Hive on Spark源码分析
1、Hive on Spark基本原理
1.1 运行模式
在之前的Hive on Spark原理的文档中已经对Hive on Spark 的运行流程进行了分析:
Hive on Spark支持两种运行模式,本地(local)和远程(remote):

当用户把Spark Master URL设置为local时,采用本地模式;其余情况采用远程模式。本地模式下,SparkContext与客户端运行在同一个JVM中;远程模式下,SparkContext运行在独立的JVM中。本地模式通常用于调试,所以主要分析远程模式。

1.2 Hive解析HQL
Hive的sql解析引擎会将每句sql解析成任务,并且根据不同的执行引擎调用不同子类去生成Task
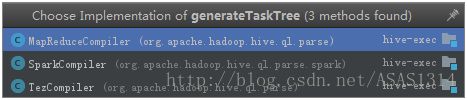
1.3 TaskCompile生成Task
在TaskCompile中去生成task的方法:
![]()
在SparkCompile中的实现,生成HQL执行的任务树:
protected void generateTaskTree(List extends Serializable>> rootTasks, ParseContext pCtx,
List> mvTask, Set inputs, Set outputs)
throws SemanticException {
PERF_LOGGER.PerfLogBegin(CLASS_NAME, PerfLogger.SPARK_GENERATE_TASK_TREE);
GenSparkUtils utils = GenSparkUtils.getUtils();
utils.resetSequenceNumber();
ParseContext tempParseContext = getParseContext(pCtx, rootTasks);
GenSparkProcContext procCtx = new GenSparkProcContext(
conf, tempParseContext, mvTask, rootTasks, inputs, outputs, pCtx.getTopOps());
// -------------------------------- First Pass ---------------------------------- //
// Identify SparkPartitionPruningSinkOperators, and break OP tree if necessary
Map opRules = new LinkedHashMap();
opRules.put(new RuleRegExp("Clone OP tree for PartitionPruningSink",
SparkPartitionPruningSinkOperator.getOperatorName() + "%"),
new SplitOpTreeForDPP());
Dispatcher disp = new DefaultRuleDispatcher(null, opRules, procCtx);
GraphWalker ogw = new GenSparkWorkWalker(disp, procCtx);
List topNodes = new ArrayList();
topNodes.addAll(pCtx.getTopOps().values());
ogw.startWalking(topNodes, null);
// -------------------------------- Second Pass ---------------------------------- //
// Process operator tree in two steps: first we process the extra op trees generated
// in the first pass. Then we process the main op tree, and the result task will depend
// on the task generated in the first pass.
topNodes.clear();
topNodes.addAll(procCtx.topOps.values());
generateTaskTreeHelper(procCtx, topNodes);
// If this set is not empty, it means we need to generate a separate task for collecting
// the partitions used.
if (!procCtx.clonedPruningTableScanSet.isEmpty()) {
SparkTask pruningTask = SparkUtilities.createSparkTask(conf);
SparkTask mainTask = procCtx.currentTask;
pruningTask.addDependentTask(procCtx.currentTask);
procCtx.rootTasks.remove(procCtx.currentTask);
procCtx.rootTasks.add(pruningTask);
procCtx.currentTask = pruningTask;
topNodes.clear();
topNodes.addAll(procCtx.clonedPruningTableScanSet);
generateTaskTreeHelper(procCtx, topNodes);
procCtx.currentTask = mainTask;
}
// -------------------------------- Post Pass ---------------------------------- //
// we need to clone some operator plans and remove union operators still
for (BaseWork w : procCtx.workWithUnionOperators) {
GenSparkUtils.getUtils().removeUnionOperators(procCtx, w);
}
// we need to fill MapWork with 'local' work and bucket information for SMB Join.
