预热
几个关键单词:
- 图 - Graph - G
- 顶点 - Vertex - V 一般用小写 u,v表示
- 边 - Edge - E
- 邻接表 - Adjacency list - Adj
- 源顶点 - Source - S - s
- 目的顶点 - Destination - v
- 前驱 - Parent - π (点属性)
- 后继 - Successor (点属性)
- 距离 - Distance - d (点属性)
几种结点状态:
- 结点未被发现 - whiteState
- 结点被发现其邻接结点未被遍历完 - grayState
- 结点被发现其邻接结点已经遍历完 - blackState
几个关键专有名词:
- 稀疏图:|E| << |V|^2 (<< 远小于)的图
- 稠密图:|E| ≈ |V|^2的图
几个碉堡的天才:
- Prim
- Dijkstra
两个主要的图搜索方法:
- 广度优先搜索:BFS (Breadth First Search)
- 深度优先搜索:DFS (Depth First Search)
几种带数学符号的表达式:
图的表示
邻接链表:由|V|条链表的数组Adj所构成,每个节点有一条链表。Adj[u]存放与u邻接的结点。
邻接链表需要存储空间无论是有向图还是无向图均为Θ(V+E)。
邻接矩阵:图G的邻接矩阵表示一个|V|*|V|的矩阵A=(aij)予以表示,该矩阵满足: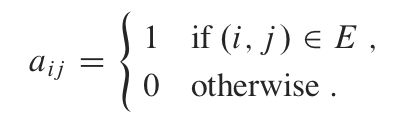
邻接矩阵对比邻接链表是不用在Adj链表中执行搜索操作,但是代价是增加了存储空间。邻接矩阵的空间需求为Θ(V^2)。
图属性的表示
比如顶点属性:v.d表示v的属性d。或者用一对顶点结点(u, v).f来表示u,v两点对应边的属性f。
广度优先搜索
即从s点开始找指定顶点v的过程中,需要发现所有距离s为k的结点以后才去发现距离s为k+1的结点,直到找到v为止。
BFS伪代码
// 初始化
for each vertex u ∈ G.V - {s}
u.color = whiteState
u.d = ∞
u.π = NIL
// s置灰入(已搜索)队列
s.color = grayState
s.d = 0
s.π = NIL
Q = ∅
ENQUEUE(Q, s)
// 遍历开始
while Q != ∅
u = DEQUEUE(Q)
for each v ∈ G.Adj[u]
if v.color == whiteState
v.color = grayState
v.d = u.d + 1
v.π = u
ENQUQUE(Q, v)
// u的邻接结点已经遍历完成,标志为黑色
u.color = blackState
Swift实现
【注:感觉很渣,类的封装,没有实现迭代器,没有实现符号重载。。。待修改】
enum VertexState: Int {
case white = 0
case gray = 1
case black = 2
}
class Vertex {
var parent: Vertex?
var color: VertexState!
var distance: Int
var vIndex: Int
init (_ index: Int) {
self.vIndex = index
self.parent = nil
self.color = VertexState.white
self.distance = 100000
}
}
var queue: [Vertex] = []
class Adjacency {
var adjacency: [Vertex] = []
}
class Graph {
var vertexArray: [Vertex]!
var adjacencyList: [Adjacency]!
init (vertexArray: [Vertex], adjacencyList: [Adjacency]) {
self.vertexArray = vertexArray
self.adjacencyList = adjacencyList
}
}
func BFS(inout graph: Graph, sourceVertex: Vertex) {
// sourceVertex置灰入队列
sourceVertex.color = VertexState.gray
sourceVertex.distance = 0
sourceVertex.parent = nil
queue.append(sourceVertex)
// 遍历
while queue.count > 0 {
var u = queue[0]
queue.removeAtIndex(0)
var adj = graph.adjacencyList[u.vIndex]
for var i = 0; i < adj.adjacency.count; i++ {
var v = adj.adjacency[i]
if v.color == VertexState.white {
v.color = VertexState.gray
v.distance = u.distance + 1
v.parent = u
queue.append(v)
}
u.color = VertexState.black
}
}
}
func printPath(g: Graph, s: Vertex, v: Vertex) {
if v.vIndex == s.vIndex {
print("\(s.vIndex)\t")
} else if v.parent == nil {
print("no path from s to v exists")
} else {
printPath(g, s, v.parent!)
