Linux下的性能调优工具Oprofile VS perf,从Oprofile转向使用perf
好文,学习一下。
原文链接:
https://developer.ibm.com/tutorials/migrate-from-oprofile-to-perf/
原标题:
Migrating from OProfile to perf, and beyond
Map your favorite OProfile commands to their equivalent perf commands, then learn about perf's superpowers!
Paul Clarke | Published February 21, 2019
LinuxSystems
Overview
OProfile has been around for decades, and for some time was the workhorse of performance profiling on Linux®-based systems, and can serve the same role today. However, OProfile is not included in Red Hat Enterprise Linux (RHEL) 8 beta, and so it may be prudent for OProfile users to start considering alternative tools. Analogous projects which compare very favorably to OProfile in features, ease-of-use, and vitality of the community do exist. One such project is the Linux perf command. Until recently, when compared to OProfile, perf had some drawbacks such as lack of support for Java™ just-in-time (JIT) compiled programs and hardware event mnemonics, but these have been addressed in recent releases. This tutorial offers current OProfile users a roadmap for transitioning from OProfile to perf.
Both OProfile and perf currently use the same basic mechanism in the Linux kernel for enabling the event tracing: the perf_events infrastructure. Although it is primarily a user-space tool, the perfcommand is part of the Linux kernel from a development perspective, and being part of the Linux kernel has advantages and disadvantages. One possible advantage is that the code is more easily maintained because the code bases won’t drift apart over time. A disadvantage is that the version of perf is inherently tied to the version of the Linux kernel to a significant degree: getting access to new features in perf generally means getting a new kernel. Arguably, the community around the Linux perfcommand is more active and vibrant, and many new features are appearing in perf without analogs in OProfile.
Features supported by OProfile and perf
The following table shows the features supported by OProfile and perf.
| OProfile | perf | |
|---|---|---|
| From http://oprofile.sourceforge.net/about | ||
| Unobtrusive | ✓ | ✓ |
| System-wide profiling | ✓ | ✓ |
| Single process profiling | ✓ | ✓ |
| Event counting | ✓ | ✓ |
| Performance counter support | ✓ | ✓ |
| Call-graph support | ✓ | ✓ |
| Low overhead | ✓ | ✓ |
| Post-profile analysis | ✓ | ✓ |
| System support | ✓ | ✓ |
| More generally… | ||
| Hardware events | ✓ | ✓ |
| Hardware event mnemonics | ✓ | ✓ Ubuntu 18+ ✓ RHEL 7.4+ ✓ SUSE 12 SP3+ |
| Raw hardware events | ✓ | |
| Software events | ✓ | |
| Java profiling | ✓ | ✓ RHEL 7.4+ |
| Kernel tracepoint event support | ✓ | |
| Software-defined tracepoints | ✓ | |
| In-kernel-user probe tracepoints | ✓ | |
| In-kernel user retprobe tracepoints | ✓ | |
| Userspace probe tracepoints | ✓ | |
| Metrics | ✓ | |
| eBPF scripting | ✓ | |
| Python scripting | ✓ | |
| Perl scripting | ✓ | |
| Interactive performance analysis | ✓ | |
| Differential reports | ✓ | |
| KVM awareness | ✓ | |
perf trace |
✓ |
OProfile examples and their perf analogs
Consider the following examples from http://oprofile.sourceforge.net/examples. In the following tables, for a given OProfile command (on the left), the equivalent perf command is provided (on the right).
