Spark Structrued Streaming源码分析--(一)创建Source、Sink及自定义输入、输出端
- 一、流计算示例example
- 二、通过DataStreamReader.load()方法,查找Source并创建DataFrame
- 1、DataStreamReader参数设置:
- 2、DataStreamReader.load()查找source并创建dataframe
- I) DataSource.lookupDataSource(),通过class全路径或预定义的简写,查找source provider class
- II) DataSource.apply()提供的构造方法,将provider和option信息存入DataSource中
- III) Dataset.ofRows()创建resolved逻辑执行计划
- 3、自定义source示例
- 三、通过dataStreamWriter.start()方法,创建sink并启动流计算持续查询线程
- 1、DataStreamWriter参数设置:
- 2、DataStreamWriter.start()创建sink并启动查询线程
- 3、自定义Sink示例
一、流计算示例example
从Kafka Topic读取记录行,统计单词个数,并写出到console控制台
val dataStreamReader: DataStreamReader = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", bootstrapServers)
.option(subscribeType, topics)
val lines: Dataset[String] = dataStreamReader
.load()
.selectExpr("CAST(value AS STRING)")
.as[String]
// Generate running word count
val wordCounts = lines.flatMap(_.split(" ")).groupBy("value").count()
// Start running the query that prints the running counts to the console
val dataStreamWriter: DataStreamWriter[Row] = wordCounts.writeStream
.outputMode("complete")
.format("console")
.option("checkpointLocation", checkpointLocation)
val query = dataStreamWriter.start()
query.awaitTermination()示例中分为以下步骤:
① dataStreamReader.load()方法查找source,并创建dataframe
② 数据(dataframe) transform
③ dataStreamWriter创建sink,并启动流计算持续查询线程。
dataStreamReader.load()和dataStreamWriter.start()是本文分析的重点。
数据(Dataset) transform转换过程即常用的spark sql api (selectExpr、select、map、flatmap等),本文不另作分析。
二、通过DataStreamReader.load()方法,查找Source并创建DataFrame
- 一、流计算示例example
- 二、通过DataStreamReader.load()方法,查找Source并创建DataFrame
- 1、DataStreamReader参数设置:
- 2、DataStreamReader.load()查找source并创建dataframe
- I) DataSource.lookupDataSource(),通过class全路径或预定义的简写,查找source provider class
- II) DataSource.apply()提供的构造方法,将provider和option信息存入DataSource中
- III) Dataset.ofRows()创建resolved逻辑执行计划
- 3、自定义source示例
- 三、通过dataStreamWriter.start()方法,创建sink并启动流计算持续查询线程
- 1、DataStreamWriter参数设置:
- 2、DataStreamWriter.start()创建sink并启动查询线程
- 3、自定义Sink示例
1、DataStreamReader参数设置:
通过调用DataStreamReader 提供的format()、option()方法,可以设置reader的各项参数
其设置的option数据主要保存在的extraOptions: HashMap[String, String]中
final class DataStreamReader private[sql](sparkSession: SparkSession) extends Logging {
def format(source: String): DataStreamReader = {
this.source = source
this
}
def option(key: String, value: String): DataStreamReader = {
this.extraOptions += (key -> value)
this
}
private var source: String = sparkSession.sessionState.conf.defaultDataSourceName
private var userSpecifiedSchema: Option[StructType] = None
private var extraOptions = new scala.collection.mutable.HashMap[String, String]
}2、DataStreamReader.load()查找source并创建dataframe
load()方法主要步骤
· 通过DataSource.lookupDataSource(source, conf)查找kafka、file、com.it.provider.source.HbaseSource对应的provider类,并生成实例
· 生成v1DataSource、v1Relation,其中v1Relation主要是用于构建StreamingRelationV2,批处理方式不会调用StreamingRelationV2相关的case
· 调用Dataset.ofRows()方法,使用v1DataSource创建dataframe
def load(): DataFrame = {
if (source.toLowerCase(Locale.ROOT) == DDLUtils.HIVE_PROVIDER) {
throw new AnalysisException("Hive data source can only be used with tables, you can not " +
"read files of Hive data source directly.")