print("\(v.vIndex)\t")
}
}
var vArray: [Vertex] = []
var adjList: [Adjacency] = []
for var i = 0; i < 8; i++ {
var vertex: Vertex = Vertex(i)
vArray.append(vertex)
}
// TEST CASE
var adj0: Adjacency = Adjacency()
adj0.adjacency = [vArray[1], vArray[2]]
var adj1: Adjacency = Adjacency()
adj1.adjacency = [vArray[0], vArray[3], vArray[4]]
var adj2: Adjacency = Adjacency()
adj2.adjacency = [vArray[0], vArray[5]]
var adj3: Adjacency = Adjacency()
adj3.adjacency = [vArray[1], vArray[4], vArray[6]]
var adj4: Adjacency = Adjacency()
adj4.adjacency = [vArray[1], vArray[3], vArray[6], vArray[7]]
var adj5: Adjacency = Adjacency()
adj5.adjacency = [vArray[2]]
var adj6: Adjacency = Adjacency()
adj6.adjacency = [vArray[3], vArray[4], vArray[7]]
var adj7: Adjacency = Adjacency()
adj7.adjacency = [vArray[4], vArray[6]]
adjList = [adj0, adj1, adj2, adj3, adj4, adj5, adj6, adj7]
var g: Graph = Graph(vertexArray: vArray, adjacencyList: adjList)
BFS(&g, vArray[0])
printPath(g, vArray[0], vArray[2])
上述用例对应的图: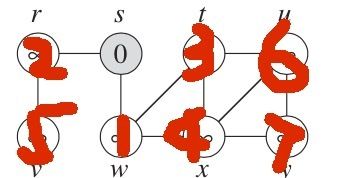
广度优先树
BFS在搜索的过程中也在创建一棵广度优先树。有如下定义:
对于图G = (V, E)和源节点s,G的前驱子图为Gπ = (Vπ, Eπ),其中Vπ = {v ∈ V: v.π != nil} ∪ {s}, Eπ = {(v.π, v): v∈ Vπ - {s}}。【前驱:因为顶点结点中存的是父节点指针或者索引】
深度优先搜索
与广度优先搜索不同的是,广度优先搜索的前驱子图形成一棵树,但是深度优先搜索的前驱子图可能由多棵树组成,可以从多个源结点开始搜索。
与广度优先搜索不同是深度优先更注重“深入”与“回溯”。深度优先搜索总是对最近才发现的结点v的出发边进行探索,知道该结点的所有触发边都被发现为止。
深度优先搜索的每个结点多了两个时间戳属性:v.d(discover)发现的时间戳以及v.f(finish)遍历完成的时间戳。显然有:
1 <= u.d < u.f <= 2|V|
深度优先的前途子图定义:设图Gπ = (V, Eπ),其中Eπ = {(v.π, v): v∈V 且v.π != NIL}.
深度优先搜索的算法运行时间为Θ(V+E),证明略。
DFS伪代码
DFS(G)
for each vertex u ∈ G.V
u.color = whiteState
u.π = NIL
time = 0 // 全局变量time
for each vertex u ∈ G.V
if u.color == whiteState
DFS-VISIT(G, u)
DFS-VISIT(G, u)
time = time + 1
u.d = time
u.color = grayState
for each v ∈ G.Adj[u]
if v.color == whiteState
v.π = u
DFS-VISIT(G, v)
u.color = blackState
time = time + 1
u.f = time
Swift实现
var gTime = 0
enum VertexState: Int {
case white = 0
case gray = 1
case black = 2
}
class Vertex {
var discoverTime : Int
var finishTime: Int
var parent: Vertex?
var color: VertexState!
var distance: Int
var vIndex: Int
init (_ index: Int) {
self.discoverTime = 0
self.finishTime = 0
self.vIndex = index
self.parent = nil
self.color = VertexState.white
self.distance = 100000
}
}
var queue: [Vertex] = []
class Adjacency {
var adjacency: [Vertex] = []
}
class Graph {
var vertexArray: [Vertex]!
var adjacencyList: [Adjacency]!
