《软件构造》第3章复习摘要
总览:
第一部分(讲义3-1)
Java基本数据类型,例如:
int:范围[-2^31, 2^31]
long:范围[-2^63, 2^63]
boolean
double
char:单个字符
Java对象数据类型,例如:
String、BigInteger……
习惯上,基本数据类型都是小写字母,而对象数据类型以大写字母开头。
基本数据类型与对象数据类型的比较:

可以将基本类型包装为对象类型:如Boolean、Integer、Short、Long、Character、Float、Double。通常是在定义集合类型的时候使用它们。一般情况下,尽量避免使用。一般可以自动转换。
静态/动态类型检查:
静态类型检查:可在编译阶段发现错误,避免了将错误带入到运行阶段,可提高程序的正确性/健壮性。主要检查语法错误、类名/函数名错误、参数数目错误、参数类型错误、返回值类型错误,是关于“类型”的检查。
动态类型检查:主要检查非法的参数值、非法的返回值、越界、空指针,是关于“值”的检查。
Mutable/Immutable:
首先理解“改变一个变量”和“改变一个变量的值”(“引用的改变”和“值的改变”)的区别。
改变一个变量:将该变量指向另一个值的存储空间;
改变一个变量的值:将该变量当前指向的值的存储空间中写入一个新的值。
Immutable数据类型:一旦被创建,其值不能改变。
Immutable引用类型:一旦确定其指向的对象,不能再被改变。如果要使一个引用是Immutable,可以用final关键字来声明它。
如果编译器无法确定final变量不会改变,就提示错误,这也是静态类型检查的一部分。尽量使用final变量作为方法的输入参数,作为局部变量。final表明了程序员的一种“设计决策”。注意:final类无法派生子类,final变量无法改变值/引用,final方法无法被子类重写。
Immutable对象:一旦被创建,始终指向同一个值/引用,如String类型;
Mutable对象:拥有方法可以修改自己的值/引用,如StringBuilder类型。
Mutable类型的优点:使用Immutable类型,对其频繁修改会产生大量的临时拷贝(需要垃圾回收),Mutable类型最少化拷贝以提高效率,获得更好的性能,Mutable类型也适合于在多个模块之间共享数据。
而Immutable类型更“安全”,在其它质量指标上表现更好。
因此,使用Mutable类型还是Immutable类型,要在性能和安全上进行折中,看你看重哪个质量指标。
防御式拷贝:防止客户端修改全局Mutable类型变量。
通过防御式拷贝,给客户端返回一个全新的对象。大部分时候该拷贝不会被客户端修改,可能造成大量的内存浪费。如果使用Immutable类型,则节省了频繁复制的代价。
安全的使用Mutable类型:局部变量,不会涉及共享;只有一个引用。
如果有多个引用(别名),使用Mutable类型就非常不安全。
Snapshot diagram:用于描述程序运行时的内部状态。便于程序员之间的交流;便于刻画各类变量随时间变化;便于解释设计思路。
Immutable对象:用双线椭圆;
Mutable对象:用单线椭圆;
Immutable引用:用双线剪头;
Mutable引用:用单线剪头;
(Immutable引用指向的值可以是可变的,Mutable引用指向的值可以是不可变的)。
一些有用的Immutable类型:
基本类型及其封装对象类型都是不可变的;
不可修改的集合类unmodifiableXXX是不可变的(但这种“不可变”是在运行阶段获得的,编译阶段无法据此进行静态检查)。
总之,尽可能地使用Immutable对象和Immutable引用!
第二部分(讲义3-2)
行为等价性:
站在客户端视角看行为等价性,若两个函数对用户来说是等价的,则可相互替换。
根据规约判断是否行为等价,若两个函数均符合某个规约,则它们等价。
注意:行为等价性与函数的具体实现无关!
Specification的结构:
前置条件:对客户端的约束,在使用方法时必须满足的条件;
后置条件:对开发者的约束,方法结束时必须满足的条件。
如果前置条件满足了,后置条件必须满足;如果前置条件不满足,则方法可做任何事情。
通常把前置条件放在@param中,把后置条件放在@return和@throws中,在规约的开头写明函数的功能。
欠定的规约:同一个输入可以有多个输出;
非确定的规约:同一个输入,多次执行得到的输出可能不同。
为避免混乱,欠定的规约 == 非确定的规约。
欠定的规约通常有确定的实现。

