猫眼快搜
一、前言
在平时搜索文件或者应用时,你会使用左下角的小圆圈Cortana吗?那是一款可以实现快速文件检索的工具。我将仿照everything桌面工具,写一个可以跨平台执行的Java程序
二、运行环境
我用的系统是win10系统,所用的开发工具是IDEA,创建的是一个maven项目,使用H2数据库
三、大概框架
对于everything,首先想到的应该是他的search检索功能,而检索出来的文件显示则需要使用数据库来插入保存数据。
而对于项目,可以分为四类:
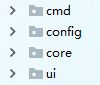
- cmd:everything应用程序命令行的交互主程序
- config:包中主要放置everything应用程序的配置相关的类
- core:主要放置everything应用程序的核心的功能代码
- ui:放置用户主界面的主程序
四、程序功能
1.整体思路:
1)help
在使用任意一款APP时,都会有指导,而windows底下也有help帮助命令,仿照help命令,创建一个属于自己的help帮助命令
private static void help() {
System.out.println("命令列表:");
System.out.println("退出:quit");
System.out.println("帮助:help");
System.out.println("索引:index");
System.out.println("搜索:search [ img | doc | bin | archive | other]");
} 2)search
everything最重要的就是搜索功能,而如何搜索、如何显示结果、搜索速度,都是我们所要考虑的问题。
如何搜索 --->与index配合使用,将文件从数据库中查找
结果显示 --->通过使用数据库进行索引结果的保存与输出
搜索速度 --->使用多线程,多个盘一起搜索,速度提升
3)index
与search配合使用,将文件索引到数据库中
用户自定义索引:用户自定义索引目录和排除索引的目录
文件系统监听:当本地文件修改或删除是,数据库会有相应的修改
4)quit
当用户不再使用everything后,输入quit退出该程序
2.分类解决
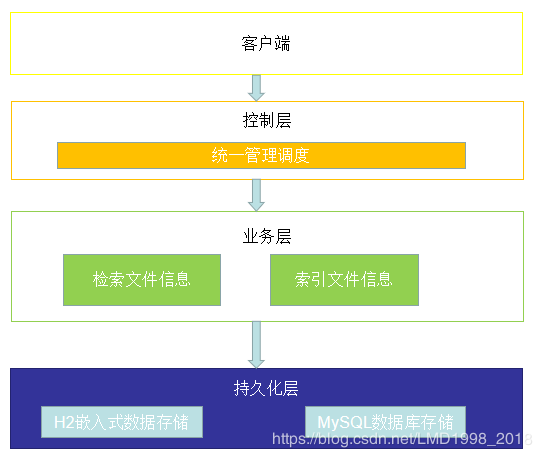
1)首先,按代码整体,分为3类:
- cmd:everything应用程序命令行的交互主程序
- config:包中主要放置everything应用程序的配置相关的类
- core:主要放置everything应用程序的核心的功能代码
2)客户端:cmd
是整个程序的入口,只有运行此类,才可实现各种功能(这部分是最后写的,程序的编写顺序应该是图中由下向上一点点搭建)
public class EveryThingcmd {
private static Scanner scanner = new Scanner(System.in);
public static void main(String[] args) {
System.out.println("主程序入口……");
//欢迎
welcome();
//交互式
interactive(manager);
//解析用户参数
parseParams(args);
//启动后台清理线程
manager.startbgClearThread();
}
private static void interactive(EverythingManger manger){
while (true) {
System.out.println("everything >>");
String input = scanner.nextLine();
//优先处理search
if (input.startsWith("search")) {
//search name [file_type]
String[] values = input.split(" ");
if (values.length >= 2) {
if (!values[0].equals("search")) {
help();
continue;
}
Condition condition = new Condition();
String name = values[1];
condition.setName(name);
if (values.length >= 3) {
String fileType = values[2];
condition.setFileType(fileType.toUpperCase());
}
search(manger, condition);
continue;
} else {
help();
continue;
}
}
switch(input){
case "help":
help();
break;
case "quit":
quit();
break;
case "index":
index(manger);
break;
default:
help();
}
}
}
private static void welcome() {
System.out.println("欢迎使用,Everything ");
}
private static void quit() {
System.out.println("再见");
System.exit(0);
}
private static void help() {
System.out.println("命令列表:");
System.out.println("退出:quit");
System.out.println("帮助:help");
System.out.println("索引:index");
System.out.println("搜索:search [ img | doc | bin | archive | other]");
}
private static void search(EverythingManger manger,Condition condition){