GenSparkUtils.getUtils().annotateMapWork(procCtx);
// finally make sure the file sink operators are set up right
for (FileSinkOperator fileSink : procCtx.fileSinkSet) {
GenSparkUtils.getUtils().processFileSink(procCtx, fileSink);
}
// Process partition pruning sinks
for (Operator> prunerSink : procCtx.pruningSinkSet) {
utils.processPartitionPruningSink(procCtx, (SparkPartitionPruningSinkOperator) prunerSink);
}
PERF_LOGGER.PerfLogEnd(CLASS_NAME, PerfLogger.SPARK_GENERATE_TASK_TREE);
} 2、Hive on Spark交互类图
插入图,说明:接下去的内容的交互顺序可参考此图。

3、源码分析
3.1 创建SparkTask
1、通过SparkUtilities创建SparkTask
2、SparkTask执行时代码
public int execute(DriverContext driverContext) {
int rc = 0;
perfLogger = SessionState.getPerfLogger();
SparkSession sparkSession = null;
SparkSessionManager sparkSessionManager = null;
try {
printConfigInfo();
sparkSessionManager = SparkSessionManagerImpl.getInstance();
sparkSession = SparkUtilities.getSparkSession(conf, sparkSessionManager);
SparkWork sparkWork = getWork();
sparkWork.setRequiredCounterPrefix(getOperatorCounters());
…
}3.2 创建SparkSession
1、过程中通过SparkSessionManager.getSession创建SparkSession
SparkUtilities.getSparkSession
public static SparkSession getSparkSession(HiveConf conf,
SparkSessionManager sparkSessionManager) throws HiveException {
SparkSession sparkSession = SessionState.get().getSparkSession();
HiveConf sessionConf = SessionState.get().getConf();
// Spark configurations are updated close the existing session
// In case of async queries or confOverlay is not empty,
// sessionConf and conf are different objects
if (sessionConf.getSparkConfigUpdated() || conf.getSparkConfigUpdated()) {
sparkSessionManager.closeSession(sparkSession);
sparkSession = null;
conf.setSparkConfigUpdated(false);
sessionConf.setSparkConfigUpdated(false);
}
sparkSession = sparkSessionManager.getSession(sparkSession, conf, true);
SessionState.get().setSparkSession(sparkSession);
return sparkSession;
}
1、SparkSessionManagerImpl中getSession
public SparkSession getSession(SparkSession existingSession, HiveConf conf, boolean doOpen)
throws HiveException {
setup(conf);
if (existingSession != null) {
// Open the session if it is closed.
if (!existingSession.isOpen() && doOpen) {
existingSession.open(conf);
}
return existingSession;
}
SparkSession sparkSession = new SparkSessionImpl();
if (doOpen) {
sparkSession.open(conf);
}
if (LOG.isDebugEnabled()) {
LOG.debug(String.format("New session (%s) is created.", sparkSession.getSessionId()));
}
createdSessions.add(sparkSession);
return sparkSession;
}3.3 实例化SparkSessionImpl
1、实例化SparkSessionImpl,调用open方法
2、创建一个SparkClient
SparkSessionImpl:
public void open(HiveConf conf) throws HiveException {
LOG.info("Trying to open Spark session {}", sessionId);
this.conf = conf;
isOpen = true;
try {
hiveSparkClient = HiveSparkClientFactory.createHiveSparkClient(conf, sessionId);
} catch (Throwable e) {
// It's possible that user session is closed while creating Spark client.
String msg = isOpen ? "Failed to create Spark client for Spark session " + sessionId :
"Spark Session " + sessionId + " is closed before Spark client is created";
throw new HiveException(msg, e);
}
LOG.info("Spark session {} is successfully opened", sessionId);
}1、HiveSparkClientFactory中createHiveSparkClient方法实现
HiveSparkClientFactory:
public static HiveSparkClient createHiveSparkClient(HiveConf hiveconf, String sessionId) throws Exception {
Map<String, String> sparkConf = initiateSparkConf(hiveconf, sessionId);
// Submit spark job through local spark context while spark master is local mode, otherwise submit
// spark job through remote spark context.
