爬取电影天堂最新电影(xpath结合lxml)
完整代码
import requests
from lxml import etree
from openpyxl import Workbook
BASEURL='https://www.dytt8.net'
HEADERS = {
'Referer': 'https://www.dytt8.net/css/index.css',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
#获取影片的详情页url
def get_detail_urls(url):
global HEADERS
global BASEURL
r = requests.get(url,headers=HEADERS)
html = etree.HTML(r.text)
hrefs=html.xpath('//table[@class="tbspan"]//a/@href')
detail_urls = []
for href in hrefs:
detail_urls.append(BASEURL+href)
return detail_urls
#进入详情页获取详细信息
def spider(detail_url):
r = requests.get(detail_url, headers=HEADERS)
r.encoding='gbk'
html = etree.HTML(r.text)
global dura,scenarist,actor,category,language,director
#获取标题
title = str(html.xpath('//h1//font[@color="#07519a"]/text()')[0])
#获取海报,有一些网页会没有相关信息,需要捕获这种异常
try:
img = str(html.xpath("//p//img/@src")[0])
except IndexError:
return
#获取详情
intros = html.xpath('//div[@id="Zoom"]//br')
for intro in intros:
intro=etree.tostring(intro, encoding='utf-8').decode('utf-8')
#获取影片类别
if intro.startswith('
◎类 别'):
category = intro.replace('
◎类 别', '').strip()
#获取影片语言
elif intro.startswith('
◎语 言'):
language = intro.replace('
◎语 言', '').strip()
#获取影片片长
elif intro.startswith('
◎片 长'):
dura = intro.replace('
◎片 长', '').strip()
#获取影片导演
elif intro.startswith('
◎导 演'):
director = intro.replace('
◎导 演', '').strip()
# 获取影片编剧
elif intro.startswith('
◎编 剧'):
scenarist = intro.replace('
◎编 剧', '').strip()
# 获取影片主演
elif intro.startswith('
◎主 演'):
actor = intro.replace('
◎主 演', '').strip()
#构建字典存放每部电影的信息
info = {
'title':title,
'category':category,
'language':language,
'duration':dura,
'director':director,
'scenarist':scenarist,
'actor':actor,
'img': img,
}
return info
#将信息写入excel中
def save_excel(infos):
wb = Workbook()
dest_filename = '电影天堂最新电影.xlsx'
ws1 = wb.active
ws1.title = "电影"
#打印表头
_ = ws1.cell(column=1, row=1, value="{0}".format('标题'))
_ = ws1.cell(column=2, row=1, value="{0}".format('类型'))
_ = ws1.cell(column=3, row=1, value="{0}".format('语言'))
_ = ws1.cell(column=4, row=1, value="{0}".format('时长'))
_ = ws1.cell(column=5, row=1, value="{0}".format('导演'))
_ = ws1.cell(column=6, row=1, value="{0}".format('编剧'))
_ = ws1.cell(column=7, row=1, value="{0}".format('主演'))
_ = ws1.cell(column=8, row=1, value="{0}".format('图片url'))
row = 2
for info in infos:
clo=1
for key,value in info.items():
_ = ws1.cell(column=clo, row=row, value="{0}".format(value))
clo += 1
row += 1
wb.save(filename=dest_filename)
def main():
urls='https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html'
#存放所有影片信息字典的列表
infos=[]
#遍历1-5页
for page in range(1,6):
print('正在爬取第{}页:'.format(page))
# 获取详情页
url=urls.format(page)
detail_urls=get_detail_urls(url)
#进入详情页获取影片的详细信息
for detail_url in detail_urls:
info = spider(detail_url)
infos.append(info)
print(info)
#写入excel
save_excel(infos)
if __name__ == '__main__':
