TensorFlow初尝试:CNN for Text Classification
1. Graph and Session in TensorFlow
import tensorflow as tf
# create a graph, and define a constant in it
with tf.Graph().as_default() as g:
c = tf.constant(1.0)
# define a tensor in the default graph
t = tf.zeros([4, 4])
with tf.Session() as sess:
assert t.graph == tf.get_default_graph()
assert c.graph == g
with语句结束后Graph g, Session sess并不会被清除。不定义在指定Graph中的变量,会被定义在default graph中;而在Graph中定义的变量所在的图即为指定的graph。

如果不在sess中对相应的操作、变量等run的话,是无法获取其对应值的。
with tf.Session() as sess:
t_value = sess.run(t)
c_value = sess.run(c) # raise error
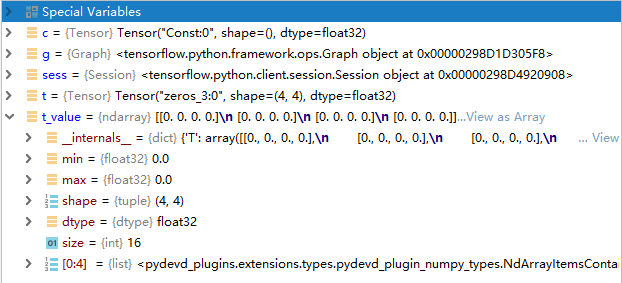
上面报错的原因是,因为c定义在with tf.Graph().as_default() as g:中会导致两次创建的图不一样。
2. TensorFlow构建模型流程
1. 新建网络的类
将网络结构定义成一个类,将网络的参数作为class的成员变量,将网络的操作作为成员函数。
class TextCNN(object):
def __init__(self, filter_sizes, filter_nums, embedding_size, vocab_size, max_length, num_classes):
self.x_input = tf.placeholder(tf.int32, [None, max_length], name='x_input')
self.y_input = tf.placeholder(tf.int32, [None, num_classes], name='y_input')
with tf.device('/cpu:0'), tf.name_scope("embedding"):
# Map scalars from x_input into random vectors
embedding_matrix = tf.Variable(tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0), name="embedding_matrix")
embedded_chars = tf.nn.embedding_lookup(embedding_matrix, self.x_input)
embedded_chars_expanded = tf.expand_dims(embedded_chars, -1)
result_pooled = []
for filter_size, filter_num in zip(filter_sizes, filter_nums):
with tf.name_scope("conv-maxpool-%d" % filter_size):
filter_shape = [filter_size, embedding_size, 1, filter_num]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[filter_num]), name="b")
conv = tf.nn.conv2d(embedded_chars_expanded, W, strides=[1, 1, 1, 1], padding="VALID", name="conv")
# Add bias/ Apply nonlinearity/ the activation function
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Max-pooling over the outputs
pooled = tf.nn.max_pool(h, ksize=[1, max_length - filter_size + 1, 1, 1], strides=[1, 1, 1, 1], padding='VALID', name="pool")
result_pooled.append(pooled)
# Combine all the pooled features
num_filters_total = np.sum(filter_nums)
h_pool = tf.concat(result_pooled, axis=3)
h_pool_flat = tf.reshape(h_pool, [-1, num_filters_total])
# Dropout layer
h_drop = tf.nn.dropout(h_pool_flat, dropout_keep_prob, name='dropout')
# Fully connected layer
l2_loss = 0.0
W = tf.get_variable("W", shape=[num_filters_total, num_classes], initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
scores = tf.nn.xw_plus_b(h_drop, W, b, name="scores")
# Calculate mean cross-entropy loss
losses = tf.nn.softmax_cross_entropy_with_logits_v2(logits=scores, labels=self.y_input)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss
# Accuracy
predictions = tf.argmax(scores, 1, name="predictions")
correct_predictions = tf.equal(predictions, tf.argmax(self.y_input, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
TextCNN类没有定义其他的成员函数,全部定义在__init__函数中,传入的参数是一些与网络结构相关的超参数。
主要的成员变量需要定义:input (包括features和labels), loss,accuracy,loss和accuracy是input的函数。训练的时候run模型的loss,accuracy即可。
learning rate和optimizer是不在该类中进行定义的。
2. 处理数据集
# data pre-processing
def HandlePunctuation(str):
# 匹配任意不为A-Za-z0-9(),!?\'\`这些字符的符号,将其替换为" "
str = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", str)
str = re.sub(r"\'s", " \'s", str)
str = re.sub(r"\'ve", " \'ve", str)
str = re.sub(r"n\'t", " n\'t", str)
str = re.sub(r"\'re", " \'re", str)
str = re.sub(r"\'d", " \'d", str)
str = re.sub(r"\'ll", " \'ll", str)
str = re.sub(r",", " , ", str)
str = re.sub(r"!", " ! ", str)
str = re.sub(r"\(", " \( ", str)
str = re.sub(r"\)", " \) ", str)
str = re.sub(r"\?", " \? ", str)
str = re.sub(r"\s{2,}", " ", str)
return str.strip().lower()
def DataPreparation(pos_path, neg_path, val_percentage):
print("loading data...")