String master = sparkConf.get("spark.master");
if (master.equals("local") || master.startsWith("local[")) {
// With local spark context, all user sessions share the same spark context.
return LocalHiveSparkClient.getInstance(generateSparkConf(sparkConf), hiveconf);
} else {
return new RemoteHiveSparkClient(hiveconf, sparkConf);
}
}3.4实例化RemoteHiveSparkClient
1、其中留意一下,initiateSparkConf会初始化Spark运行环境的一些参数,后面的内容中提到。
2、实例化RemoteHiveSparkClient:
RemoteHiveSparkClient(HiveConf hiveConf, Map conf) throws Exception {
this.hiveConf = hiveConf;
sparkClientTimtout = hiveConf.getTimeVar(HiveConf.ConfVars.SPARK_CLIENT_FUTURE_TIMEOUT,
TimeUnit.SECONDS);
sparkConf = HiveSparkClientFactory.generateSparkConf(conf);
this.conf = conf;
createRemoteClient();
} 3.5 创建RemoteClient
1、调用createRemoteClient方法创建RemoteClient
private void createRemoteClient() throws Exception {
remoteClient = SparkClientFactory.createClient(conf, hiveConf);
if (HiveConf.getBoolVar(hiveConf, ConfVars.HIVE_PREWARM_ENABLED) &&
(SparkClientUtilities.isYarnMaster(hiveConf.get("spark.master")) ||
SparkClientUtilities.isLocalMaster(hiveConf.get("spark.master")))) {
int minExecutors = getExecutorsToWarm();
if (minExecutors <= 0) {
return;
}
LOG.info("Prewarm Spark executors. The minimum number of executors to warm is " + minExecutors);
// Spend at most HIVE_PREWARM_SPARK_TIMEOUT to wait for executors to come up.
int curExecutors = 0;
long maxPrewarmTime = HiveConf.getTimeVar(hiveConf, ConfVars.HIVE_PREWARM_SPARK_TIMEOUT,
TimeUnit.MILLISECONDS);
long ts = System.currentTimeMillis();
do {
try {
curExecutors = getExecutorCount(maxPrewarmTime, TimeUnit.MILLISECONDS);
} catch (TimeoutException e) {
// let's don't fail on future timeout since we have a timeout for pre-warm
LOG.warn("Timed out getting executor count.", e);
}
if (curExecutors >= minExecutors) {
LOG.info("Finished prewarming Spark executors. The current number of executors is " + curExecutors);
return;
}
Thread.sleep(500); // sleep half a second
} while (System.currentTimeMillis() - ts < maxPrewarmTime);
LOG.info("Timeout (" + maxPrewarmTime / 1000 + "s) occurred while prewarming executors. " +
"The current number of executors is " + curExecutors);
}
}1、通过SparkClientFactory.createClient创建了SparkClient
public static SparkClient createClient(Map sparkConf, HiveConf hiveConf)
throws IOException, SparkException {
Preconditions.checkState(server != null, "initialize() not called.");
return new SparkClientImpl(server, sparkConf, hiveConf);
} 1、实例化SparkClientImpl,在SparkClientImpl中启动了一个RemoteDriver进程
3.6 获取SparkWork
再回到SparkTask中,上面通过SparkUtilities创建SparkSession后,通过getWork获取SparkWork

3.7 提交SparkTask
1、通过SparkSession提交封装了SparkTask的SparkWork,并返回一个SparkJobRef对象,对象封装了Spark任务的引用。
SparkSessionImpl中submit任务:
public SparkJobRef submit(DriverContext driverContext, SparkWork sparkWork) throws Exception {
Preconditions.checkState(isOpen, "Session is not open. Can't submit jobs.");
return hiveSparkClient.execute(driverContext, sparkWork);
}RemoteHiveSparkClient.execute中submit
public SparkJobRef execute(final DriverContext driverContext, final SparkWork sparkWork)
throws Exception {
if (SparkClientUtilities.isYarnMaster(hiveConf.get("spark.master")) &&
!remoteClient.isActive()) {