操作式规约:例如伪代码;
声明式规约:没有内部实现的描述,只有“初-终”状态。
声明式规约更有价值。
通常情况下,内部实现的细节不在规约里呈现,放在代码实现体内部注释里呈现。
规约的强度:
若规约S2的前置条件比S1更弱,且S2的后置条件比S1更强,则规约的强度S2>=S1,此时就可以用S2替代S1。
(spec变强:更放松的前置条件 + 更严格的后置条件)
几个易混淆的例子:
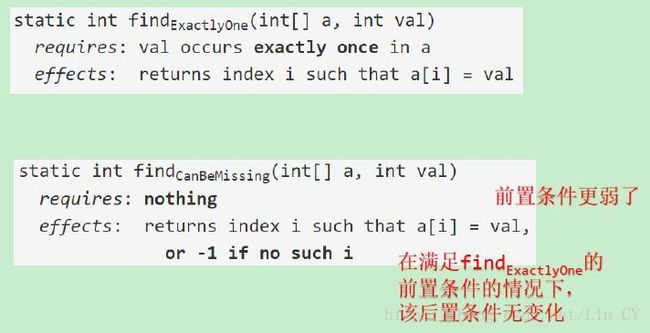
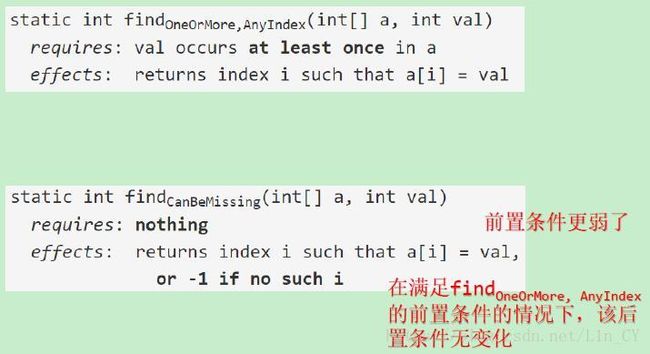

越强的规约,意味着implementor的自由度和责任越重,而client的责任越轻。
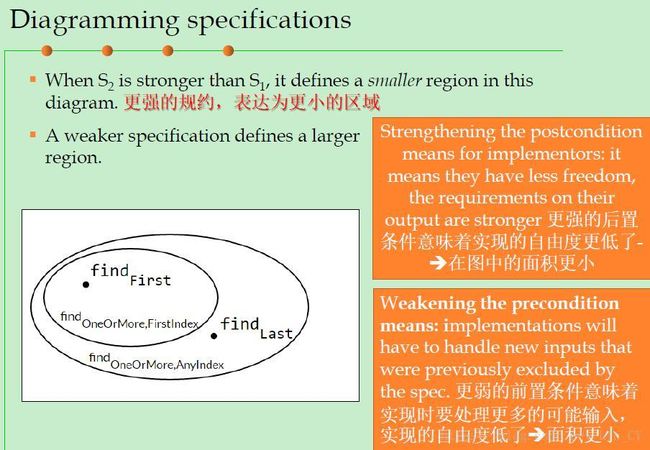
Diagramming specifications:
某个具体实现,若满足规约,则落在其范围内,否则,在其之外。
程序员可以在规约的范围内自由选择实现方式,客户端无需了解具体使用了哪个实现。
更强的规约,表达为更小的区域。
在规约中是否使用前置条件?

第三部分(讲义3-3)
(可变类型的对象:提供了可改变其内部数据的值的操作;
不变数据类型:其操作不改变内部值,而是构造新的对象。)
ADT操作的四种类型:Creators(构造器)、Producers(生产器)、Observers(观察器)、Mutators(变值器,改变对象属性的方法,不可变数据类型没有这个操作)。注意区分,见下图:

表示独立性:client使用ADT时无需考虑其内部如何实现,ADT内部表示(rep)的变化不应影响外部spec和客户端。
除非ADT的操作指明了具体的pre-和post-condition,否则不能改变ADT的内部表示——spec规定了client和implementor之间的契约。
ADT总结:

Invariant(不变量):在任何时候总是true。由ADT来负责其不变量,与client端的任何行为无关。用来保持程序的“正确性”,容易发现错误。
避免表示泄露(Safety from Rep Exposure):防御式拷贝、使用immutable类型(包括unmodifiableXXX)、private权限修饰。