}
val ds = DataSource.lookupDataSource(source, sparkSession.sqlContext.conf).newInstance()
val options = new DataSourceOptions(extraOptions.asJava)
val v1DataSource = DataSource(
sparkSession,
userSpecifiedSchema = userSpecifiedSchema,
className = source,
options = extraOptions.toMap)
val v1Relation = ds match {
case _: StreamSourceProvider => Some(StreamingRelation(v1DataSource))
case _ => None
}
ds match {
case s: MicroBatchReadSupport =>
val tempReader = s.createMicroBatchReader(
Optional.ofNullable(userSpecifiedSchema.orNull),
Utils.createTempDir(namePrefix = s"temporaryReader").getCanonicalPath,
options)
Dataset.ofRows(
sparkSession,
StreamingRelationV2(
s, source, extraOptions.toMap,
tempReader.readSchema().toAttributes, v1Relation)(sparkSession))
case s: ContinuousReadSupport =>
val tempReader = s.createContinuousReader(
Optional.ofNullable(userSpecifiedSchema.orNull),
Utils.createTempDir(namePrefix = s"temporaryReader").getCanonicalPath,
options)
Dataset.ofRows(
sparkSession,
StreamingRelationV2(
s, source, extraOptions.toMap,
tempReader.readSchema().toAttributes, v1Relation)(sparkSession))
case _ =>
// Code path for data source v1.
Dataset.ofRows(sparkSession, StreamingRelation(v1DataSource))
}
}I) DataSource.lookupDataSource(),通过class全路径或预定义的简写,查找source provider class
DataSource.lookupDataSource()查找Provider class有三种逻辑实现:
· 系统中已预定义的KafkaSource,通过_.shortName().equalsIgnoreCase(provider1)匹配,输入为“kafka”。
· json、csv、paraquet格式,对应的provider映射在backwardCompatibilityMap中定义。
· 自定义的provider可以通过loader.loadClass(provider1),查找上下文中全路径对应class即可,例如指定source:org.apache.spark.sql.usersource.HbaseSourceProvider。
def lookupDataSource(provider: String, conf: SQLConf): Class[_] = {
// 形如kafka或org.apache.spark.sql.usersource.HbaseSourceProvider
val provider1 = backwardCompatibilityMap.getOrElse(provider, provider) match {
case name if name.equalsIgnoreCase("orc") &&
conf.getConf(SQLConf.ORC_IMPLEMENTATION) == "native" =>
classOf[OrcFileFormat].getCanonicalName
case name if name.equalsIgnoreCase("orc") &&
conf.getConf(SQLConf.ORC_IMPLEMENTATION) == "hive" =>
"org.apache.spark.sql.hive.orc.OrcFileFormat"
case name => name
}
val provider2 = s"$provider1.DefaultSource"
val loader = Utils.getContextOrSparkClassLoader
val serviceLoader = ServiceLoader.load(classOf[DataSourceRegister], loader)
try {// 找shortName()为kafka的情形
serviceLoader.asScala.filter(_.shortName().equalsIgnoreCase(provider1)).toList match {
// the provider format did not match any given registered aliases
case Nil =>
try {//自定义org.apache.spark.sql.usersource.HbaseSourceProvider情形,直接加载provider1对应的class
try(loader.loadClass(provider1)).orElse(Try(loader.loadClass(provider2))) match {
case Success(dataSource) =>
// Found the data source using fully qualified path
dataSource
case Failure(error) =>
}
} catch {
}
// 匹配到shortName()为kafka的情形
case head :: Nil =>
// there is exactly one registered alias
head.getClass
case sources =>
}
} catch {
}
}II) DataSource.apply()提供的构造方法,将provider和option信息存入DataSource中
创建v1Source:
val v1DataSource = DataSource(
sparkSession,
userSpecifiedSchema = userSpecifiedSchema,
className = source,
options = extraOptions.toMap)DataSource自动调用lookupDataSource()创建providingClass