System-wide binary image summary
| OProfile command | perf command |
|---|---|
opreport --exclude-dependent |
perf report --stdio --sort=comm…includes kernel |
System-wide binary image summary including per-application libraries
| OProfile command | perf command |
|---|---|
opreport |
perf report --stdio --sort=pidThen, for each interesting task (pid) in the report, run the following command: perf report --stdio --pid=pid |
System-wide symbol summary including per-application libraries
| OProfile command | perf command |
|---|---|
opreport --symbols --image-path=path(Apparently needs a vmlinux from a kernel-debuginfopackage) |
perf report --stdio –n(Apparently does not need debuginfo) |
Symbol summary for a single application
| OProfile command | perf command |
|---|---|
opreport --exclude-dependent --symbols command(percentage relative to command) |
perf report --stdio -n --comm command(Similar, but includes libraries and kernel, percentage relative to system) |
Symbol summary for a single application including libraries
| OProfile command | perf command |
|---|---|
opreport --symbols command(relative percentage) |
perf report --stdio -n --comm command(global percentage) |
Image summary for a single application
| OProfile command | perf command |
|---|---|
opreport command |
perf report --stdio –n –F sample,overhead,dso --comm command |
Call-graph output for a single application
| OProfile command | perf command |
|---|---|
opreport –cl command |
perf report --stdio –g –n –comm=command(Must record with –g.) |
Annotate mixed source/assembly
| OProfile command | perf command |
|---|---|
opannotate --source --assembly command |
perf annotate --stdio [-n](Can display samples or percentage, but not both.) |
Annotated source
| OProfile command | perf command |
|---|---|
opannotate --source [--output-dir dir] |
perf annotate --stdio [-n]( perf always includes assembly.) |
Event mnemonics
Human-parsable event names are quite helpful for usability. It is arguably easier to profile for PM_DATA_FROM_L2MISS than 131326 or 0x200FE. The latter two (equivalent) numbers are the raw event code for PM_DATA_FROM_L2MISS (an IBM® POWER8® hardware event). All events are generally architecture-dependent and likely processor-generation-dependent. New processor generations often become available before the event mnemonics are incorporated into the supporting tools. Thus, it is useful to have the ability to use raw codes with the tools at hand. The perf command supports the use of raw event codes, making it potentially useful for profiling hardware events on newer processors or Linux distributions that do not have the required support yet. Support for IBM POWER® hardware event mnemonics was added to Linux 4.14 and has been backported to current enterprise Linux distributions (RHEL 7, SUSE 12, Ubuntu 18).
For POWER architecture, refer to the following raw event codes at:
-
POWER8 User’s Manual on IBM Portal for OpenPOWER (Appendix D)
-
POWER9 Performance Monitor Unit User’s Guide on IBM Portal for OpenPOWER (Chapter 5)
Profiling Java (JITed)
For profiling Java (JITed) code using OProfile:
operf java –agentpath:/usr/lib64/oprofile/libjvmti_oprofile.so commandopreport […]
With perf:
perf record –k 1 java –agentpath:/usr/lib64/libperf-jvmti.so commandperf inject --jit -i perf.data -o perf-jitted.data
OProfile features
The following tables provide mappings for OProfile commands and command parameters to their roughly equivalent perf command parameters.
operf
| Task | operf Syntax | perf Syntax |
|---|---|---|
| Recording, system-wide | operf --system-wide (ctrl-C to stop) |
perf record --all-cpus read (enter or ctrl-C to stop) |
| Recording, process | operfcommand |
perf recordcommand |
| Recording, specific event (Note that events are architecture-specific. Event mnemonics are tools-specific.) |
operf –eevent |
perf record –eevent |
| Single process profiling | operfcommand opreport [--symbols] |
perf record [-g]command perf report --stdio |
ocount
| Task | ocount Syntax | perf Syntax |
|---|---|---|
| Event counting (Note that events are architecture-specific. Event mnemonics are tools-specific.) |
ocount [--events events]command |
perf stat [--event=events]command |
operf parameters
| operf Syntax | perf record Syntax |
|---|---|
operf command |
perf record command |
--pid pid |
--pid pid |
--vmlinux vmlinux |
--vmlinux=vmlinux…but this option is generally not needed |
--events events |
--event events |
--callgraph |
-g or --call-graph(See the perf record man page for some caveats when binaries are built with --fomit-frame-pointer.) |
--separate-thread |
--per-thread |
--separate-cpu |
(per-cpu buffers are default) |
--session-dir dirStores session data in directory dir (default: oprofile_data) |
-o fileStores session data in a file (default: perf.data) |
