储到从指定的存储 位置开始的一块连续的存储空间中,如下图所示。

- 链表
在链表的存储中,每一个节点不仅包含所存元素本身的信息,还包含元素之间的逻辑关系的信息,即前驱节点包含后继节点的地址信息,这样就可以通过前驱节点中的地址信息方便地找到后继节点的位置,如下图所示。

本文中以单链表为例。
2.线性表的比较
顺序表和链表各自有各自的优点和缺点,可以用下表表示:
| 比较类别 | 顺序表 | 链表 |
|---|---|---|
| 存储分配 | 静态分配 | 动态分配 |
| 存取方式 | 随机存取 | 顺序存取 |
| 插入删除时移动元素的个数 | 需要移动近一半的元素 | 不需要移动元素,只需修改指针 |
由此可见,当需要随机存取的时候,适合使用顺序表;当需要做频繁插入删除操作时,适合使用链表。
3.线性表的数据结构
- 顺序表
typedef struct
{
T data[maxSize];
int length;
}Sqlist;结构体中包括一个存储表元素数组data[]和指示元素个数的变量length。(其实顺序表就是数组)。
- 链表
单链表的节点定义:
template<class T>
struct Node
{
T value;
struct Node* next;
};4.顺序表的算法操作
- 顺序表的算法操作:
下面是我写的比较中重要的顺序表的算法操作。
#define maxSize 1000
#include ::erase(int loc)
{
int i = 0;
T x = data[loc];
for (i = loc; i < length; i++) //对于临界点的数,可以试着把临界点带进去
{
data[i] = data[i + 1];
}
length--;
return x;
}
template<class T>
void Sqlist::insert(int loc, T value)
{
//for (int i = loc; i < length;i++) //这样写是有问题的
//{
// data[i + 1] = data[i]; //所有均向后移动
//}
int i = 0;
for (i = length-1; i >= loc;i--) //对于临界点的数,可以试着把临界点带进去
{
data[i + 1] = data[i];
}
data[loc] = value; //不要写成i
length++;
}
template<class T>
void Sqlist::push_back(T value)
{
data[length] = value;
length++;
}
template<class T>
void Sqlist::display()
{
for (int i = 0; i < length;i++)
{
cout << data[i] << " ";
}
cout << endl;
}
template<class T>
T Sqlist::at(int loc)
{
return data[loc];
}
int main()
{
int A[] = { 1, 2, 3, 4, 6, 7, 8, 9, 10 };
Sqlist<int> ve(A, 9);
ve.push_back(11);
ve.display(); //1 2 3 4 6 7 8 9 10 11
ve.insert(4, 5);
ve.display(); //1 2 3 4 5 6 7 8 9 10 11
ve.erase(2);
ve.display(); //1 2 4 5 6 7 8 9 10 11
// char A[] = { 'a', 'b', 'c', 'e', 'f','g', 'h' };
// Sqlist ve(A, 7);
// ve.push_back('i');
// ve.display(); //a b c e f g h i
// ve.insert(3, 'd');
// ve.display(); //a b c d e f g h i
// ve.erase(2);
// ve.display(); //a b d e f g h i
return 0;
}
顺序表中比较难的是插入(insert)和删除(erase)操作。再插入的过程中,要注意从最后一个元素开始至插入位置的元素,每一个元素向后移动一个单位,而不能从插入位置的元素向后移,因为这样后面的元素将被覆盖。而在删除操作时,需要从删除元素的后一个元素开始往前面移动一个单位一直移动到最后一个元素。
- 单链表
下面是我写的单链表的操作。
#include * list;
public:
MyList()
{
list = new struct Node;
list->next = NULL;
}
void CreateListR(T a[], int n); //尾插法
void CreateListF(T a[], int n); //头插法
void display();
void insert(int loc, T x); //插入操作
int erase(T x); //删除操作
void inverse(); //逆置操作
void inversePrint(); //逆序打印
void recurPrint(struct Node* p); ///递归操作
};
template<class T>
void MyList::inversePrint()
{
recurPrint(list->next);
cout << endl;
}
template<class T>
void MyList::recurPrint(struct Node* p)
{
if (p!=NULL)
{
recurPrint(p->next);
cout << p->value << " ";
}
}
template<class T>
void MyList::inverse()
{
struct Node *p = list->next;
list->next = NULL;
struct Node *q;
while (p != NULL)
{
q = p;
p = p->next;
q->next = list->next; //头插法
list->next = q;
}
}
template<class T>
int MyList::erase(T x)
{
//struct Node *p = list->next;
//struct Node *q = list; //删除的时候要知道删除节点的前一个节点
//while (p != NULL)
//{
// if (p->value==x)
// {
// break;