with open(pos_path, 'r', encoding='utf-8') as f:
x_pos = f.readlines()
with open(neg_path, 'r', encoding='utf-8') as f:
x_neg = f.readlines()
# strip '\n' in the end of every str, and handle the punctuations
x_pos = [HandlePunctuation(x.strip()) for x in x_pos]
x_neg = [HandlePunctuation(x.strip()) for x in x_neg]
# generate one_hot labels
y_pos = [[0, 1] for _ in range(len(x_pos))]
y_neg = [[1, 0] for _ in range(len(x_neg))]
y = np.concatenate([y_pos, y_neg], axis=0)
# map words into ids. There is no need to tokenize documents.
x_text = x_pos + x_neg # Not x_text = [x_pos, x_neg]
max_length = max([len(x.split()) for x in x_text])
vocab_processor = learn.preprocessing.VocabularyProcessor(max_length)
x = np.array(list(vocab_processor.fit_transform(x_text)))
# shuffle data
np.random.seed(63)
shuffle_index = np.random.permutation(np.arange(len(x))) # not np.random.shuffle
x_shuffled = x[shuffle_index]
y_shuffled = y[shuffle_index]
# split train/validation set
split_postion = int(val_percentage * len(x))
x_train, y_train = x_shuffled[split_postion:, :], y_shuffled[split_postion:, :]
x_val, y_val = x_shuffled[:split_postion, :], y_shuffled[:split_postion, :]
print("Data preparation is completed!\n")
vocab_size = vocab_processor.vocabulary_.__len__()
print("vocabulary size: %i"%vocab_size)
del x_pos, x_neg, x_shuffled, y_shuffled, x, y
return x_train, y_train, x_val, y_val, max_length, vocab_size
对原始数据集进行处理,包括分词,生成one-hot类标签,打乱数据,划分train set和 val set(也见有叫其为development set的)。
3. Batch生成器
def BatchGenerator(data, shuffle=True):
data_size = data.shape[0]
num_batches_per_epoch = data_size // batch_size + 1
# shuffle data every epoch
if shuffle is True:
shuffle_indices = np.random.permutation(np.arange(data_size))
data_shuffled = data[shuffle_indices]
else:
data_shuffled = data
# split out data for every batch
# 当for循环将range遍历之后,下一次调用BatchGenerator函数时,yield指向下一行,即跳出函数
for idx in range(num_batches_per_epoch):
start_pos = idx * batch_size
end_pos = min(start_pos + batch_size, data_size - 1)
yield data_shuffled[start_pos:end_pos]
此处的逻辑与训练过程中的循环有关。训练中包括一个epoch的大循环,小循环就是循环访问该BatchGenerator函数。每次循环中会访问BatchGenerator函数,但都会在函数内部的循环中,yield语句的下一行开始执行,执行到yeield语句时会返回一组训练数据(as a batch)。当数据集划分的batches读取完毕后,跳出小循环,开始下一次epoch大循环。
再次访问BatchGenerator时会从函数的第一行执行,对训练数据进行打乱。
4. 训练函数Trainer
def Trainer(x_train, y_train, x_val, y_val, max_length, num_classes, vocab_size):
data = np.array(list(zip(x_train, y_train)))
with tf.Graph().as_default() as g:
# session configuration
# with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as sess: 会打印出来一堆CPU,GPU的配置信息
# 设置了os.environ['CUDA_VISIBLE_DEVICES'] = '0' 即可
# session configuration
session_config = tf.ConfigProto(
log_device_placement=False,
allow_soft_placement=True,
)
session_config.gpu_options.allow_growth = True
with tf.Session(config=session_config) as sess:
# Class instantiation
cnn = TextCNN(