DataSource提供了createSource()方法,在MicroBatchExecution创建sources过程会调用,下一篇文章分析这部分内容
case class DataSource(
sparkSession: SparkSession,
className: String,
paths: Seq[String] = Nil,
userSpecifiedSchema: Option[StructType] = None,
partitionColumns: Seq[String] = Seq.empty,
bucketSpec: Option[BucketSpec] = None,
options: Map[String, String] = Map.empty,
catalogTable: Option[CatalogTable] = None) extends Logging {
lazy val providingClass: Class[_] =
DataSource.lookupDataSource(className, sparkSession.sessionState.conf)
lazy val sourceInfo: SourceInfo = sourceSchema()
private val caseInsensitiveOptions = CaseInsensitiveMap(options)
def createSource(metadataPath: String): Source = {
providingClass.newInstance() match {
case s: StreamSourceProvider =>
s.createSource(
sparkSession.sqlContext,
metadataPath,
userSpecifiedSchema,
className,
caseInsensitiveOptions)
case format: FileFormat =>
val path = caseInsensitiveOptions.getOrElse("path", {
throw new IllegalArgumentException("'path' is not specified")
})
new FileStreamSource(
sparkSession = sparkSession,
path = path,
fileFormatClassName = className,
schema = sourceInfo.schema,
partitionColumns = sourceInfo.partitionColumns,
metadataPath = metadataPath,
options = caseInsensitiveOptions)
case _ =>
throw new UnsupportedOperationException(
s"Data source $className does not support streamed reading")
}
}
}
}III) Dataset.ofRows()创建resolved逻辑执行计划
Dataset.ofRows(sparkSession, StreamingRelation(v1DataSource))创建dataframe过程:
· 创建qe:QueryExecution,其内部流程参考https://blog.csdn.net/LS_ice/article/details/82153384 [流计算聚合策略的创建]
· qe.assertAnalyzed()生成analyzed(即resolved)逻辑执行计划
· new Dataset[Row]创建dataframe
class Dataset[T] private[sql](
@transient val sparkSession: SparkSession,
@DeveloperApi @InterfaceStability.Unstable @transient val queryExecution: QueryExecution,
encoder: Encoder[T])
extends Serializable {
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame = {
val qe = sparkSession.sessionState.executePlan(logicalPlan)
qe.assertAnalyzed()
new Dataset[Row](sparkSession, qe, RowEncoder(qe.analyzed.schema))
}
}3、自定义source示例
· 参照spark源码中已有的KafkaSouceProvider,创建一个自定义的KafkaSourceCachedProvider
· 实现shortName()、sourceSchema()、createSource()则三个接口
· 设置dataStreamRead.format(“org.apache.spark.sql.kafka010.usersource.KafkaSourceCachedProvider”)
class KafkaSourceCachedProvider extends DataSourceRegister
with StreamSourceProvider {
override def shortName(): String = this.getClass.getName
override def sourceSchema(sqlContext: SQLContext,
schema: Option[StructType],
providerName: String,
parameters: Map[String, String]): (String, StructType) = {
require(schema.isEmpty, "Kafka source has a fixed schema and cannot be set with a custom one")
(shortName(), KafkaOffsetReader.kafkaSchema)
}
override def createSource(sqlContext: SQLContext,
metadataPath: String,
schema: Option[StructType],
providerName: String,
parameters: Map[String, String]): Source = {
val uniqueGroupId = s"spark-kafka-source-${UUID.randomUUID}-${metadataPath.hashCode}"
val caseInsensitiveParams = parameters.map { case (k, v) => (k.toLowerCase(Locale.ROOT), v) }
val specifiedKafkaParams =
parameters
.keySet
.filter(_.toLowerCase(Locale.ROOT).startsWith("kafka."))