// Re-create the remote client if not active any more
close();
createRemoteClient();
}
try {
return submit(driverContext, sparkWork);
} catch (Throwable cause) {
throw new Exception("Failed to submit Spark work, please retry later", cause);
}
}RemoteHiveSparkClient中submit:
private SparkJobRef submit(final DriverContext driverContext, final SparkWork sparkWork) throws Exception {
final Context ctx = driverContext.getCtx();
final HiveConf hiveConf = (HiveConf) ctx.getConf();
refreshLocalResources(sparkWork, hiveConf);
final JobConf jobConf = new JobConf(hiveConf);
//update the credential provider location in the jobConf
HiveConfUtil.updateJobCredentialProviders(jobConf);
// Create temporary scratch dir
final Path emptyScratchDir = ctx.getMRTmpPath();
FileSystem fs = emptyScratchDir.getFileSystem(jobConf);
fs.mkdirs(emptyScratchDir);
byte[] jobConfBytes = KryoSerializer.serializeJobConf(jobConf);
byte[] scratchDirBytes = KryoSerializer.serialize(emptyScratchDir);
byte[] sparkWorkBytes = KryoSerializer.serialize(sparkWork);
JobStatusJob job = new JobStatusJob(jobConfBytes, scratchDirBytes, sparkWorkBytes);
if (driverContext.isShutdown()) {
throw new HiveException("Operation is cancelled.");
}
JobHandle jobHandle = remoteClient.submit(job);
RemoteSparkJobStatus sparkJobStatus = new RemoteSparkJobStatus(remoteClient, jobHandle, sparkClientTimtout);
return new RemoteSparkJobRef(hiveConf, jobHandle, sparkJobStatus);
} (插入=====================================开始)
在SparkTask中:

调用SparkJobRef的monitorJob方法,循环获取Spark中Job的状态。
(插入=====================================结束)
接着RemoteHiveSparkClient中通过remoteClient的submit方法提交job。最终通过SparkClientImpl中的protocol提交任务
public <T extends Serializable> JobHandle<T> submit(Job<T> job) {
return protocol.submit(job, Collections.T>>emptyList());
} 3.8 启动RemoteDriver
接下来详细介绍一下SparkClientImpl,这个类是连接Spark的入口。也就是Spark的启动流程的实例类。
在上面我们已经提到,SparkClientImpl实例化的时候,通过startDriver方法启动了RemoteDriver:
SparkClientImpl(RpcServer rpcServer, Map<String, String> conf, HiveConf hiveConf) throws IOException, SparkException {
this.conf = conf;
this.hiveConf = hiveConf;
this.jobs = Maps.newConcurrentMap();
String clientId = UUID.randomUUID().toString();
String secret = rpcServer.createSecret();
this.driverThread = startDriver(rpcServer, clientId, secret);
this.protocol = new ClientProtocol();
try {
// The RPC server will take care of timeouts here.
this.driverRpc = rpcServer.registerClient(clientId, secret, protocol).get();
} catch (Throwable e) {
String errorMsg = null;
if (e.getCause() instanceof TimeoutException) {
errorMsg = "Timed out waiting for client to connect.\nPossible reasons include network " +
"issues, errors in remote driver or the cluster has no available resources, etc." +
"\nPlease check YARN or Spark driver's logs for further information.";
} else if (e.getCause() instanceof InterruptedException) {
errorMsg = "Interruption occurred while waiting for client to connect.\nPossibly the Spark session is closed " +
"such as in case of query cancellation." +
"\nPlease refer to HiveServer2 logs for further information.";
} else {
errorMsg = "Error while waiting for client to connect.";
}
LOG.error(errorMsg, e);
driverThread.interrupt();
try {
driverThread.join();
} catch (InterruptedException ie) {
// Give up.