main()
分析
爬取电影天堂最新电影的数据,先看一下页面
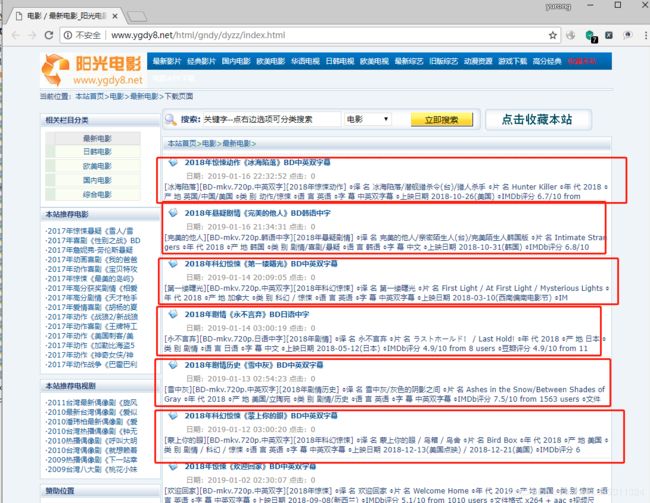
在这个页面标题名,信息不多,需要点击进入详情页才能获取详细信息

还有一点就是我们要获取的是多个页,而不只是一页上的所有电影

然后我们进行抓包发现
#第一页url
http://www.ygdy8.net/html/gndy/dyzz/list_23_1.html
#第二页的url
http://www.ygdy8.net/html/gndy/dyzz/list_23_2.html
#第三页的url
http://www.ygdy8.net/html/gndy/dyzz/list_23_3.html
#第四页的url
http://www.ygdy8.net/html/gndy/dyzz/list_23_4.html
这里就可以看出控制每一页的url格式为
’http://www.ygdy8.net/html/gndy/dyzz/list_23_‘+页码+‘.html’
流程
1. 制作要爬取页码的url
for page in range(1,6):
print('正在爬取第{}页:'.format(page))
# 获取详情页
url=urls.format(page)
2. 通过xpath语法结合lxml,找到每个页面所有电影的详情页url
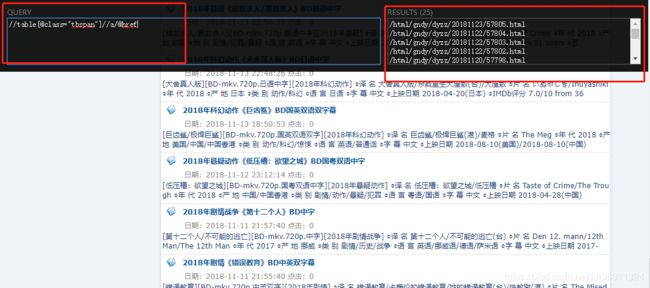
def get_detail_urls(url):
r = requests.get(url,headers=HEADERS)
html = etree.HTML(r.text)
hrefs=html.xpath('//table[@class="tbspan"]//a/@href')
detail_urls = []
for href in hrefs:
detail_urls.append(BASEURL+href)
return detail_urls
3.进入详情页获取影片的详细信息
#进入详情页获取详细信息
def spider(detail_url):
r = requests.get(detail_url, headers=HEADERS)
# 编码的格式是gb2312,属于gbk的子集
r.encoding='gbk'
html = etree.HTML(r.text)
#获取标题
title = str(html.xpath('//h1//font[@color="#07519a"]/text()')[0])
#获取海报,有一些网页会没有相关信息,需要捕获这种异常
try:
img = str(html.xpath("//p//img/@src")[0])
except IndexError:
return
#获取详情
intros = html.xpath('//div[@id="Zoom"]//br')
for intro in intros:
intro=etree.tostring(intro, encoding='utf-8').decode('utf-8')
#获取影片类别
if intro.startswith('
◎类 别'):
category = intro.replace('
◎类 别', '').strip()
#获取影片语言
elif intro.startswith('
◎语 言'):
language = intro.replace('
◎语 言', '').strip()
#获取影片片长
elif intro.startswith('
◎片 长'):
dura = intro.replace('
◎片 长', '').strip()
#获取影片导演
elif intro.startswith('
◎导 演'):
director = intro.replace('
◎导 演', '').strip()
# 获取影片编剧
elif intro.startswith('
◎编 剧'):
scenarist = intro.replace('
◎编 剧', '').strip()
# 获取影片主演,主演有很多个,但是为了省事这里只打印一个
elif intro.startswith('
◎主 演'):
actor = intro.replace('
◎主 演', '').strip()
#构建字典存放每部电影的信息
info = {
'title':title,
'category':category,
'language':language,
'duration':dura,
'director':director,
'scenarist':scenarist,
'actor':actor,
'img': img,
}
return info
4. 写入excel中
#将信息写入excel中
def save_excel(infos):
wb = Workbook()
dest_filename = '电影天堂最新电影.xlsx'
ws1 = wb.active
ws1.title = "电影"
#打印表头
_ = ws1.cell(column=1, row=1, value="{0}".format('标题'))
_ = ws1.cell(column=2, row=1, value="{0}".format('类型'))
_ = ws1.cell(column=3, row=1, value="{0}".format('语言'))
_ = ws1.cell(column=4, row=1, value="{0}".format('时长'))
_ = ws1.cell(column=5, row=1, value="{0}".format('导演'))
_ = ws1.cell(column=6, row=1, value="{0}".format('编剧'))
_ = ws1.cell(column=7, row=1, value="{0}".format('主演'))
_ = ws1.cell(column=8, row=1, value="{0}".format('图片url'))
row = 2
for info in infos:
clo=1
for key,value in info.items():
_ = ws1.cell(column=clo, row=row, value="{0}".format(value))
clo += 1
row += 1
wb.save(filename=dest_filename)