.map { k => k.drop(6).toString -> parameters(k) }
.toMap
val startingStreamOffsets = KafkaSourceProvider.getKafkaOffsetRangeLimit(caseInsensitiveParams,
KafkaSourceCachedProvider.STARTING_OFFSETS_OPTION_KEY, LatestOffsetRangeLimit)
val kafkaOffsetReader = new KafkaOffsetReader(
strategy(caseInsensitiveParams),
KafkaSourceCachedProvider.kafkaParamsForDriver(specifiedKafkaParams),
parameters,
driverGroupIdPrefix = s"$uniqueGroupId-driver")
println("-------------->create KafkaSourceCachedProvider.")
new KafkaSourceCached(
sqlContext,
kafkaOffsetReader,
KafkaSourceCachedProvider.kafkaParamsForExecutors(specifiedKafkaParams, uniqueGroupId),
parameters,
metadataPath,
startingStreamOffsets,
failOnDataLoss(caseInsensitiveParams))
}
}创建source class:
class KafkaSourceCached(sqlContext: SQLContext,
kafkaReader: KafkaOffsetReader,
executorKafkaParams: ju.Map[String, Object],
sourceOptions: Map[String, String],
metadataPath: String,
startingOffsets: KafkaOffsetRangeLimit,
failOnDataLoss: Boolean) extends Source with Logging {
override def schema: StructType = KafkaOffsetReader.kafkaSchema
override def getOffset: Option[Offset] = {
// to do:
//参考KafkaSource的实现,获取当前kafka topic各分区最大可用偏移量
}
override def getBatch(start: Option[Offset], end: Offset, currentBatchId: Long): DataFrame = {
// to do:
//参考KafkaSource的实现,将start至end offset区间的数据,依次生成KafkaSourceRDD和Dataframe
}
}三、通过dataStreamWriter.start()方法,创建sink并启动流计算持续查询线程
- 一、流计算示例example
- 二、通过DataStreamReader.load()方法,查找Source并创建DataFrame
- 1、DataStreamReader参数设置:
- 2、DataStreamReader.load()查找source并创建dataframe
- I) DataSource.lookupDataSource(),通过class全路径或预定义的简写,查找source provider class
- II) DataSource.apply()提供的构造方法,将provider和option信息存入DataSource中
- III) Dataset.ofRows()创建resolved逻辑执行计划
- 3、自定义source示例
- 三、通过dataStreamWriter.start()方法,创建sink并启动流计算持续查询线程
- 1、DataStreamWriter参数设置:
- 2、DataStreamWriter.start()创建sink并启动查询线程
- 3、自定义Sink示例
1、DataStreamWriter参数设置:
通过调用DataStreamWriter 提供的format()、option()、queryName()、partitionBy()、trigger()、outputMode()方法,可以设置writer的各项参数
其设置的option数据主要保存在的extraOptions: HashMap[String, String]中
2、DataStreamWriter.start()创建sink并启动查询线程
start()方法的内部流程
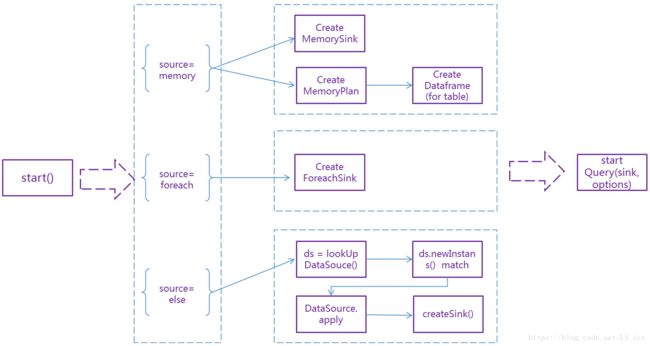
def start(): StreamingQuery = {
if (source == "memory") {
val (sink, resultDf) = trigger match {
case _: ContinuousTrigger =>
val s = new MemorySinkV2()
val r = Dataset.ofRows(df.sparkSession, new MemoryPlanV2(s, df.schema.toAttributes))
(s, r)
case _ =>
val s = new MemorySink(df.schema, outputMode)
// 创建Dataframe是为了使用createOrReplaceTempView()绑定到table
val r = Dataset.ofRows(df.sparkSession, new MemoryPlan(s))
(s, r)
}
val chkpointLoc = extraOptions.get("checkpointLocation")
val recoverFromChkpoint = outputMode == OutputMode.Complete()
val query = df.sparkSession.sessionState.streamingQueryManager.startQuery(
extraOptions.get("queryName"),
chkpointLoc,
df,
extraOptions.toMap,
sink,
outputMode,
useTempCheckpointLocation = true,
recoverFromCheckpointLocation = recoverFromChkpoint,
trigger = trigger)
resultDf.createOrReplaceTempView(query.name)
query
} else if (source == "foreach") {
assertNotPartitioned("foreach")
// 设置应用层的foreachWriter
val sink = new ForeachSink[T](foreachWriter)(ds.exprEnc)
df.sparkSession.sessionState.streamingQueryManager.startQuery(
extraOptions.get("queryName"),
extraOptions.get("checkpointLocation"),
df,
extraOptions.toMap,
sink,
outputMode,
useTempCheckpointLocation = true,
trigger = trigger)
} else {
// lookup过程,查找内置或自定义provider
val ds = DataSource.lookupDataSource(source, df.sparkSession.sessionState.conf)
val disabledSources = df.sparkSession.sqlContext.conf.disabledV2StreamingWriters.split(",")
// match匹配并创建sink
val sink = ds.newInstance() match {
case w: StreamWriteSupport if !disabledSources.contains(w.getClass.getCanonicalName) => w
case _ =>
val ds = DataSource(
df.sparkSession,
className = source,
options = extraOptions.toMap,
partitionColumns = normalizedParCols.getOrElse(Nil))
ds.createSink(outputMode)
}
// 启动Query线程
df.sparkSession.sessionState.streamingQueryManager.startQuery(
extraOptions.get("queryName"),
extraOptions.get("checkpointLocation"),
df,
extraOptions.toMap,
sink,
outputMode,
useTempCheckpointLocation = source == "console",
recoverFromCheckpointLocation = true,
trigger = trigger)
}
}· source == “memory”情形,每个批次的数据会通过collect()方法收集到driver,但并没有实现数据的清理机制,会导致内存不断增加,是一个测试sink
· 我们扩展了source == “memoryExtend”,增加了数据根据设置的时间戳字段,清理过期数据功能
3、自定义Sink示例
创建SinkProvider class、Sink class
配置dataStreamWriter.format(“org.apache.sql.usersink.FileSinkExtendProvider”)
class FileSinkExtendProvider extends DataSourceRegister with StreamSinkProvider with Logging {
override def shortName(): String = {
this.getClass.getName
}
override def createSink(
sqlContext: SQLContext,
parameters: Map[String, String],
partitionColumns: Seq[String],
outputMode: OutputMode): Sink = {
println(s"FileSinkExtendProvider create FileSinkExtend.")
new FileSinkExtend(sqlContext, parameters, partitionColumns, outputMode)
}
}创建Sink class
class FileSinkExtend(
sqlContext: SQLContext,
parameters: Map[String, String],
partitionColumns: Seq[String],
outputMode: OutputMode) extends Sink with Logging {
override def addBatch(
batchId: Long,
data: DataFrame,
offsetTuple: (Option[Offset], Option[Offset])): Unit = {
println(s"FileSinkExtend add batch, data:")
val rows = data.collect()
println(s"rows length:" + rows.length)
rows.take(10).foreach(row => println(s"row is :" + row.toString()))
}
}