LOG.warn("Interrupted before driver thread was finished.", ie);
}
throw Throwables.propagate(e);
}
driverRpc.addListener(new Rpc.Listener() {
@Override
public void rpcClosed(Rpc rpc) {
if (isAlive) {
LOG.warn("Client RPC channel closed unexpectedly.");
isAlive = false;
}
}
});
isAlive = true;
}并且注册了RpcServer,并启动了监听。
我们重点看一下startDriver,在startDriver中整合了所有需要跑Spark任务的参数,整合参数通过Spark中的SparkSubmit类去提交Spark任务。
3.8.1 SparkClient的参数
在之前的分析中,通过HiveSparkClientFactory的createHiveSparkClient方法创建SparkClient,在这个方法中,初始化了Spark的参数:
spark.master默认为yarn

任务提交模式:cluster
spark.app.name:Hive on Spark
序列化方式:kryo
3.8.2 运行参数
在SparkClientImpl中设置Spark运行内存参数:

扩展类,扩展包路径:

使用SparkSubmit方式提交Spark任务:
![]()
设置Spark executor运行core数量、内存、实例:

3.8.3 启动RemoteDriver

以上就是Hive on Spark中Spark的启动流程。
3.9 提交任务
接下来介绍一下提交任务的过程,让我们回到SparkTask中:

SparkSessionImpl
public SparkJobRef submit(DriverContext driverContext, SparkWork sparkWork) throws Exception {
Preconditions.checkState(isOpen, "Session is not open. Can't submit jobs.");
return hiveSparkClient.execute(driverContext, sparkWork);
}
RemoteHiveSparkClient
public SparkJobRef execute(final DriverContext driverContext, final SparkWork sparkWork)
throws Exception {
if (SparkClientUtilities.isYarnMaster(hiveConf.get("spark.master")) &&
!remoteClient.isActive()) {
// Re-create the remote client if not active any more
close();
createRemoteClient();
}
try {
return submit(driverContext, sparkWork);
} catch (Throwable cause) {
throw new Exception("Failed to submit Spark work, please retry later", cause);
}
}
private SparkJobRef submit(final DriverContext driverContext, final SparkWork sparkWork) throws Exception {
final Context ctx = driverContext.getCtx();
final HiveConf hiveConf = (HiveConf) ctx.getConf();
refreshLocalResources(sparkWork, hiveConf);
final JobConf jobConf = new JobConf(hiveConf);
//update the credential provider location in the jobConf
HiveConfUtil.updateJobCredentialProviders(jobConf);
// Create temporary scratch dir
final Path emptyScratchDir = ctx.getMRTmpPath();
FileSystem fs = emptyScratchDir.getFileSystem(jobConf);
fs.mkdirs(emptyScratchDir);
byte[] jobConfBytes = KryoSerializer.serializeJobConf(jobConf);
byte[] scratchDirBytes = KryoSerializer.serialize(emptyScratchDir);
byte[] sparkWorkBytes = KryoSerializer.serialize(sparkWork);
JobStatusJob job = new JobStatusJob(jobConfBytes, scratchDirBytes, sparkWorkBytes);
if (driverContext.isShutdown()) {
throw new HiveException("Operation is cancelled.");
}
JobHandle jobHandle = remoteClient.submit(job);
RemoteSparkJobStatus sparkJobStatus = new RemoteSparkJobStatus(remoteClient, jobHandle, sparkClientTimtout);
return new RemoteSparkJobRef(hiveConf, jobHandle, sparkJobStatus);
} 其中JobHandle就是任务的一个句柄。通过remoteClient.submit提交job:
public <T extends Serializable> JobHandle<T> submit(Job<T> job) {
return protocol.submit(job, Collections.T>>emptyList());
} 通过SparkClientImpl内部类ClientProtocol.submit方法,
1、通过Rpc线程池创建了Promise
2、实例化JobHandle
3、将jobId和job封装成JobRequest对象,并交给driverRpc来发送,然后返回一个promise对象来保存异步执行结果
4、保持监听
JobHandleImpl submit(Job job, List.Listener> listeners) {
final String jobId = UUID.randomUUID().toString();
final Promise promise = driverRpc.createPromise();
final JobHandleImpl handle =
new JobHandleImpl(SparkClientImpl.this, promise, jobId, listeners);
jobs.put(jobId, handle);
final io.netty.util.concurrent.Future rpc = driverRpc.call(new JobRequest(jobId, job));
LOG.debug("Send JobRequest[{}].", jobId);
// Link the RPC and the promise so that events from one are propagated to the other as
// needed.
