request请求参数校验(十二)
一、 数据的非空校验
在得到请求参数后,需要对数据进行校验,这是服务器端校验,通过java代码实现。在实际开发中,客户端校验(JavaScript实现),和服务器端校验都要有。
拿到的都是字符串,做非空校验:String.trim().length()>0,trim去除左右两边空格,一定要记住,实际开发中,得到数据一定要trim
规则校验:正则进行规则校验。
二、处理中文乱码
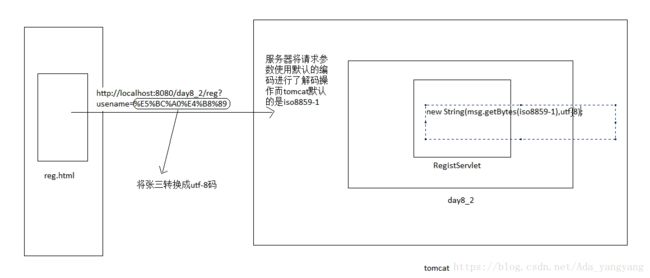
1. 乱码出现的原因:汉字在各个编码表中的码值不一样。
2. 程序出现乱码的原因。在Tomcat8以前,页面使用utf-8编码方式和Tomcat使用的ISO8859-1解码方式不一致,request获取的信息就是乱码。
编解码过程代码如下:
package com.it.test;
import java.io.UnsupportedEncodingException;
import java.net.URLDecoder;
import java.net.URLEncoder;
public class Demo {
public static void main(String[] args) throws UnsupportedEncodingException {
/*使用URL进行编解码*/
System.out.println("========URL实现编解码==========");
String s = "中国";
String code = URLEncoder.encode(s, "utf-8");
//tomcat进行了如下操作
String result = URLDecoder.decode(code, "iso8859-1");//解码
//得到正确信息
//1.使用iso8859-1进行编码
String code2 = URLEncoder.encode(result, "iso8859-1");
String right = URLDecoder.decode(code2, "utf-8");
System.out.println(right);
System.out.println("=========string类内中实现编解码============");
fun1();
}
//在string类中就可以直接进行编码解码
public static void fun1() throws UnsupportedEncodingException {
String origin = "北京";
byte[] code = origin.getBytes("utf-8");
String wrongMsg = new String(code, "iso8859-1");
String rightMsg = new String(wrongMsg.getBytes("iso8859-1"),"utf-8");
System.out.println(rightMsg);
}
}
3.解决方案:
post和get请求都可以的方式:
将得到的信息使用ISO8859-1进行编码 msg.getBytes("iso8859-1");
在使用utf-8进行解码 new String(msg.getBytes("iso8859-1"),"utf-8");
//获得用户名:
String username = request.getParameter("username");//参数要与JSP中的name值对应。
//在Tomcat7及其以下的版本,中文会出现乱码,解决方案如下:
//String right = new String(username.getBytes("iso8859-1"),"utf-8");只有post请求可以使用的方式如下:
如果请求方式是post,我们可以通过request.setCharacterEncoding(String charsetname);
//post请求
request.setCharacterEncoding("utf-8");
//获得用户名:
String username = request.getParameter("username");//参数要与JSP中的name值对应。
//在Tomcat7及其以下的版本,中文会出现乱码,解决方案如下:
//String right = new String(username.getBytes("iso8859-1"),"utf-8");
System.out.println(username);三、处理中文乱码所有方案总结
1、对Tomcat和eclipse配置文件进行配置
第一步:对Tomcat_HOME/conf/server.xml文件进行配置
核心代码如下(其中最后一句是自己加的):
第二步:
将
修改为:
或
加上 URIEncoding="UTF-8"
这种方式一般不建议使用,因为它修改的是Tomcat平台的编码,如果人为修改会影响其他项目的运行。
2、逆向编码解码还原法
之所以会出现乱码,是因为浏览器将中文以utf-8的编码格式传给tomcat时,tomcat以默认的iso8859-1方式对其解码,而编解码格式不一致,故而出现乱码。根据这个原理可逆向还原。
如:
byte buf[] = request.getParameter("name").getBytes("iso8859-1");
String name = new String(buf,"GBK");这样得到的name便是前台传来的正确的中文参数了
这种方式比较偏向底层,而且有一个弊端,就是当浏览器传送的中文参数很多时,需要一个个设置,比较罗嗦,不利于节省时间。
3、将浏览器的表单的提交方式设为post方式,同时在servlet里在接受参数前将request的编码设置为GBK或者UTF-8。
前台形如:
后台形如:
request.setCharacterEncoding("utf-8");
String name = request.getParameter("name");这样也能正确地接受中文参数了。当然,这种方式也存在弊端,试想下当项目发布后,如果需要修改编码为GBK,则要修改源代码,而对客户而言,这需要反编译等步骤直接修改代码,有点困难。
4、通过web项目的WebRoot/WEB-INF/web.xml文件进行配置参数,同时可在servlet中进行读取。
web.xml的示例核心代码如下:
login
cn.hncu.servlets.LoginServlet
character
utf-8
servlet示例核心代码如下:
public void init(ServletConfig config) throws ServletException {
String charset = config.getInitParameter("character");
System.out.println(charset);
}这种方法弥补了方法3的缺陷,方便后期维护和修改,用户修改时不需要改源代码,只需修改web.xml即可。
参考资料:
https://blog.csdn.net/lengjinghk/article/details/51938644
https://blog.csdn.net/Night_alone/article/details/76644023