filter_sizes,
filter_nums,
embedding_size,
vocab_size,
max_length,
num_classes
)
# Set Saver
saver = tf.train.Saver(max_to_keep=5)
# 指数衰减学习率
# global decay_rate
global_step = tf.Variable(0, name="global_step", trainable=False)
lr = tf.train.exponential_decay(1e-2, global_step, decay_steps=20, decay_rate=decay_rate)
# Set Optimizer(如果在optimizer中不加global_step, 则global_step不自增,原因是minimize()函数为全局计数)
optimizer = tf.train.AdamOptimizer(lr)
train_op = optimizer.minimize(cnn.loss, global_step=global_step)
# Record summary
loss_summary = tf.summary.scalar('loss', cnn.loss)
acc_summary = tf.summary.scalar('accuracy', cnn.accuracy)
merged_summary = tf.summary.merge([loss_summary, acc_summary])
summary_writer_train = tf.summary.FileWriter(os.path.join(sum_path, 'train'), sess.graph)
summary_writer_val = tf.summary.FileWriter(os.path.join(sum_path, 'val'), sess.graph)
# Initialize all variables (这一句应该写在最后,run之前)
sess.run(tf.global_variables_initializer())
# check if checkpoint already exist
if tf.train.get_checkpoint_state(ckpt_path):
print("loading model from checkpoint...")
# load latest checkpoint
checkpoint = tf.train.latest_checkpoint(ckpt_path)
saver.restore(sess, checkpoint)
def train_step(x_batch, y_batch, train_op):
feed = {
cnn.x_input: x_batch,
cnn.y_input: y_batch,
}
# Set global variable decay_rate to control exponential-decay leaning rate
# global decay_rate
global step
_, step, learning_rate, loss, accuracy, summaries = sess.run( # 此处learning_rate如果命名为lr会报重名错误
[train_op, global_step, lr, cnn.loss, cnn.accuracy, merged_summary],
feed_dict=feed)
time_str = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("{} | step {:>5} | loss {:>9g} | acc {:>9g} | lr {:>5}".format(time_str, step, loss, accuracy, learning_rate))
summary_writer_train.add_summary(summaries, step)
def val_step(x_val, y_val):
feed = {
cnn.x_input: x_val,
cnn.y_input: y_val
}
global step
# Feed data to member variable of class TextCNN
loss, accuracy, summaries = sess.run([cnn.loss, cnn.accuracy, merged_summary], feed_dict=feed)
time_str = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("{} | step val | loss {:9g} | acc {:9g}".format(time_str, loss, accuracy), '\n')
summary_writer_val.add_summary(summaries, step)
return accuracy
acc_history = []
for ep in range(num_epoch):
print('\nepoch {:>4}'.format(ep))
batcher = BatchGenerator(data, shuffle=True)
for batch in batcher:
x_batch, y_batch = zip(*batch)
train_step(np.array(x_batch), np.array(y_batch), train_op)
cur_step = tf.train.global_step(sess, global_step)
if cur_step % val_interval == 0:
print('evaluating current model...')
acc_history.append(val_step(x_val, y_val))
# Save best model
if acc_history[-1] == max(acc_history):
print('save model checkpoint to %s\\\n'%ckpt_path)
saver.save(sess, os.path.join(ckpt_path, 'model-%s.ckpt'%str(int(time.time()))))
print('evaluating current model...')