rpc.addListener(new GenericFutureListener.netty.util.concurrent.Future>() {
@Override
public void operationComplete(io.netty.util.concurrent.Future f) {
if (f.isSuccess()) {
// If the spark job finishes before this listener is called, the QUEUED status will not be set
handle.changeState(JobHandle.State.QUEUED);
} else if (!promise.isDone()) {
promise.setFailure(f.cause());
}
}
});
promise.addListener(new GenericFutureListener>() {
@Override
public void operationComplete(Promise p) {
if (jobId != null) {
jobs.remove(jobId);
}
if (p.isCancelled() && !rpc.isDone()) {
rpc.cancel(true);
}
}
});
return handle;
} 3.10 RemoteDriver与SparkClient交互
RemoteDriver与SparkClient进行交互,并向Spark集群提交任务。
在RemoteDriver构造函数中,处理参数,初始化环境变量,并将这些参数赋给相应的SparkConf
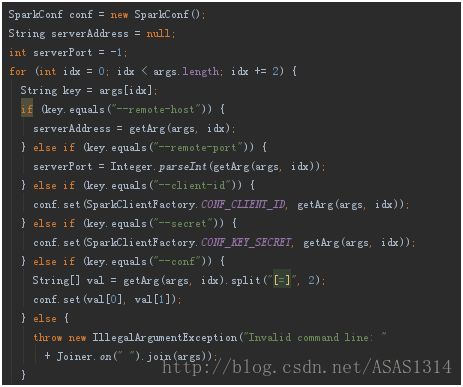
创建执行线程
executor = Executors.newCachedThreadPool();将RemoteDriver使用的参数保存到mapConf中
Map<String, String> mapConf = Maps.newHashMap();
for (Tuple2<String, String> e : conf.getAll()) {
mapConf.put(e._1(), e._2());
LOG.debug("Remote Driver configured with: " + e._1() + "=" + e._2());
}Rpc创建RemoteDriver端
this.clientRpc = Rpc.createClient(mapConf, egroup, serverAddress, serverPort,
clientId, secret, protocol).get();为clientRpc添加监听器
this.clientRpc.addListener(new Rpc.Listener() {
@Override
public void rpcClosed(Rpc rpc) {
LOG.warn("Shutting down driver because RPC channel was closed.");
shutdown(null);
}
});1、创建SparkContext
2、实例化JobContextImpl保存Job执行时的运行信息
try {
JavaSparkContext sc = new JavaSparkContext(conf);
sc.sc().addSparkListener(new ClientListener());
synchronized (jcLock) {
jc = new JobContextImpl(sc, localTmpDir);
jcLock.notifyAll();
}
} catch (Exception e) {
LOG.error("Failed to start SparkContext: " + e, e);
shutdown(e);
synchronized (jcLock) {
jcLock.notifyAll();
}
throw e;
}到此,RemoteDriver的构建完成。在构建RemoteDriver过程中,还有三个内部类,我们看一下其作用以及实现。
1、JobWrapper
JobWrapper实现了Callable接口,其核心实现call方法
第一步,调用protocol的jobStarted方法发送JobStarted消息。
第二步,调用封装的Job中的call方法,monitorJob中会发送任务提交消息
jc.setMonitorCb(new MonitorCallback() {
@Override
public void call(JavaFutureAction future,
SparkCounters sparkCounters, Set cachedRDDIds) {
monitorJob(future, sparkCounters, cachedRDDIds);
}
});
T result = req.job.call(jc); 第三步,通过jobEndReceived的值等待JobEnd
2、ClientListener
ClientListener继承自JavaSparkListener,用来监听来自Spark Scheduler的事件。
当job开始时,触发obJobStart方法,将Job的 stage id和jobId保存到stageId这个HashMap中。
当任务结束时,触发onJobEnd。
当一个task结束时,触发onTaskEnd
3、DriverProtocol
DriverProtocol中定义了消息类型处理,其中最受大家关注的应该是JobRequest了。
private void handle(ChannelHandlerContext ctx, JobRequest msg) {
LOG.info("Received job request {}", msg.id);
JobWrapper wrapper = new JobWrapper(msg);
activeJobs.put(msg.id, wrapper);
submit(wrapper);
} 当DriverProtocol收到JobRequest消息后,将消息封装到JobWrapper中,将JobWrapper提交到任务列表中。
什么时候收到JobRequest?