保持不变量和避免表示泄露,是ADT最重要的一个Invarient!
表示空间:内部表示(rep)构成的空间。
抽象空间:抽象值构成的空间,client看到和使用的值。
ADT实现者关注表示空间R,用户关注抽象空间A。R到A的映射是满射,但未必是单射,也未必是双射。
AF(Abstraction Function,抽象函数):表征R到A的映射关系的函数。
RI(Rep Invariant,表示不变量):某个具体的“表示”是否是“合法的”。可以将RI看作所有表示值的一个子集,包含了所有合法的表示值。也可以将RI看作一个条件,描述了什么是“合法”的表示值。
自行设计checkRep()方法(private权限)来在运行时检查RI。
不同的内部表示,需要设计不同的AF和RI。
选择某种特定的表示方式R,进而指定某个子集是“合法”的(RI),并为该子集中的每个值做出“解释”(AF)——即如何映射到抽象空间中的值。
即使是同样的R、同样的RI,也可能有不同的AF,即“解释不同”。
对immutable的ADT来说,它在A空间的abstract value应是不变的,但其内部表示的R空间中的取值则可以是变化的。
设计ADT:(1)选择R和A;(2)RI——合法的表示值;(3)如何解释合法的表示值——映射AF,即每个合法的rep value如何映射到abstract value。
以注释的形式撰写AF、RI、Safety from Rep Exposure:
ADT的规约里只能使用client可见的内容来写,包括参数、返回值、异常等。如果规约里需要提及“值”,只能使用A空间中的“值”。ADT的规约里也不应谈及任何内部表示的细节,以及R空间中的任何值。ADT的内部表示(私有属性)对外部都应严格不可见。
因此,在代码中应以注释的形式(只能由开发者看)写出AF、RI、Safety from Rep Exposure,而不能写在Javadoc文档中,防止被外部看到而破坏表示独立性/信息隐藏。

第四部分(讲义3-4)
接口、抽象类、具体类、继承、多态、方法的重写与重载、泛型,这些都是Java编程语言的基本知识了,这边不再过分强调,只说说几个容易混的点。
多态有三种形式:

可以在同一个类中重载,也可在子类中重载。
重载与重写的区别:
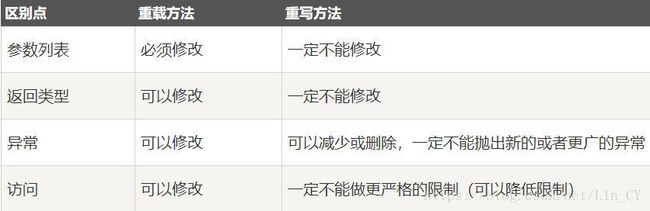
对象向上转型后,利用转型后的对象调用方法时,若子类和父类都有该同名方法,欲确定调用的是父类中的方法还是子类中的方法:首先明确是方法的重载还是重写;由于重写是动态绑定(采用动态类型检查)的,所以调用的是子类的方法;而重载是静态绑定(采用静态类型检查)的,所以调用的是父类的方法。但这个规则对static修饰的方法不适用,见如下例子:

即:对于static或final或private修饰的方法,不管是重写还是重载,都是静态绑定的。
不能用instanceof()来检查泛型的具体类型,也不能创建包含泛型的对象的数组。
泛型接口可以有泛型的实现类,也可以有非泛型的实现类。

泛型中通配符的使用具体见5-2。
接口确定ADT规约,类实现ADT。
第五部分(讲义3-5)
==:引用等价性
equals():对象等价性
对基本数据类型,使用==判定相等;对对象类型,使用equals()判定相等,若用==,则是在判定两个对象的身份标识ID是否相等(指向内存里的同一段空间)。
在Object中实现的缺省equals()是在判断引用等价性。这通常不是程序员所期望的,因此需要重写。
equals()必须确定一个等价关系,即自反、传递、对称。除非对象被修改了,否则调用多次equals()应是同样的结果。对于任意的非空引用值x,x.equals(null)一定返回false。
重写equals()时,也必须要重写hashCode(),并且两者应相对应。
两个equal的对象,其hashCode()的结果必须一致,但hashCode()值一样的两个对象不一定equal,即,不相等的对象,也可以映射为同样的hashCode,但性能会变差。
hashCode()主要用于集合中重复元素的判断,从而提高性能(减少使用equals的次数)。只有当两个对象的hashCode()值相等时,才会调用equals()进行再次确认;对于hashCode()不同的两个对象,它们一定不相等,所以就不用再调用equals()方法来确认了,此时性能就提高了。
除非对象被修改了,否则调用多次hashCode()应是同样的结果。
hashCode()的几种写法:


Mutable对象的等价性:
观察等价性:在不改变状态的情况下,两个mutable对象是否看起来一致;
行为等价性:调用对象的任何方法都展示出一致的结果。
对immutable类型来说,实现的其实是行为等价性。
对mutable类型来说,往往倾向于实现严格的观察等价性。但在有些时候,观察等价性可能导致bug,甚至可能破坏RI,见下面这个例子:

因此,如果某个mutable对象包含在集合类中,当其发生改变后,集合类的行为不确定,务必小心。
在JDK中,不同的mutable类使用不同的等价性标准。
对mutable类型,实现行为等价性即可。也就是说,只有指向同样内存空间的对象,才是相等的。所以,对可变类型来说,无需重写equals()和hashCode(),直接继承Object对象的这两个方法即可。如果一定要判断两个可变对象看起来是否一致,最好定义一个新的方法来判断。
对immutable类型,必须重写equals()和hashCode()。