--lazy-conversion |
Not needed |
--append |
Not supported |
opreport
| opreport Syntax | perf report Syntax |
|---|---|
opreport |
perf report –stdio |
--accumulated |
Not supported |
--debug-info |
--fields=srcfile,srcline |
--demangle[none,smart,normal](not sure what smart does) |
--demangle |
--callgraph |
--call-graphNote that if the perf data contains call-graphinformation, then perf will display call-graphoutput by default. Disable call-graph display with --call-graph=none |
--details |
No analog, but this is somewhat similar to perf annotate, without the sorting. |
--exclude-dependent |
--sort=commIncludes kernel |
--exclude-symbols |
--sort=commIncludes kernel |
--global-percent |
perf reports global percentages by default.To get relative percentages, use --call-graph=fractal |
--image-path paths |
--modulesUse with --vmlinux=vmlinux and must becurrently running kernel |
--root path |
--symfs=dir |
--include-symbols symbols |
--symbols=symbols |
--long-filenames |
--full-source-pathFor source files only. Not supported for dynamic shared objects (DSOs) |
--merge[lib,cpu,tid,tgid,unitmask,all] |
perf data is always merged |
--reverse-sort |
Not supported |
--session-dir dir Stores session data in directory dir (default: oprofile_data) |
-o file Stores session data in a file (default: perf.data) |
--show-address |
--verbose |
--sort[vma,sample,symbol,debug,image] |
--sort=[sym,sample,srcfile,srcline,dso]Sort by address is not supported Output is different. Sort keys do not seem to be absolute |
--symbols |
Not supported |
--threshold percentage |
--percent-limit percentage |
--xml |
Not supported |
opannotate
| opannotate Syntax | perf annotate Syntax |
|---|---|
opannotate |
perf annotate |
--assembly |
perf always displays assembly |
--demangle[none,smart,normal] |
Not supported |
--exclude-dependent |
Not supported |
--exclude-file files |
Not supported |
--exclude-symbols symbols |
Not supported |
--image-path paths |
--modulesUse with --vmlinux=vmlinux and must be currently running kernel |
--root path |
--symfs=dir |
--include-file files |
Not supported |
--merge [lib,cpu,tid,tgid,unitmask,all] |
perf data is always merged |
--include-symbols symbols |
Not supported |
--objdump-params params |
Not supported |
--output-dir dir |
Not supported |
--search-dirs paths |
Not supported |
--base-dirs paths |
Not supported |
--session-dir=dir |
--input=file |
--source |
--sourceEnabled by default |
--threshold percentage |
Not supported |
ophelp
| Task | ophelp Syntax | perf list Syntax |
|---|---|---|
| List events | ophelp |
perf list [--details] |
| Show the events for the given numerical CPU type | --cpu-type cpu-type |
Not supported |
| Show the symbolic CPU name | --get-cpu-type |
Not supported |
| Show the default event | --get-default-eventPOWER8: CYCLES:100000:0:1:1Skylake: cpu_clk_halted:100000:0:1:1 |
Not supported |
| Check events for validity | --check-events |
Not supported |
| Use the callgraph depth to compute the higher minimum sampling intervals | --callgraph depth |
Not supported |
| Show the default unit mask | --unit-mask event |
Not supported |
| Show the numerical unit and extra mask | --symbolic-unit-mask event |
Not supported |
| Show the extra unit mask | --extra-mask |
Not supported |
| List events in XML format | --xml |
Not supported |
opgprof
The output of opgprof is gprof-formatted profiling data. perf has no analog.
oparchive and opimport
oparchive and opimport are used to allow performance analysis to be completed on a different system than the one being measured, with no further need to access the measured system.
To analyze the data collected by perf on a different system (where the application is not installed, the operating system has different versions of libraries or a completely different processor architecture):
On the system under test:
perf record …
perf archive
Copy perf.data and perf.data.tar.bz2 to a different system.
Then, on the analysis system:
mkdir ~/.debug
tar xvf perf.data.tar.bz2 -C ~/.debug
perf report
If instruction-level analysis is required, an objdump command from the system under test is required. Providing such a program is not trival, but certainly possible. One approach is to build a version of objdump that interprets the architecture and instructions of the system under test, but which runs natively on the analysis system. objdump is part of the GNU Binutils project at https://www.gnu.org/software/binutils/.
Another approach is to copy the objdump binary file and all of its dependencies to the analysis system, and run those in an emulated environment. Using the QEMU project‘s user-mode emulation is a way to perform the emulation. For example, on an IBM POWER processor-based system:
-
Find the
objdumpbinary file.which objdump /usr/bin/objdump -
Then find the dependencies.
ldd /usr/bin/objdump linux-vdso64.so.1 => (0x00003fff868c0000) libopcodes-2.27-34.base.el7.so => /lib64/libopcodes-2.27-34.base.el7.so (0x00003fff86820000 libbfd-2.27-34.base.el7.so => /lib64/libbfd-2.27-34.base.el7.so (0x00003fff86660000) libdl.so.2 => /lib64/libdl.so.2 (0x00003fff86630000) libc.so.6 => /lib64/libc.so.6 (0x00003fff86440000) libz.so.1 => /lib64/libz.so.1 (0x00003fff86400000) /lib64/ld64.so.2 (0x00003fff868e0000) -
Copy all of these files to the analysis system, to a new directory, which would then look like this:
find objdump-ppc64le/ -type f objdump-ppc64le/lib64/libopcodes-2.27-34.base.el7.so objdump-ppc64le/lib64/ld64.so.2 objdump-ppc64le/lib64/libdl.so.2 objdump-ppc64le/lib64/libbfd-2.27-34.base.el7.so objdump-ppc64le/lib64/libz.so.1 objdump-ppc64le/lib64/libc.so.6 objdump-ppc64le/objdump -
Then create a simple script to run the
objdumpbinary under emulation.cat ~/bin/objdump-ppc64le #!/bin/sh qemu-ppc64le -L /home/pc/projects/objdump-ppc64le /home/pc/projects/objdump-ppc64le/objdump "$@" -
Make the script executable.
chmod a+x ~/bin/objdump-ppc64le -
Finally, pass the
objdumpcommand toperf.perf annotate --objdump=~/bin/objdump-ppc64le
perf
This section provides some of the additional features that are available with perf and not available with OProfile. It is not intended to be exhaustive, and perf is continually being enhanced. Some recent features (for example, eBPF) are not included here.
Software events
At certain key points in kernel code, events are raised by the software by way of explicit function calls such as:
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS, 1, regs, address);
You can record these events using the perf command.
To list software events:
perf list sw
To count software events:
perf stat -e software-event command
Example:
$ perf stat -e faults sleep 20
Performance counter stats for 'sleep 20':
61 faults
20.001082886 seconds time elapsed
Run the following command to record software events:
perf record -e event command
Tracepoints
Similar to software events, tracepoint events are embedded explicitly in kernel code. These events are exposed in the debugfs file system, which is commonly mounted at /sys/kernel/debug, and usually readable and thus usable only by the superuser. This directory hierarchy can be made world readable using the following command:
/usr/bin/sudo mount -o remount,mode=755 /sys/kernel/debug
To list tracepoints:
perf list tracepoint
To count tracepoint events:
perf stat -e tracepoint command
Example:
$ perf stat -e syscalls:sys_enter_nanosleep sleep 4
Performance counter stats for 'sleep 4':
1 syscalls:sys_enter_nanosleep
4.001018613 seconds time elapsed
To record tracepoints:
perf record -e tracepoint
Software-defined tracepoints (SDTs)
Software-defined tracepoints (SDTs) are predefined traceable points in user-mode code (applications and libraries) which can be enabled for tracing with the perf command.
To Enable software-defined tracepoints (SDTs) for a given DSO:
/usr/bin/sudo perf buildid-cache --add=dso
Example:
/usr/bin/sudo perf buildid-cache --add=/lib64/libpthread.so.0
To list SDTs:
perf list sdt
Example:
perf list sdt
List of pre-defined events (to be used in -e):
sdt_libpthread:cond_broadcast [SDT event]
sdt_libpthread:cond_destroy [SDT event]
sdt_libpthread:cond_init [SDT event]
sdt_libpthread:cond_signal [SDT event]
sdt_libpthread:cond_wait [SDT event]
sdt_libpthread:lll_futex_wake [SDT event]
sdt_libpthread:lll_lock_wait [SDT event]
sdt_libpthread:lll_lock_wait_private [SDT event]
sdt_libpthread:mutex_acquired [SDT event]
sdt_libpthread:mutex_destroy [SDT event]
sdt_libpthread:mutex_entry [SDT event]
sdt_libpthread:mutex_init [SDT event]
sdt_libpthread:mutex_release [SDT event]
sdt_libpthread:mutex_timedlock_acquired [SDT event]
sdt_libpthread:mutex_timedlock_entry [SDT event]
sdt_libpthread:pthread_create [SDT event]
sdt_libpthread:pthread_join [SDT event]
sdt_libpthread:pthread_join_ret [SDT event]
sdt_libpthread:pthread_start [SDT event]
sdt_libpthread:rdlock_acquire_read [SDT event]
sdt_libpthread:rdlock_entry [SDT event]
sdt_libpthread:rwlock_destroy [SDT event]
sdt_libpthread:rwlock_unlock [SDT event]
sdt_libpthread:wrlock_acquire_write [SDT event]
sdt_libpthread:wrlock_entry [SDT event]
Show more
To enable SDT as a true tracepoint:
/usr/bin/sudo perf probe sdt
Example:
/usr/bin/sudo perf probe sdt_libpthread:pthread_create
To count SDT events:
perf stat -e sdt command
Example:
perf stat -e sdt_libpthread:pthread_create sleep 8
To record SDT events:
perf record -e sdt command
User probes (uprobes)
Linux offers the capability to dynamically create tracepoints in user-space code (applications and libraries). These are called user probes or uprobes. User probes can be created anywhere in executable code, and are usually created at function entry points. Return points of functions are also commonly traced, and these are known as uretprobes.
To list probable functions for a user-mode DSO like an application or shared library:
perf probe -x dso --funcs
To enable dynamic tracepoint for a DSO function [return from function][including a variable value]:
perf probe -x dso --add=’func[%return][$vars]’
When creating user probes which include any variables (“$vars”), debugging information must be available. Many packages have corresponding debuginfo packages.
To record using a new dynamic tracepoint event:
perf record --event func_event …
Metrics
Metrics are arithmetic combinations of events. Given a metric, the perf command can automatically record the events required, compute, and display the metric.
To list metrics:
perf list metrics
To record and display metrics:
perf stat record --metrics metric-or-group command
Example:
$ perf stat record --metrics Pipeline -a sleep 8
Performance counter stats for 'system wide':
297,071,773 uops_retired.retire_slots # 1.2 UPI (66.65%)
486,187,770 inst_retired.any (66.67%)
461,622,915 cycles (66.69%)
374,380,257 uops_executed.thread # 2.5 ILP (66.66%)
303,701,770 uops_executed.core_cycles_ge_1 (66.66%)
8.000978188 seconds time elapsed
Python/Perl scripting
perf provides the capability to write scripts to process a recorded event stream.
To generate a sample script based on the given perf data, with template functions for each of the recorded events:
perf script --gen-script [perl|python]
Example:
perf record -e syscalls:sys_enter_nanosleep sleep 1
perf script --gen-script python
perf script --gen-script python produces a perf-script.py file containing template functions for each event in the perf.data file as shown in the following example:
[…]
def trace_begin():
print "in trace_begin"
def trace_end():
print "in trace_end"
def syscalls__sys_enter_nanosleep(event_name, context, common_cpu,
common_secs, common_nsecs, common_pid, common_comm,
common_callchain, nr, rqtp, rmtp, perf_sample_dict):
print_header(event_name, common_cpu, common_secs, common_nsecs,
common_pid, common_comm)
[…]
def print_header(event_name, cpu, secs, nsecs, pid, comm):
print "%-20s %5u %05u.%09u %8u %-20s " % \
(event_name, cpu, secs, nsecs, pid, comm),
Show more
Interactive analysis
perf report, without --stdio, will launch an interactive analysis tool.
Initially, the basic results are displayed:
Samples: 7 of event 'cycles:ppp', Event count (approx.): 12785190
Overhead Command Shared Object Symbol
82.48% ls [kernel.kallsyms] [k] copypage_power7
17.26% ls [kernel.kallsyms] [k] move_page_tables
0.26% perf [kernel.kallsyms] [k] perf_event_exec
0.00% perf [unknown] [H] 0xc00000000020a4f4
0.00% perf [unknown] [H] 0xc00000000020a4d8
0.00% perf [unknown] [H] 0xc0000000000d24dc
Then, if a line is highlighted by moving the cursor with the arrow keys, and selected by pressing Enter, a menu (as shown below) is displayed.
Annotate copypage_power7
Zoom into ls thread
Zoom into the Kernel DSO
Browse map details
Run scripts for samples of symbol [copypage_power7]
Run scripts for all samples
Switch to another data file in PWD
Exit
This allows more selective and detailed analysis of the data.
Differential reports
perf can show the differences between two similar recordings, which can help to show the effect that code changes have.
Example:
$ perf record -o perf-before.data command-before
$ perf record -o perf-after.data command-after
$ perf diff perf-before.data perf-after.data
# Event 'cycles:ppp'
#
# Baseline Delta Abs Shared Object Symbol
# ........ ......... ................. ................................
#
62.28% +0.12% load [.] main
19.11% -0.08% load [.] sum_add
18.42% -0.05% load [.] sum_sub
[…]
KVM awareness
perf kvm, when run on a KVM host, can record events for a specified guest, just for the host itself, or both. There are modes for record-and-report and live display (perf kvm top and perf kvm stat live).
perf sched
perf sched traces kernel scheduling events, and can report in different ways.
For scheduling latencies and other properties:
perf sched latency
Example output (edited to fit):
----------------------------------------------------------------------
Task | Run |Switches| Avg | Max | Max delay at |
| time | | delay | delay | Max delay at |
| (ms) | | (ms) | (ms) | Max delay at |
----------------------------------------------------------------------
kworker/6:1:29418 | 0.018 | 1 | 0.228 | 0.228 | 12605.527065 s
ls:496 | 1.969 | 2 | 0.007 | 0.008 | 12605.525392 s
perf:495 | 4.283 | 1 | 0.003 | 0.003 | 12605.527066 s
sshd:32452 | 0.000 | 1 | 0.003 | 0.003 | 12605.527078 s
migration/5:33 | 0.000 | 1 | 0.002 | 0.002 | 12605.525384 s
----------------------------------------------------------------------
TOTAL: | 6.270 | 6 |
--------------------------------------
To display a detailed scheduling trace:
perf sched script
Example output (edited for clarity):
script
perf 495 [004] 12605.525094: sched:sched_wakeup: perf:496 [120] success=1
CPU:005
swapper 0 [005] 12605.525100: sched:sched_switch: swapper/5:0 [120] R ==>
perf:496 [120]
perf 495 [004] 12605.525346: sched:sched_stat_runtime: comm=perf pid=495
runtime=4283140 [ns] vruntime=16981556937 [ns]
perf 495 [004] 12605.525348: sched:sched_switch: perf:495 [120] S ==>
swapper/4:0 [120]
perf 496 [005] 12605.525382: sched:sched_wakeup: migration/5:33 [0]
success=1 CPU:005
perf 496 [005] 12605.525382: sched:sched_stat_runtime: comm=perf pid=496
runtime=291800 [ns] vruntime=16541714462 [ns]
Show more
To run a workload timing simulation:
perf sched replay
Example output:
run measurement overhead: 157 nsecs
sleep measurement overhead: 62650 nsecs
the run test took 1000029 nsecs
the sleep test took 1079223 nsecs
nr_run_events: 9
nr_sleep_events: 175
nr_wakeup_events: 5
target-less wakeups: 19
task 0 ( swapper: 0), nr_events: 9
task 1 ( swapper: 1), nr_events: 1
[…]
task 80 ( bash: 28955), nr_events: 1
task 81 ( man: 28966), nr_events: 1
[…]
task 115 ( bash: 495), nr_events: 4
task 116 ( perf: 496), nr_events: 27
------------------------------------------------------------
#1 : 3.596, ravg: 3.60, cpu: 74.00 / 74.00
#2 : 4.448, ravg: 3.68, cpu: 68.37 / 73.44
#3 : 4.166, ravg: 3.73, cpu: 61.90 / 72.29
#4 : 4.117, ravg: 3.77, cpu: 71.88 / 72.25
#5 : 4.019, ravg: 3.79, cpu: 69.11 / 71.93
#6 : 4.169, ravg: 3.83, cpu: 78.12 / 72.55
#7 : 4.366, ravg: 3.88, cpu: 68.03 / 72.10
#8 : 4.149, ravg: 3.91, cpu: 72.15 / 72.10
#9 : 3.941, ravg: 3.91, cpu: 63.79 / 71.27
#10 : 3.877, ravg: 3.91, cpu: 62.39 / 70.38
Show more
To display a context switching outline, including the timing by when tasks begin to run, are paused, and are migrated from one CPU to another:
perf sched map
Example output:
*A0 12605.525100 secs A0 => perf:496
*. A0 12605.525348 secs . => swapper:0
. *B0 12605.525384 secs B0 => migration/5:33
. B0 *A0 12605.525392 secs
. *. A0 12605.525392 secs
. . *C0 12605.527065 secs C0 => kworker/6:1:29418
*D0 . C0 12605.527066 secs D0 => perf:495
*E0 D0 . C0 12605.527078 secs E0 => sshd:32452
E0 D0 . *. 12605.527086 secs
To display an analysis of individual scheduling events:
perf sched timehist
Example output:
time cpu task name wait time sch delay run time
[tid/pid] (msec) (msec) (msec)
------------ ------ -------------- --------- --------- ---------
12605.525100 [0005] 0.000 0.000 0.000
12605.525348 [0004] perf[495] 0.000 0.000 0.000
12605.525384 [0005] perf[496] 0.000 0.006 0.283
12605.525392 [0006] 0.000 0.000 0.000
12605.525392 [0005] migration/5[33] 0.000 0.002 0.008
12605.527065 [0006] ls[496] 0.007 0.000 1.673
12605.527066 [0004] 0.000 0.000 1.718
12605.527078 [0000] 0.000 0.000 0.000
12605.527086 [0006] kworker/6:1[29418] 0.000 0.228 0.021
perf timechart
The perf timechart command records and graphically displays scheduling information.
To record timechart data:
perf timechart record command
To generate the scheduling information graphic in SVG format (as output.svg by default):
perf timechart
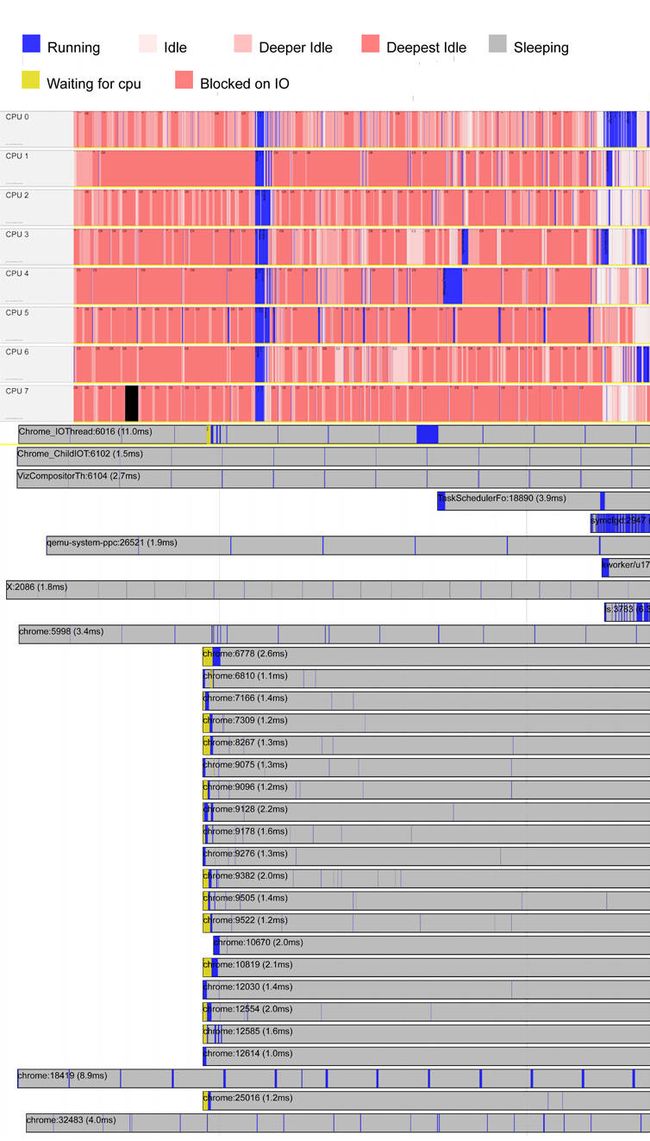
Observe when tasks are running, and on what CPU, as well as other scheduling-related events.
perf top
perf top, like the well-known top command that displays utilization information for tasks, will display live updates of the most active functions across a system. Closer analysis capabilities, as in perf reportand perf annotate are available.
perf trace
Similar to strace, the well-known command which records system calls, perf trace records and displays statistics related to system calls, page faults, and scheduling.
perf trace [-F all] [--sched] record command
Example:
perf trace –F all –sched record /bin/ls
perf trace -I perf.data --with-summary
0.000 ( 0.000 ms): ls/8918 minfault [__clear_user+0x25] => 0x0 (?k)
0.018 ( 0.000 ms): ls/8918 minfault [__clear_user+0x25] => 0x0 (?k)
[…]
0.089 ( 0.001 ms): ls/8918 brk() = 0x21f7000
0.094 ( 0.000 ms): ls/8918 minfault [strlen+0x0] => 0x0 (?.)
0.096 ( 0.000 ms): ls/8918 minfault [strlen+0xe5] => 0x0 (?.)
0.099 ( 0.000 ms): ls/8918 minfault [dl_main+0x14] => 0x0 (?.)
[…]
0.132 ( 0.004 ms): ls/8918 mmap(len: 4096, prot: READ|WRITE, flags: PRIVATE|ANONYMOUS) = 0x7f246d5e8000[…]
0.154 ( 0.007 ms): ls/8918 access(filename: 0x6d3e6cd0, mode: R) = -1 ENOENT No such file or directory
[…]
0.174 ( 0.326 ms): ls/8918 open(filename: 0x6d3e55c7, flags:CLOEXEC) = 3
0.502 ( 0.001 ms): ls/8918 fstat(fd: 3, statbuf: 0x7ffdcefb4a50) = 0
0.504 ( 0.004 ms): ls/8918 mmap(len: 130997, prot: READ, flags: PRIVATE, fd: 3) = 0x7f246d5c8000
0.509 ( 0.002 ms): ls/8918 close(fd: 3) = 0
Show more
Conclusion
The Linux perf command is a powerful tool, being continually advanced by a vibrant community. It can readily serve as a replacement for the OProfile suite of tools.
Appendix
opcontrol
opcontrol is one of the interfaces used by OProfile to collect profiling data, and was deprecated before release 1.0.0 of OProfile, in favor of the Linux kernel’s perf_events interface. The opcontrol interface is still available with Red Hat Enterprise Linux 7 (OProfile 0.9.9), SUSE Linux Enterprise 12 (OProfile 0.9.9), and Ubuntu 14.04 (OProfile 0.9.9), but not with Red Hat Enterprise Linux 8 beta, SUSE Linux Enterprise 15, or Ubuntu 16 and later.
| opcontrol parameter | OProfile (>=0.99) syntax | perf syntax |
|---|---|---|
--init |
No longer needed. | No longer needed. |
--status |
No longer needed. | No longer needed. |
--start-daemon |
No longer needed. | No longer needed. |
--start |
No longer needed. | No longer needed. |
--dump |
No longer needed. | No longer needed. |
--stop |
No longer needed. | No longer needed. |
--shutdown |
No longer needed. | No longer needed. |
--reset |
No longer needed. | No longer needed. |
--deinit |
No longer needed. | No longer needed. |
--list-events |
ophelp |
perf list |
--setup options |
Pass options to respective command |
|
--save=session |
--session-dir=dir |
-o file |
--session-dir=dir |
--session-dir=dir |
-i file |
--buffer-size=size |
/sys/kernel/debug/btracing/uffer_total_size_kb |
|
--buffer-watershed=num |
Not supported | |
--cpu-buffer-size=size |
/sys/kernel/debug/btracing/buffer_size_kb |
|
--event=event |
--events=event |
--event=event |
--separate[none,lib,kernel,thread,cpu,all] |
--separate-thread--separate-cpu |
Not supported |
--callgraph depth |
Not supported. Full callchain is recorded | |
--image image |
Not supported | |
--vmlinux=vmlinux |
--vmlinux=vmlinux |
|
--kernel-range |
Not supported |
SOCIAL
- Linked In
- Google+
CONTENTS
- Overview
- Features supported by OProfile and perf
- OProfile examples and their perf analogs
- System-wide binary image summary
- System-wide binary image summary including per-application libraries
- System-wide symbol summary including per-application libraries
- Symbol summary for a single application
- Symbol summary for a single application including libraries
- Image summary for a single application
- Call-graph output for a single application
- Annotate mixed source/assembly
- Annotated source
- Event mnemonics
- Profiling Java (JITed)
- OProfile features
- operf
- ocount
- operf parameters
- opreport
- opannotate
- ophelp
- opgprof
- oparchive and opimport
- perf
- Software events
- Tracepoints
- Software-defined tracepoints (SDTs)
- User probes (uprobes)
- Metrics
- Python/Perl scripting
- Interactive analysis
- Differential reports
- KVM awareness
- perf sched
- perf timechart
- perf top
- perf trace
- Conclusion
- Appendix
- opcontrol
RESOURCES
- OProfile project
- Perf wiki
- Brendan Gregg’s perf examples
Related content