val_step(x_val, y_val)
首先创建了一个默认图,在默认图中:1. 配置session; 2. 打开session,对网络类进行实例化; 3. 设置summary和saver,用来保存训练信息(主要是loss和accuracy)和checkpoints;4. 定义训练和验证操作的函数;5. 写循环进行训练,每个训练step记录summary,每隔val_interval对模型进行一次评价,并保存最佳模型(as a checkpoint)
在训练之前,需要检查ckpt_dir文件夹中是否已经有checkpoint文件,如果有,则可以直接载入之前训练过程中保存的模型,来接着训练。
5. 主函数main
def main(argv=None):
# Check if the paths to contain summary and checkpoint exist. if not, make directories
if not os.path.exists(sum_path):
os.makedirs(sum_path)
if not os.path.exists(ckpt_path):
os.mkdir(ckpt_path)
x_train, y_train, x_val, y_val, max_length, vocab_size = DataPreparation(pos_path, neg_path, val_percentage)
Trainer(x_train, y_train, x_val, y_val, max_length, num_classes, vocab_size)
if __name__ == '__main__':
tf.app.run()
在执行tf.app.run()的时候,需要先解析tf.app.FLAGS(相当于解析命令行),获得全局变量。
在main函数中确认保存summary,和checkpoint的目录是否存在,如果不存在,需要创建对应的目录。
3. 其他
1. TensorBoard
为了将实验结果可视化,利用保存的summary信息,在TensorBoard中进行展示。
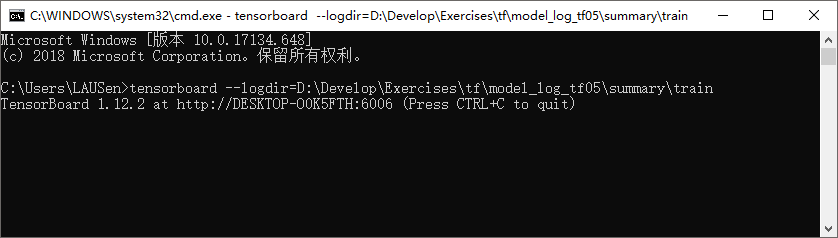
- win+R打开命令行窗口,输入:tensorboard --logdir=xxx,其中xxx是保存summary的地方文件目录(不必输入summary的文件名)
- 回车,得到一个网址: http://DESKTOP-O0K5FTH:6006。
- 保持命令行窗口打开,复制网址到浏览器,即可看到summary中保存的loss和accuracy的图像化展示。

2. CUDA assignment
# control the visibility of GPUs
os.environ['CUDA_VISIBLE_DEVICES'] = 0 # only gpu0 can be used, other device
# session configuration
session_config = tf.ConfigProto(
log_device_placement=False, # 是否打印设备分配日志
allow_soft_placement=True, # 如果指定设备不存在,允许TF自动分配设备
)
# control the occupancy of computing resource of your GPU:gradually increasing
session_config.gpu_options.allow_growth = True
with tf.Session(config=session_config) as sess:
pass
with tf.device(‘/gpu:0’):
# 程序将只会在gpu0上运行,但仍然会默认使用全部的计算资源
pass
3. 一些报错及解决方案
- loss急速增大,变为nan
考虑是梯度爆炸,或者是学习率过大的问题。实际上是因为指数衰减学习率的decay rate设置成了一个大于1的数,导致学习率指数上升。
# lr=tf.train.exponential_decay(1e-2,global_step,decay_steps=10,decay_rate=2)
lr=tf.train.exponential_decay(1e-2,global_step,decay_steps=20,decay_rate=0.95)
