YOLO1从理解到亲手训练
采用tensorflow框架编写,中文注释完全,含测试和训练
模型简介
yolo v1
yolo1是端对端的目标检测模型,参考论文为You Only Look Once:Unified, Real-Time Object Detection
主要思想是将图片分割成cell_size * cell_size的格子,每个格子里只包含一个目标,通过网络来输出每个格子的目标值,其中判断格子中是否有目标即判断目标中心点是否在对应格子中。
模型大致结构图如下:
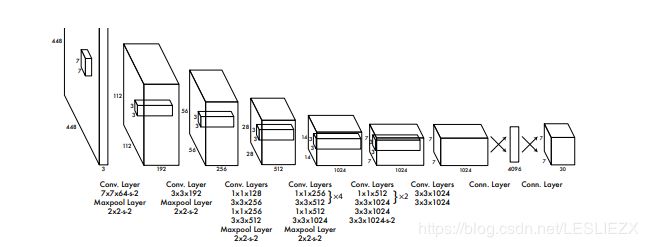
模型经过多层卷积和全连接层,将图片最终输出尺寸为[batch,cell_size * cell_size * (num_classes+ box_per_cell* 5)]。
简单介绍一下输出的表示:
通过reshape分成[batch,cell_size,cell_size,num_classes]表示每个格子对应的类别;
[batch_,cell_size,cell_size,box_per_cell]表示每个格子中是否存在目标的置信度,之所以选择两个box_per_cell是为了让预测精度更准确,通俗来讲就是三个臭皮匠顶一个诸葛亮;
[batch,cell_size,cell_size,box_per_cell,4]表示每个格子每个选框中的目标框的坐标值,4个值分别为目标图片的中心横纵坐标偏移值x,y,目标图片的长宽w,h,但都经过一定归一化处理。x,y是相对于格子的偏移量经过了除以整个图片大小的归一化。
举例说明:
就是原图目标的中心坐标是x1,y1,原图宽高分别为w1,h1假设目标中心坐落在下标为[0,1]的格子里,即int(x1/image_size* cell_size),int(y1/image_size* cell_size)=0,1,此时对应格子的目标置信度应该都为1,x和y应该是相对于[0,1]这个格子的偏移量,具体算法是:x=x1/image_size* cell_size-0,y=y1/image_size* cell_size-1。
w,h也进行归一化但还要开方,具体算法为:w=square(w1/image_size),h=square(h1/image_size),归一化可以把数值指定在一定范围有利于训练,把w,h开方,是因为w,h的值不同于x,y是格子的偏移量限定于一定区间,w,h是针对整个图片而言,变化没那么平缓,所以进行开方。
真实训练数据也按上述方法来处理,只不过刚开始的shape是[cell_size,cell_size,4]然后将它reshape成[cell_size,cell_size,1,4]再复制成[batch,cell_size,cell_size,box_per_cell,4]
关于损失函数计算有目标损失,无目标损失,类别损失,目标框损失,占比不同,实际显示图片要加上非极大值抑制,把两个很相近的目标框只保留置信度高的。
yolo v2
关于yolo v2 网上博客大致内容介绍很详细,可以参考论文YOLO9000: Better, Faster, Stronger
我主要介绍它的训练数据长什么样,这也是困扰我好久的。yolo v2 加了anchor box为上述每个格子提供多个目标的可能,真实值的目标要与anchor box计算iou值,大于阈值才保留,否则保留iou值最大的目标,这样label的shape就变成了[batch, cell_size, cell_size, N_ANCHORS, num_clsses+5],相关坐标x,y,w,h和yolo1处理方式也些许不同,感兴趣的同学可以去参考论文。
代码介绍
代码只针对于yolo1的训练和测试,实现自己从头开始训练yolo,本测试代码支持摄像头
主要环境配置为:
ubuntu 16.04
python 3.5.5
tensorflow 1.4.1
opencv 3.4.1
代码实现详情见我的github,中文注释,清晰易懂,还请大家批评指正
结果展示
测试图片均来自百度图片