// }
// p = p->next;
// q = q->next;
//}
//if (p == NULL)
//{
// return -1;//没有这样的节点无法删除
//}
//else
//{
//q->next = p->next; //删除操作
//delete p;
//return 1;
//}
//另一种方法
struct Node *p = list;
while (p->next != NULL)
{
if (p->next->value == x)
{
break;
}
p = p->next;
}
if (p == NULL)
{
return -1;
}
else
{
struct Node *tmp = p->next;
p->next = p->next->next;
delete tmp;
return 1;
}
}
template<class T>
void MyList::insert(int loc, T x)
{
struct Node *p = list; //注意插入的时候要找到插入节点的前一个节点
while (loc--) //找到对应的位置
{
p = p->next;
}
struct Node* tmp = new struct Node;
tmp->value = x;
//插入操作
tmp->next = p->next; //可以发现插入操作和头插法很像,其实头插法就是在头结点后面插入(邪恶了)。
p->next = tmp;
}
template<class T>
void MyList::display()
{
struct Node *p = list->next;
while (p != NULL)
{
cout << p->value << " ";
p = p->next; //不要忘记向后走
}
cout << endl;
}
template<class T>
void MyList::CreateListF(T a[], int n) //头插法
{
struct Node* p = list;
for (int i = 0; i < n; i++)
{
struct Node* tmp = new struct Node;
tmp->value = a[i];
tmp->next = p->next;
p->next = tmp;
/*
若没有头结点则为
tmp->next = list;
list = tmp;
*/
}
}
template<class T>
void MyList::CreateListR(T a[], int n) //尾插法
{
struct Node* p = list;
for (int i = 0; i < n; i++)
{
struct Node* tmp = new struct Node;
tmp->value = a[i];
tmp->next = NULL;
p->next = tmp; //尾插法要保证有一个指针永远指向最后一个节点
p = tmp;
}
p->next = NULL; //或许冗余
}
int main()
{
int A[5] = { 1, 2, 3, 4, 5 };
MyList<int> mylist1;
mylist1.CreateListF(A, 5);
mylist1.display(); //5 4 3 2 1
cout << "************************" << endl;
MyList<int> mylist2;
mylist2.CreateListR(A, 5);
mylist2.display(); //1 2 3 4 5
mylist2.insert(2, 10);
mylist2.display(); //1 2 10 3 4 5
mylist2.erase(4);
mylist2.display(); //1 2 10 3 5
mylist2.inverse();
mylist2.display(); // 5 3 10 2 1
mylist2.inversePrint(); //1 2 10 3 5
return 0;
}
这里写了两种创建链表的方法,头插法(CreateListF)和尾插法(CreateListR)。头插法是在头结点后面不断插入结点,因此头插法的实现与链表元素的插入相似tmp->next = p->next; p->next = tmp;。且头插法最后得到的链表元素顺序与插入元素顺序相反(逆置的时候可以用头插法)。尾插法需要有一个指针一直指向最后一个元素,每次在链表末尾插入元素p->next = tmp; p = p->next;。
此外链表比较重要的操作时插入(insert)和删除(erase)。两者的共同点是都要找到所需位置的前一个元素(插入要找到插入元素的前一个元素,删除要找到删除元素之前的元素),因此可以找一个临时指针进行跟踪。
插入的代码(s为插入的节点,p为插入位置之前的元素)是:s->next=p->next; p->next=s;(可以发现头插法和这个是一样的,因为都是插入操作,注意两句语句顺序不能颠倒)。示意图如下。
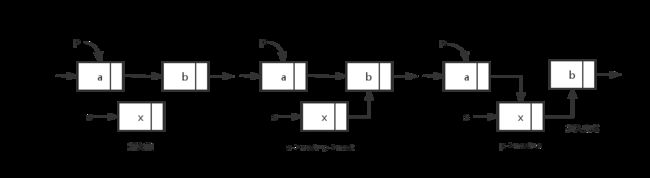
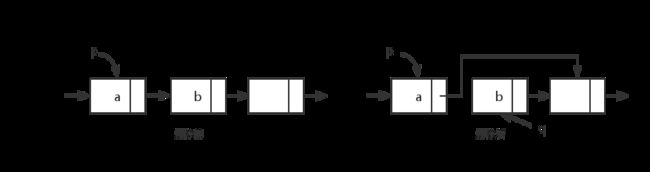
删除也比较简单。要将单链表的第i个结点删去,必须先在单链表中找到第i-1个结点。假设p为删除节点的前一个节点。则删除代码是q=p->next; p->next=p->next->next; free(p); 。 示意图如下:
这边我还写如何把链表逆置(inverse头插法)和将链表元素倒着输出(inversePrint利用递归)。
5.双链表的补充
补充一下双链表的插入节点和删除节点算法。
双链表节点的数据结构如下:
struct Node
{
T value;
struct Node* prior;
struct Node* next;
};假设在双链表中p所指的节点之后插入一个节点s,其操作语句如下:
s->next=p->next;
s->prior=p;
p->next=s;
s->next->prior=s; 其特点是,先将要插入的结点的两边链接好,这样就可以保证不会发生链断之后找不到阶段的情况。
设要删除双链表中p结点的后继结点。其操作语句如下:
q=p->next;
p->next=q->next;
q->next->prior=p;
free(q);6.总结
顺序表对应于数组,因此并不是特别难。由于大一时观念的灌输,总觉得链表较难,但现在发现其实并不是如此,最重要的是相信自己克服恐惧大胆的写。若遇到较难的题目,可以借助画图来帮助理解。也要勇于设置相应的辅助指针。