- UnknownError 一般只需要关闭IDE,再重启即可
UnknownError (see above for traceback): Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[node conv-maxpool-2/conv (defined at D:/Develop/Exercises/tf/tf05_cnn.py:131) = Conv2D[T=DT_FLOAT, data_format="NCHW", dilations=[1, 1, 1, 1], padding="VALID", strides=[1, 1, 1, 1], use_cudnn_on_gpu=true, _device="/job:localhost/replica:0/task:0/device:GPU:0"](gradients/conv-maxpool-5/conv_grad/Conv2DBackpropFilter-0-TransposeNHWCToNCHW-LayoutOptimizer, conv-maxpool-2/W/read)]]
[[{{node gradients/embedding/embedding_lookup_grad/Reshape/_29}} = _Recv[client_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name="edge_410_gradients/embedding/embedding_lookup_grad/Reshape", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]()]]
- 要把变量定义在同一个Graph下
因此建议除了超参数,其他的变量都在with tf.Graph().as_default_graph:中进行定义。
ValueError: Tensor("Adam/update_embedding/embedding_matrix/Sqrt:0", shape=(), dtype=float32, device=/device:CPU:0) must be from the same graph as Tensor("ExponentialDecay:0", shape=(), dtype=float32)
- 有变量定义在了
sess.run(tf.global_variables_initializer())之后,导致参数没有被初始化
FailedPreconditionError (see above for traceback): Attempting to use uninitialized value embedding/embedding_matrix/Adam
[[node embedding/embedding_matrix/Adam/read (defined at D:/Develop/Exercises/tf/tf05_cnn.py:212) = Identity[T=DT_FLOAT, _class=["loc:@Adam/update_embedding/embedding_matrix/AssignSub"], _device="/job:localhost/replica:0/task:0/device:CPU:0"](embedding/embedding_matrix/Adam)]]
- 定义main函数的时候要写
def main(argv=None):
只写def main(argv):会报错。
TypeError: main() takes 0 positional arguments but 1 was given
4. Jupyter Notebook
-
win + R: 进入命令行窗口;
-
输入: jupyter notebook,或ipython notebook
-
将在默认浏览器中弹出如下页面,找到.ipynb即可打开
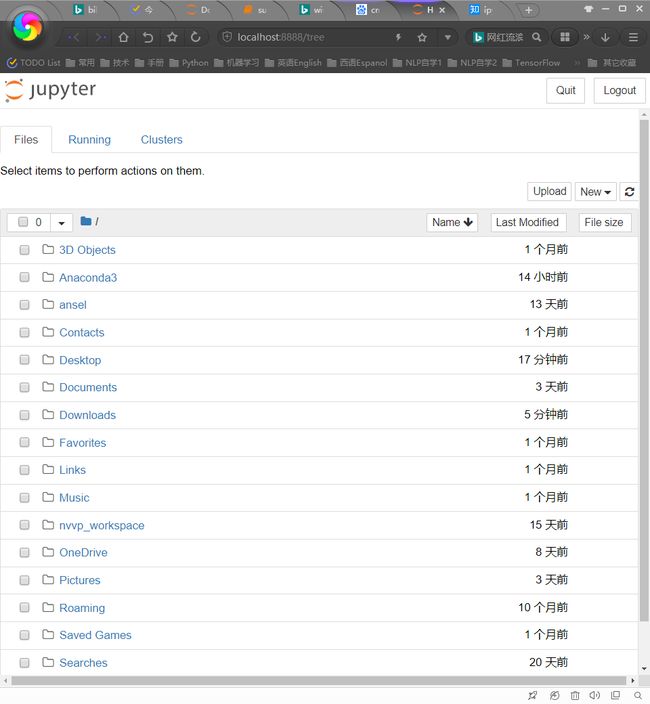
但是默认打开的是C盘目录,当此时.ipynb文件存放在其他盘符之下,就需要在命令行窗口中切换盘符,再输入jupyter notebook。如下所示:
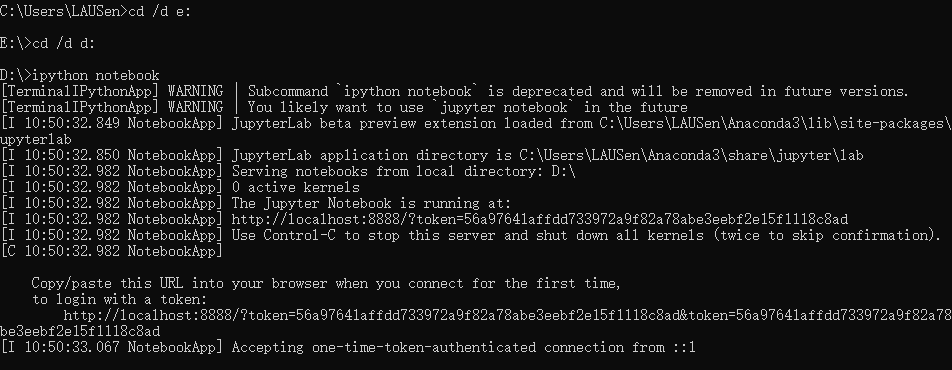
即可打开d盘目录: