《高性能MySQL》读书笔记-第5章 创建高性能索引
5.1 索引基础
MySQL会先在索引上按值进行查找,然后返回所有包含该值的数据行。如果索引包含多个列,MySQL只能高效地使用索引的最左前缀列。
B-Tree索引
索引多数是B-Tree(多路搜索树)索引,使用B-Tree存储数据(很多存储引擎使用的是B+Tree,每个椰子节点都包含指向下一个ie叶子节点的指针)
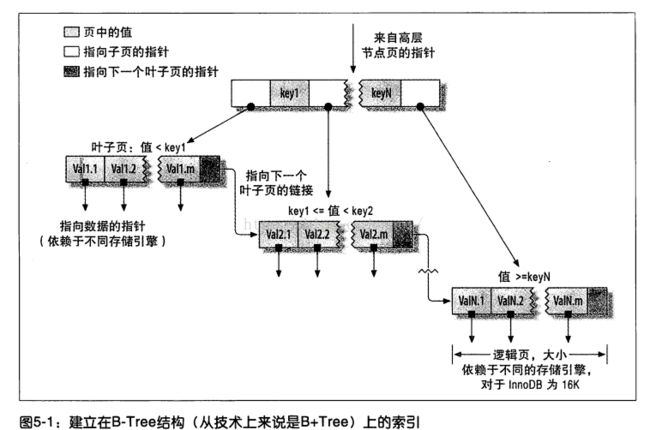
B-Tree适合全键值、键值范围或键前缀查找。限制:
(1)如果不是按照做音的最左列开始查找,则无法使用索引。(2)不能跳过索引中的列(3)如果查询中有列的范围查询,则其右边所有列都无法使用索引优化查找。如有LIKE等范围条件字段。
索引的优点:
(1)大大减少服务器需要扫描的数据量(2)帮助服务器避免排序和临时表(3)可将随机IO编程顺序IO。
索引比较适合中大型大小的表。小表往往全表扫描更快,对于特大型表,索引的代价会比较大,这时往往会采用直接查询需要的一组数据等的技术,例如分区技术。
->简化where条件,始终将索引列单独放在比较符合的一侧
在多列B-Tree中,索引列的顺序意味着索引首先按照最左列进行排序,其次是第二列等。索引顺序的法则是将选择性最高的索引放在最前列。
SQL优化建议:
· 检查 where 及 order by 涉及的列上是否建立索引,避免全表扫描。
· 检查语句中select * 是否真的需要全部字段信息,只输出需要的列。
· 应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,可以用 union all 替换。比如select id from t where num=10 or num=20 可用 select id from t where num=10 union all select id from t where num=20 替换。
· order by 实现全局排序,如果没有特殊要求,尽量不要在语句中使用排序。如果是热数据,可以考虑放到redis order set中。
· 合理使用union all替代union。union在合并两个结果集时会自动去重,会消耗很大资源。 同时先进行数据过滤,减少后续处理的记录数。 比如两个大表关联,可以通过条件将缩小结果集,然后再进行关联。
· 合理使用 group by 代替 distinct。比如select distinct num from a 可改成select num from a group by num。
· 检查 where 子句中判断时间范围。根据业务场景考虑按照时间分表分区,查询时只读取满足分区的数据。
· in 和 not in 也要慎用,否则会导致全表扫描,子查询表大的用 exists,表小的用 in,比如select num from a where num in(select num from b) 可以替换成select num from a where exists(select 1 from b where num=a.num)。
· 尽量用join替代子查询。比如select num from a where num in(select num from b) 可用 select num from a left join b on a.num=b.num。
需要说明一点,不是所有查询都要走索引。当查询的数据集超过记录总数的30%,使用全表扫描要比走索引要更有优势。
基于不同的查询条件,数据表上会建立多个索引。索引的选择可以通过Selectivity(选择性)这一指标衡量。Selectivity越趋近于1使用索引越合理,就像聚集索引。
索引合理性参考公式:Cardinality称为基数,代表数据域中不重复数据的数量。
Selectivity = Cardinality/(number of rows) * 100%