//统一调度器中的search
// name fileType limit orderByAsc
List things = manger.search(condition);
for (Thing t:things) {
System.out.println(t.getPath());
}
}
private static void index(EverythingManger manger) {
//统一调度器中的index
new Thread(new Runnable() {
@Override
public void run() {
manger.buildIndex();
}
}).start();
}
} 3)控制层:config
统一管理调度,这部分要实现的功能是构建索引和检索数据
@Getter
public class everythingConfig {
private static volatile everythingConfig config;
private everythingConfig(){}
//建立索引文件的路径
private Set includePath = new HashSet<>();
//排除索引文件的路径
private Set excludePath = new HashSet<>();
//检索最大的返回值数量,默认值30个
@Setter
private Integer maxReturn = 30;
//深度排序的规则,默认是升序
@Setter
private Boolean depthOrderAsc = true;
/**
* H2数据库文件路径
*/
private String h2IndexPath = System.getProperty("user.dir")+File.separator+"everything_plus";
//初始化默认的配置
private void initDefaultPathsConfig(){
//1.获取文件系统
FileSystem fileSystem = FileSystems.getDefault();
//遍历的目录
Iterable iterable = fileSystem.getRootDirectories();
iterable.forEach(path -> config.includePath.add(path.toString()));
//排除的目录
//windows : C:\Windows C:\Program Files (x86) C:\Program Files C:\ProgramData
//Linux: /tmp /etc
String osname = System.getProperty("os.name");
if(osname.startsWith("Windows")){
config.getExcludePath().add("C:\\Windows");
config.getExcludePath().add("C:\\Program Files (x86)");
config.getExcludePath().add("C:\\Program Files");
config.getExcludePath().add("C:\\ProgramData");
}else {
config.getExcludePath().add("/tmp");
config.getExcludePath().add("/etc");
config.getExcludePath().add("/root");
}
}
public static everythingConfig getInstance(){
if (config==null){
synchronized (everythingConfig.class){
if(config==null){
config = new everythingConfig();
config.initDefaultPathsConfig();
}
}
}
return config;
}
}
4)业务层和持久化层
I.创建基本模型类:
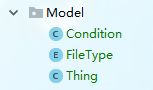
a. Condition:检索类,存放检索的条件
b. FileType:文件类型,使用枚举自己规定文件的类型 eg:图片类型 IMG包含:"png","jpg","gif"
c. Thing:索引文件后的信息,如:文件名称、文件类型、文件路径、文件深度
II.搭建持久化层:
![]()
a.创建数据库
-- 创建数据库
-- create database if not exists everthing_plus;
-- 创建数据库表
drop table if exists file_index;
create table if not exists file_index(
name varchar(256) not null comment '文件名称',
path varchar (1024) not null comment '文件路径',
depth int not null comment '文件路径深度',
file_type varchar(32) not null comment '文件类型'
);
b.数据库编程JDBC:创建数据源执行数据库脚本
i. 数据源操作不需要反复操作,所以选择:工厂设计模式,
ii. 初始化好的数据源不能被用户随便实例化,所以选择:单例模式
iii. 此类应该完成的工作: 数据源的初始化 + 初始化脚本的执行
//数据源操作
public final class DataSourceFactory {
/**
* 数据源(单例)
*/
//druid:java最好的数据库连接池,druid能够提供强大的监控和扩展功能
private static volatile DruidDataSource dataSource;
private DataSourceFactory(){}
public static DataSource dataSource() {
if (dataSource == null) {
synchronized(DataSourceFactory.class) {
if (dataSource == null) {
//实例化
dataSource = new DruidDataSource();
//JDBC driver class
dataSource.setDriverClassName("org.h2.Driver");
//url, username, password
//采用的是H2的嵌入式数据库,数据库以本地文件的方式存储,只需要提供url接口
//JDBC规范中关于MySQL jdbc:mysql://ip:port/databaseName
//JDBC规范中关于H2 jdbc:h2:filepath ->存储到本地文件
dataSource.setUrl("jdbc:h2:" + everythingConfig.getInstance().getH2IndexPath());
//Druid数据库连接池的可配置参数
dataSource.setValidationQuery("select now()");
}
}
}
return dataSource;
}
//初始化数据库
public static void initDatabase(){
//1.获取数据源
DataSource dataSource = DataSourceFactory.dataSource();
//2.获取SQL语句
//不采取读取绝对路径文件
//E:\idealU\EveryThing\src\main\resources\everything_plus.sql :这是一个绝对路径,如果程序发送给别人,路径会发生变化。不采用
//采取读取classpath路径下的文件
try(InputStream in = DataSourceFactory.class.getClassLoader().getResourceAsStream("everything_plus.sql")){
if(in==null){
throw new RuntimeException("Not read init database script please check it");
}
StringBuilder sqlBulider = new StringBuilder();
try( BufferedReader reader = new BufferedReader(new InputStreamReader(in));){
String line = null;
while( (line=reader.readLine()) != null){
if(!line.startsWith("--")){
sqlBulider.append(line);
}
}
}
//3,获取数据库连接和名称执行SQL
String sql = sqlBulider.toString();
//JDBC
//3.1 获取数据库的连接
Connection connection = dataSource.getConnection();
//3.2 创建命令
PreparedStatement statement = connection.prepareStatement(sql);
//3.3 执行SQL语句
statement.execute();
statement.close();
connection.close();
} catch (IOException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
III.业务层:整个程序的核心操作
a.索引:
- 数据库的初始化工作
- 数据库的访问
- 实现索引业务:遍历文件系统,将文件对象转换成Thing对象,调用数据库访问的插入操作
b.检索:
- 数据库的初始化
- 数据库的访问
- 实现检索业务
检索与索引配合使用,因为这两个对于数据库的操作较为相似,因此放入同一个包dao下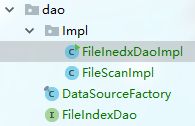
c.文件系统监控
- 文件(目录)的增改
- 监控操作系统的文件在系统中的变化,及时修改
完整代码 : https://github.com/lmdlll/everything_plus
五、涉及技术
1.Java多线程、文件操作
2.数据库Database、JDBC
3.Lombok库
4.Apache Commons IO (文件系统监听)
六、测试
1.等价类划分:
- 有效等价类:
| 消息类型 | 输入内容 | 测试结果 |
| 退出 | quit | 退出成功 |
| 帮助 | help | 成功显示命令列表 |
| 检索 | search java | 成功检索到包含java的文件 |
| search java pdf | 成功检索到包含java的文档文件 | |
| search java img | 成功检索到包含java的图片文件 | |
| search java bin | 成功检索到包含java的二进制文件 | |
| search java other | 成功检索到包含java的不是文档、图片、二进制、归档类型的文件 |
- 无效等价类
1)检索内容不存在:没有任何输出
2)检索exclude里的文件:没有任何输出
2.边界值分析法
1)默认检索文件输出数量上限:30个(用户可以自定义数量上限)
2)默认检索文件输出下限:1个
3.容错性测试
1)输入错误命令:没有任何输出
2)输入错误命令格式:没有任何输出
3)数据库连接失败:报错
4.兼容性测试
该项目运行必须在已安装jre的环境下
七、待续
上述只是一个简单的everything项目,可以根据我的代码继续进行一些扩展。
扩展点:
1.创建一个可视化界面而非在命令行进行输入输出
2.使用数据库进行历史记录的保存
3.用户使用此程序电脑必须装有jre