SparkTask执行通过SparkClient提交任务时。
我们看一下RemoteHiveSparkClient,在RemoteHiveSparkClient中实例化的JobStatusJob
JobStatusJob job = new JobStatusJob(jobConfBytes, scratchDirBytes, sparkWorkBytes);
if (driverContext.isShutdown()) {
throw new HiveException("Operation is cancelled.");
}通过remoteClient提交
JobHandle jobHandle = remoteClient.submit(job);在JobWrapper中调用Job的call方法:
public Serializable call(JobContext jc) throws Exception {
JobConf localJobConf = KryoSerializer.deserializeJobConf(jobConfBytes);
// Add jar to current thread class loader dynamically, and add jar paths to JobConf as Spark
// may need to load classes from this jar in other threads.
Map<String, Long> addedJars = jc.getAddedJars();
if (addedJars != null && !addedJars.isEmpty()) {
List<String> localAddedJars = SparkClientUtilities.addToClassPath(addedJars,
localJobConf, jc.getLocalTmpDir());
localJobConf.set(Utilities.HIVE_ADDED_JARS, StringUtils.join(localAddedJars, ";"));
}
Path localScratchDir = KryoSerializer.deserialize(scratchDirBytes, Path.class);
SparkWork localSparkWork = KryoSerializer.deserialize(sparkWorkBytes, SparkWork.class);
logConfigurations(localJobConf);
SparkCounters sparkCounters = new SparkCounters(jc.sc());
Map<String, List<String>> prefixes = localSparkWork.getRequiredCounterPrefix();
if (prefixes != null) {
for (String group : prefixes.keySet()) {
for (String counterName : prefixes.get(group)) {
sparkCounters.createCounter(group, counterName);
}
}
}
SparkReporter sparkReporter = new SparkReporter(sparkCounters);
// Generate Spark plan
SparkPlanGenerator gen =
new SparkPlanGenerator(jc.sc(), null, localJobConf, localScratchDir, sparkReporter);
SparkPlan plan = gen.generate(localSparkWork);
jc.sc().setJobGroup("queryId = " + localSparkWork.getQueryId(), DagUtils.getQueryName(localJobConf));
// Execute generated plan.
JavaPairRDD<HiveKey, BytesWritable> finalRDD = plan.generateGraph();
// We use Spark RDD async action to submit job as it's the only way to get jobId now.
JavaFutureAction<Void> future = finalRDD.foreachAsync(HiveVoidFunction.getInstance());
jc.monitor(future, sparkCounters, plan.getCachedRDDIds());
return null;
}1、反序列化得到Job的配置信息
2、设置Hive相关jar
3、反序列化本地临时路径
4、反序列化SparkWork
5、生成Spark执行计划
6、通过plan生成RDD
7、提交到Spark集群中
// Execute generated plan.
JavaPairRDD finalRDD = plan.generateGraph();
// We use Spark RDD async action to submit job as it's the only way to get jobId now.
JavaFutureAction future = finalRDD.foreachAsync(HiveVoidFunction.getInstance()); 有兴趣的同学,可以自行下载Hive源码进行分析。
Hive项目地址:https://github.com/apache/hive
git clone https://github.com/apache/hive.git