Spark Structrued Streaming源码分析--(三)Aggreation聚合状态存储与更新
- 一、持续更新的无限表
- 二、创建StatefulAggregationStrategy流计算聚合策略
- 1、先简单介绍下spark sql对应的QueryExecution
- 2、IncrementalExecution对QueryExecution的扩展,生成流计算相关策略
- 三、statestore聚合状态存储
- 四、对statestore数据的更新(删除)及过期数据的写出
一、持续更新的无限表
在spark structured streaming中,通过维持聚合数据的状态,并比较水位线watermark删除不再更新的聚合数据,实现unbounded table(持续更新的无限表)
引用一个spark官方文档示例
val windowedCounts = words.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word"
).count()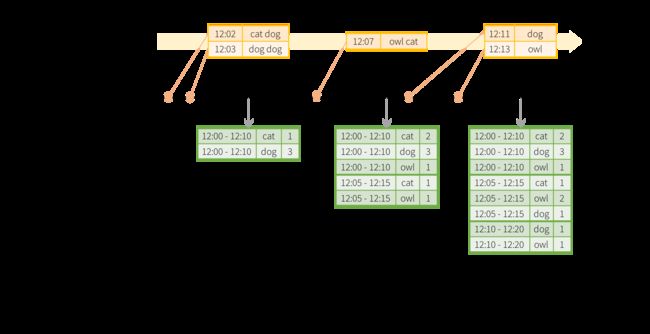
下面按照聚合策略stategies的创建、stateStore聚合状态的存储、对statestore数据的更新(删除)及过期数据的写出三个层次,解析spark流计算对应的Aggregation策略。
二、创建StatefulAggregationStrategy流计算聚合策略
- 一、持续更新的无限表
- 二、创建StatefulAggregationStrategy流计算聚合策略
- 1、先简单介绍下spark sql对应的QueryExecution
- 2、IncrementalExecution对QueryExecution的扩展,生成流计算相关策略
- 三、statestore聚合状态存储
- 四、对statestore数据的更新(删除)及过期数据的写出
1、先简单介绍下spark sql对应的QueryExecution
spark sql从解析到最后生成物理执行计划的过程,在QueryExecution中可以看到完整的定义,主要流程及代码:

class QueryExecution(val sparkSession: SparkSession, val logical: LogicalPlan) {
// 其内部定义了strategies,即逻辑执行计划到物理执行计划的绑定和转化关系
protected def planner = sparkSession.sessionState.planner
/**将antlr通过词法、语法分析生成的未解析logical plan转换为Resolved logical plan,其
*中一个重要的batchs策略即ResolveRelations:查找catalog,替换为from关键字对应的表
lazy val analyzed: LogicalPlan = {
SparkSession.setActiveSession(sparkSession)
sparkSession.sessionState.analyzer.executeAndCheck(logical)
}
/**查找table或logical plan是否使用缓存,useCachedData()内部是
*调用lookupCachedData()返回CachedData对应的InMemoryRelation,在后续生成物理
*执行计划时,可以和InMemoryTableScanExec绑定*/
lazy val withCachedData: LogicalPlan = {
assertAnalyzed()
assertSupported()
sparkSession.sharedState.cacheManager.useCachedData(analyzed)
}
/**spark预先定义的一系列优化策略,例如join谓词下推,sql语句常量相加等*/
lazy val optimizedPlan: LogicalPlan = sparkSession.sessionState.optimizer.execute(withCachedData)
/**将逻辑执行计划转换为物理执行计划,定义的strategies在SparkPlanner中
*依次对logical plan中所有节点绑定为Exec类型的SparkPlan*/
lazy val sparkPlan: SparkPlan = {
SparkSession.setActiveSession(sparkSession)
// TODO: We use next(), i.e. take the first plan returned by the planner, here for now,
// but we will implement to choose the best plan.
planner.plan(ReturnAnswer(optimizedPlan)).next()
}
// executedPlan should not be used to initialize any SparkPlan. It should be
// only used for execution.
// 插入shuffle等操作
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)
/** Internal version of the RDD. Avoids copies and has no schema */
lazy val toRdd: RDD[InternalRow] = executedPlan.execute()
}2、IncrementalExecution对QueryExecution的扩展,生成流计算相关策略
IncrementalExecution是QueryExecution的子类,MicroBatchExecution中会使用此类型qe,生成流计算的物理执行计划,IncrementalExecution附加的strategy策略为:
override def extraPlanningStrategies: Seq[Strategy] =
StreamingJoinStrategy :: // 流与流join
StatefulAggregationStrategy :: // 流计算聚合
FlatMapGroupsWithStateStrategy :: // 可自定义数据状态的策略,例如更新Event事件
StreamingRelationStrategy :: // DataStreamReader生成的relation绑定,MicroBatchExecution的runBatch()中会替换,不会真正执行。对应case StreamingExecutionRelation(source, output)这段代码
StreamingDeduplicationStrategy :: Nil // drop duplicate相关实现上述StatefulAggregationStrategy源码及注释:
object StatefulAggregationStrategy extends Strategy {
override def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case _ if !plan.isStreaming => Nil
// 用于提取watermark,EventTimeWatermarkExec内部定义了eventTimeStats,是一个累加器
case EventTimeWatermark(columnName, delay, child) =>
EventTimeWatermarkExec(columnName, delay, planLater(child)) :: Nil
//调用AggUtils.planStreamingAggregation()创建Aggregate对应的SparkPlan
case PhysicalAggregation(
namedGroupingExpressions, aggregateExpressions, rewrittenResultExpressions, child) =>
aggregate.AggUtils.planStreamingAggregation(
namedGroupingExpressions,
aggregateExpressions,
rewrittenResultExpressions,
planLater(child))
case _ => Nil
}
}AggUtils.planStreamingAggreagation()创建聚合的物理执行计划,分以下步骤,这也是新的输入流数据被聚合的主要流程:
① 创建partialAggregate,指定的mode = Partial即对当前批次输入的数据,各hash分区按key进行数据聚合,结果类似于key–>values
② 创建partialMerged1,指定的PartialMerge,各hash分区数据合并,结果类似于key–>value
③ 创建restored: StateStoreRestoreExec(groupingAttributes, None, partialMerged1),其第二个参数stateInfo为空,即尚未定义batchID等信息,在IncrementalExecution的preparations阶段被替换进来
④ 创建partialMerged2,将restored读取的上一批次聚合状态,与当前批次输入的数据进行合并
⑤ 创建saved: StateStoreSaveExec,用于更新聚合状态到stateStore,并写出和删除过期数据。
⑥ 创建finalAndCompleteAggregate,指定mode = final,merge aggregation buffers,并输出最终结果
def planStreamingAggregation(
groupingExpressions: Seq[NamedExpression],
functionsWithoutDistinct: Seq[AggregateExpression],
resultExpressions: Seq[NamedExpression],
child: SparkPlan): Seq[SparkPlan] = {
val groupingAttributes = groupingExpressions.map(_.toAttribute)
val partialAggregate: SparkPlan = {
val aggregateExpressions = functionsWithoutDistinct.map(_.copy(mode = Partial))
val aggregateAttributes = aggregateExpressions.map(_.resultAttribute)
createAggregate(
groupingExpressions = groupingExpressions,
aggregateExpressions = aggregateExpressions,
aggregateAttributes = aggregateAttributes,
resultExpressions = groupingAttributes ++
aggregateExpressions.flatMap(_.aggregateFunction.inputAggBufferAttributes),
child = child)
}
val partialMerged1: SparkPlan = {
val aggregateExpressions = functionsWithoutDistinct.map(_.copy(mode = PartialMerge))
val aggregateAttributes = aggregateExpressions.map(_.resultAttribute)
createAggregate(
requiredChildDistributionExpressions =
Some(groupingAttributes),
groupingExpressions = groupingAttributes,
aggregateExpressions = aggregateExpressions,
aggregateAttributes = aggregateAttributes,
initialInputBufferOffset = groupingAttributes.length,
resultExpressions = groupingAttributes ++
aggregateExpressions.flatMap(_.aggregateFunction.inputAggBufferAttributes),
child = partialAggregate)
}
val restored = StateStoreRestoreExec(groupingAttributes, None, partialMerged1)
val partialMerged2: SparkPlan = {
val aggregateExpressions = functionsWithoutDistinct.map(_.copy(mode = PartialMerge))
val aggregateAttributes = aggregateExpressions.map(_.resultAttribute)
createAggregate(
requiredChildDistributionExpressions =
Some(groupingAttributes),
groupingExpressions = groupingAttributes,
aggregateExpressions = aggregateExpressions,
aggregateAttributes = aggregateAttributes,
initialInputBufferOffset = groupingAttributes.length,
resultExpressions = groupingAttributes ++
aggregateExpressions.flatMap(_.aggregateFunction.inputAggBufferAttributes),
child = restored)
}
// Note: stateId and returnAllStates are filled in later with preparation rules
// in IncrementalExecution.
val saved =
StateStoreSaveExec(
groupingAttributes,
stateInfo = None,
outputMode = None,
eventTimeWatermark = None,
partialMerged2)
val finalAndCompleteAggregate: SparkPlan = {
val finalAggregateExpressions = functionsWithoutDistinct.map(_.copy(mode = Final))
// The attributes of the final aggregation buffer, which is presented as input to the result
// projection:
val finalAggregateAttributes = finalAggregateExpressions.map(_.resultAttribute)
createAggregate(
requiredChildDistributionExpressions = Some(groupingAttributes),
groupingExpressions = groupingAttributes,
aggregateExpressions = finalAggregateExpressions,
aggregateAttributes = finalAggregateAttributes,
initialInputBufferOffset = groupingAttributes.length,
resultExpressions = resultExpressions,
child = saved)
}
finalAndCompleteAggregate :: Nil
}IncrementalExecution在最后的preparations阶段,对StateStoreSaveExec、StreamingSymmetricHashJoinExec类型的物理执行计划,调用nextStatefulOperationStateInfo(),即指定当前批次的处理进度,并创建新的Exec,写入当前的watermark:
/** Locates save/restore pairs surrounding aggregation. */
val state = new Rule[SparkPlan] {
override def apply(plan: SparkPlan): SparkPlan = plan transform {
case StateStoreSaveExec(keys, None, None, None,
UnaryExecNode(agg,
StateStoreRestoreExec(_, None, child))) =>
/**nextStatefulOperationStateInfo()内部,主要是根据currentBatchId
*和statefulOperatorId生成新的StatefulOperatorStateInfo**/
val aggStateInfo = nextStatefulOperationStateInfo
StateStoreSaveExec(
keys,
Some(aggStateInfo),
Some(outputMode),
// 写入当前watermark
Some(offsetSeqMetadata.batchWatermarkMs),
agg.withNewChildren(
StateStoreRestoreExec(
keys,
Some(aggStateInfo),
child) :: Nil))
case StreamingDeduplicateExec(keys, child, None, None) =>
StreamingDeduplicateExec(
keys,
child,
Some(nextStatefulOperationStateInfo),
Some(offsetSeqMetadata.batchWatermarkMs))
case m: FlatMapGroupsWithStateExec =>
m.copy(
stateInfo = Some(nextStatefulOperationStateInfo),
batchTimestampMs = Some(offsetSeqMetadata.batchTimestampMs),
eventTimeWatermark = Some(offsetSeqMetadata.batchWatermarkMs))
case j: StreamingSymmetricHashJoinExec =>
j.copy(
stateInfo = Some(nextStatefulOperationStateInfo),
eventTimeWatermark = Some(offsetSeqMetadata.batchWatermarkMs),
stateWatermarkPredicates =
StreamingSymmetricHashJoinHelper.getStateWatermarkPredicates(
j.left.output, j.right.output, j.leftKeys, j.rightKeys, j.condition.full,
Some(offsetSeqMetadata.batchWatermarkMs))
)
}
}
override def preparations: Seq[Rule[SparkPlan]] = state +: super.preparations至此,创建流计算的聚合策略完成。
三、statestore聚合状态存储
- 一、持续更新的无限表
- 二、创建StatefulAggregationStrategy流计算聚合策略
- 1、先简单介绍下spark sql对应的QueryExecution
- 2、IncrementalExecution对QueryExecution的扩展,生成流计算相关策略
- 三、statestore聚合状态存储
- 四、对statestore数据的更新(删除)及过期数据的写出
- 实现聚合状态的存储,spark有两个接口类:StateStoreProvider和StateStore,其中StateStoreProvider主要的方法是根据流计算的批次(version),获取对应的StateStore(保存了当前分区的聚合数据,一般内部为一个HashMap,key为聚合group
by后面的关键字,value为聚合后各Column的值) - 上述接口在spark中默认的实现类是HDFSBackedStateStoreProvider和HDFSBackedStateStore,也可以通过配置spark.sql.streaming.stateStore.providerClass实现自定义的StateStoreProvider。
- HDFSBackedStateStoreProvider对应的HDFS文件布局:

HDFSBackedStateStoreProvider内部重要的成员变量和方法:
//加载最近100个version的stateStore
private lazy val loadedMaps = new mutable.HashMap[Long, MapType]
//state存储对应的dir
private lazy val baseDir = stateStoreId.storeCheckpointLocation()
//根据version获取对应数据map, 拷贝并创建新的store
override def getStore(version: Long): StateStore = synchronized {
require(version >= 0, "Version cannot be less than 0")
val newMap = new MapType()
if (version > 0) {
newMap.putAll(loadMap(version))
}
val store = new HDFSBackedStateStore(version, newMap)
logInfo(s"Retrieved version $version of ${HDFSBackedStateStoreProvider.this} for update")
store
}
//向输出流(lz4文件)写入更新key、value
private def writeUpdateToDeltaFile(
output: DataOutputStream,
key: UnsafeRow,
value: UnsafeRow): Unit = {
val keyBytes = key.getBytes()
val valueBytes = value.getBytes()
output.writeInt(keyBytes.size)
output.write(keyBytes)
output.writeInt(valueBytes.size)
output.write(valueBytes)
}
//向输出流(lz4文件)写入删除的key
private def writeRemoveToDeltaFile(output: DataOutputStream, key: UnsafeRow): Unit = {
val keyBytes = key.getBytes()
output.writeInt(keyBytes.size)
output.write(keyBytes)
output.writeInt(-1)
}
//写入结束符,关闭输出流
private def finalizeDeltaFile(output: DataOutputStream): Unit = {
output.writeInt(-1) // Write this magic number to signify end of file
output.close()
}上述getStore()被调用的顺序:
//StateStoreRDD:
override def compute(partition: Partition, ctxt: TaskContext): Iterator[U] = {
var store: StateStore = null
val storeProviderId = StateStoreProviderId(
StateStoreId(checkpointLocation, operatorId, partition.index),
queryRunId)
//根据storeVersion获取store
store = StateStore.get(
storeProviderId, keySchema, valueSchema, indexOrdinal, storeVersion,
storeConf, hadoopConfBroadcast.value.value)
val inputIter = dataRDD.iterator(partition, ctxt)
storeUpdateFunction(store, inputIter)
}
//StateStore:
def get(
storeProviderId: StateStoreProviderId,
keySchema: StructType,
valueSchema: StructType,
indexOrdinal: Option[Int],
version: Long,
storeConf: StateStoreConf,
hadoopConf: Configuration): StateStore = {
require(version >= 0)
val storeProvider = loadedProviders.synchronized {
startMaintenanceIfNeeded()
val provider = loadedProviders.getOrElseUpdate(
storeProviderId,
StateStoreProvider.createAndInit(
storeProviderId.storeId, keySchema, valueSchema, indexOrdinal, storeConf, hadoopConf)
)
reportActiveStoreInstance(storeProviderId)
provider
}
//根据provider获取store
storeProvider.getStore(version)
}HDFSBackedStateStore内部重要的成员变量和方法:
//version为版本,mapToUpdate即上述getStore()创建的map数据
class HDFSBackedStateStore(val version: Long, mapToUpdate: MapType)
extends StateStore {
//delta文件的临时路径
private val tempDeltaFile = new Path(baseDir, s"temp-${Random.nextLong}")
//根据输出文件路径创建lz4输出流
private lazy val tempDeltaFileStream = compressStream(fs.create(tempDeltaFile, true))
//当前stateStore的状态,一般是UPDATING和COMMITTED,COMMITTED以后不再允许提交更新数据
@volatile private var state: STATE = UPDATING
//写数据完成后tempDeltaFile 通过rename方式,命名为${version}.delta文件
@volatile private var finalDeltaFile: Path = null
//根据key获取值
override def get(key: UnsafeRow): UnsafeRow = {
mapToUpdate.get(key)
}
//以拷贝方式,更新值,同时写入文件
override def put(key: UnsafeRow, value: UnsafeRow): Unit = {
verify(state == UPDATING, "Cannot put after already committed or aborted")
val keyCopy = key.copy()
val valueCopy = value.copy()
mapToUpdate.put(keyCopy, valueCopy)
writeUpdateToDeltaFile(tempDeltaFileStream, keyCopy, valueCopy)
}
//删除值,同时将删除动作写入文件
override def remove(key: UnsafeRow): Unit = {
verify(state == UPDATING, "Cannot remove after already committed or aborted")
val prevValue = mapToUpdate.remove(key)
if (prevValue != null) {
writeRemoveToDeltaFile(tempDeltaFileStream, key)
}
}
//一般是StateStoreSaveExec在计算过程中,先获取全部数据val rangeIter = store.getRange(None, None),再将过期的数据写出
override def getRange(
start: Option[UnsafeRow],
end: Option[UnsafeRow]): Iterator[UnsafeRowPair] = {
verify(state == UPDATING, "Cannot getRange after already committed or aborted")
iterator()
}四、对statestore数据的更新(删除)及过期数据的写出
- 一、持续更新的无限表
- 二、创建StatefulAggregationStrategy流计算聚合策略
- 1、先简单介绍下spark sql对应的QueryExecution
- 2、IncrementalExecution对QueryExecution的扩展,生成流计算相关策略
- 三、statestore聚合状态存储
- 四、对statestore数据的更新(删除)及过期数据的写出
- StateStoreRestoreExec实现当前批次聚合数据与历史聚合数据的union过程
① 对于当前批聚合数据,依次GenerateUnsafeProjection方式生成key,并根据key获取上一个版本store的数据(savedState),最后返回的Option(savedState).toSeq :+ row是一个Seq[InternalRow]
② 关注mapPartitionsWithStateStore()的实现,其内部创建了一个StateStoreRDD,并执行前两个步骤对应的storeUpdateFunction函数
③ 从这里可以看到,Seq[InternalRow]还需要PartialMerge过程,将分区中key值相同的value合并,经过合并过程,数据进入StateStoreSaveExec定义的数据以Update、Append方式写出流程。
case class StateStoreRestoreExec(
keyExpressions: Seq[Attribute],
stateInfo: Option[StatefulOperatorStateInfo],
child: SparkPlan)
extends UnaryExecNode with StateStoreReader {
override protected def doExecute(): RDD[InternalRow] = {
val numOutputRows = longMetric("numOutputRows")
child.execute().mapPartitionsWithStateStore(
getStateInfo,
keyExpressions.toStructType,
child.output.toStructType,
indexOrdinal = None,
sqlContext.sessionState,
Some(sqlContext.streams.stateStoreCoordinator)) { case (store, iter) =>
val getKey = GenerateUnsafeProjection.generate(keyExpressions, child.output)
val hasInput = iter.hasNext
if (!hasInput && keyExpressions.isEmpty) {
// If our `keyExpressions` are empty, we're getting a global aggregation. In that case
// the `HashAggregateExec` will output a 0 value for the partial merge. We need to
// restore the value, so that we don't overwrite our state with a 0 value, but rather
// merge the 0 with existing state.
store.iterator().map(_.value)
} else {
iter.flatMap { row =>
val key = getKey(row)
val savedState = store.get(key)
numOutputRows += 1
Option(savedState).toSeq :+ row
}
}
}
}- StateStoreSaveExec实现聚合状态的写出(Complete、Append、Update):
① 三种输出方式都是先以put方式更新stateStore,然后根据自身输出模式的特征,对比watermark进行聚合数据的操作
② Complete模式:使用场景较少,即先更新stateStore,后输出所有的聚合数据
③ Append模式:以FileStreamSink写每分钟出到文件为参照,FileStreamSink强制指定为此模式。首先使用!watermarkPredicateForData.get.eval(row)将未过期的有效数据,更新到stateStore,然后将stateStore中所有数据对比watermarkPredicateForKeys.get.eval(row),获取到过期的数据,生成一个iterator,这个迭代器就是,当前批次要写出到文件的内容(生成iterator同时在stateStore中删除这条过期数据)。
④ Update模式:以ConsoleSink调试模式,输出当前批次数据为参照,new IteratorInternalRow会先调用next()方法,将baseIterator(未过期的有效数据),更新到stateStore(next()方法同时返回当前row,参与后续计算,这是与Append模式的区别,Append模式返回的是过期数据的iterator),然后在判断!hasNext(),即运算结束时,调用removeKeysOlderThanWatermark(store),删除所有的过期数据。
case class StateStoreSaveExec(
keyExpressions: Seq[Attribute],
stateInfo: Option[StatefulOperatorStateInfo] = None,
outputMode: Option[OutputMode] = None,
eventTimeWatermark: Option[Long] = None,
child: SparkPlan)
extends UnaryExecNode with StateStoreWriter with WatermarkSupport {
override protected def doExecute(): RDD[InternalRow] = {
child.execute().mapPartitionsWithStateStore(
getStateInfo,
keyExpressions.toStructType,
child.output.toStructType,
indexOrdinal = None,
sqlContext.sessionState,
Some(sqlContext.streams.stateStoreCoordinator)) { (store, iter) =>
val getKey = GenerateUnsafeProjection.generate(keyExpressions, child.output)
outputMode match {
// Update and output all rows in the StateStore.
// Complete模式,先更新stateStore,然后输出所有数据
case Some(Complete) =>
allUpdatesTimeMs += timeTakenMs {
while (iter.hasNext) {
val row = iter.next().asInstanceOf[UnsafeRow]
val key = getKey(row)
store.put(key, row)
numUpdatedStateRows += 1
}
}
allRemovalsTimeMs += 0
commitTimeMs += timeTakenMs {
store.commit()
}
setStoreMetrics(store)
store.iterator().map { rowPair =>
numOutputRows += 1
rowPair.value
}
// Update and output only rows being evicted from the StateStore
// Assumption: watermark predicates must be non-empty if append mode is allowed
case Some(Append) =>
allUpdatesTimeMs += timeTakenMs {
// Append模式,先更新所有未过期有效数据
val filteredIter = iter.filter(row => !watermarkPredicateForData.get.eval(row))
while (filteredIter.hasNext) {
val row = filteredIter.next().asInstanceOf[UnsafeRow]
val key = getKey(row)
store.put(key, row)
numUpdatedStateRows += 1
}
}
val removalStartTimeNs = System.nanoTime
val rangeIter = store.getRange(None, None)
// 删除stateStore中过期数据,同时removedValueRow被删除数据返回为iterator,参与后续计算,被FileSink写出
new NextIterator[InternalRow] {
override protected def getNext(): InternalRow = {
var removedValueRow: InternalRow = null
while(rangeIter.hasNext && removedValueRow == null) {
val rowPair = rangeIter.next()
if (watermarkPredicateForKeys.get.eval(rowPair.key)) {
store.remove(rowPair.key)
removedValueRow = rowPair.value
}
}
if (removedValueRow == null) {
finished = true
null
} else {
removedValueRow
}
}
// Update and output modified rows from the StateStore.
case Some(Update) =>
val updatesStartTimeNs = System.nanoTime
new Iterator[InternalRow] {
// Filter late date using watermark if specified
private[this] val baseIterator = watermarkPredicateForData match {
case Some(predicate) => iter.filter((row: InternalRow) => !predicate.eval(row))
case None => iter
}
override def hasNext: Boolean = {
// 在baseIterator结束时,调用removeKeysOlderThanWatermark(store)删除stateStore中过期数据。
if (!baseIterator.hasNext) {
allUpdatesTimeMs += NANOSECONDS.toMillis(System.nanoTime - updatesStartTimeNs)
// Remove old aggregates if watermark specified
allRemovalsTimeMs += timeTakenMs { removeKeysOlderThanWatermark(store) }
commitTimeMs += timeTakenMs { store.commit() }
setStoreMetrics(store)
false
} else {
true
}
}
// 先更新所有baseIterator中未过期有效数据,将当前row返回为iterator
override def next(): InternalRow = {
val row = baseIterator.next().asInstanceOf[UnsafeRow]
val key = getKey(row)
store.put(key, row)
numOutputRows += 1
numUpdatedStateRows += 1
row
}
}
case _ => throw new UnsupportedOperationException(s"Invalid output mode: $outputMode")
}
}
}
}