init (vertexArray: [Vertex], adjacencyList: [Adjacency]) {
self.vertexArray = vertexArray
self.adjacencyList = adjacencyList
}
}
func DFSVisit(inout graph: Graph, u: Vertex) {
gTime++
u.discoverTime = gTime
u.color = VertexState.gray
var adj = graph.adjacencyList[u.vIndex]
for var i = 0; i < adj.adjacency.count; i++ {
var v = adj.adjacency[i]
if v.color == VertexState.white {
v.parent = u
DFSVisit(&graph, v)
}
}
u.color = VertexState.black
gTime++
u.finishTime = gTime
}
func DFS(inout graph: Graph) {
for var i = 0; i < graph.vertexArray.count; i++ {
var u = graph.vertexArray[i]
if u.color == VertexState.white {
DFSVisit(&graph, u)
}
}
}
func printPath(g: Graph, s: Vertex, v: Vertex) {
if v.vIndex == s.vIndex {
print("\(s.vIndex)\t")
} else if v.parent == nil {
print("no path from s to v exists")
} else {
printPath(g, s, v.parent!)
print("\(v.vIndex)\t")
}
}
var vArray: [Vertex] = []
var adjList: [Adjacency] = []
for var i = 0; i < 8; i++ {
var vertex: Vertex = Vertex(i)
vArray.append(vertex)
}
// TEST CASE
var adj0: Adjacency = Adjacency()
adj0.adjacency = [vArray[4]]
var adj1: Adjacency = Adjacency()
adj1.adjacency = [vArray[0], vArray[5]]
var adj2: Adjacency = Adjacency()
adj2.adjacency = [vArray[1], vArray[5]]
var adj3: Adjacency = Adjacency()
adj3.adjacency = [vArray[6], vArray[7]]
var adj4: Adjacency = Adjacency()
adj4.adjacency = [vArray[1]]
var adj5: Adjacency = Adjacency()
adj5.adjacency = [vArray[4]]
var adj6: Adjacency = Adjacency()
adj6.adjacency = [vArray[2], vArray[5]]
var adj7: Adjacency = Adjacency()
adj7.adjacency = [vArray[3], vArray[6]]
adjList = [adj0, adj1, adj2, adj3, adj4, adj5, adj6, adj7]
var g: Graph = Graph(vertexArray: vArray, adjacencyList: adjList)
DFS(&g)
for var i = 0; i < vArray.count; i++ {
println("*******************")
println("\(i) node discover time is \(vArray[i].discoverTime)")
println("\(i) node finish time is \(vArray[i].finishTime)")
}
上述代码用例图: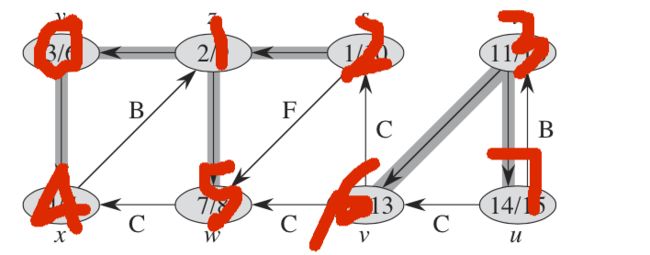
深度优先森林
深度优先搜索的前驱子图形成一个由多棵深度优先树构成的深度优先森林。森林Eπ中的边仍然称为树边。
拓扑排序
对于一个有向无环图G = (V, E)来说,其拓扑排序是G中所有结点的一种线性次序,其次序满足如下条件:如果图G包含边(u, v),则结点u在拓扑排序中处于结点v的前面。
伪代码
TOPOLOGICAL-SORT(G)
调用 DFS(G)计算每个结点v的完成时间v.f
当每个结点扫描结束的时候,将其插入到链表的前端
返回结点的链表
Swift实现
略
关键定理
拓扑排序算法生成的是有向无环图的拓扑排序。
P:
假定在有向无环图G = (V, E)运行DFS来计算结点的完成时间。只要证明对于不同的结点u,v∈V,如果图G包含一条从u到v的边,则v.f < u.f。在DFS探索任一条边(u, v)的时候,结点v不可能是灰色(gray),如果是,则意味着v将是u的祖先(π)。因此v要么是白色要么是黑色。如果结点v是白色,那么则为u的后代,因此v.f < u.f。如果v是黑色,则对其全部处理已经完成,因此v.f已设置。因为我们还需要对u进行探索,u.f尚未设定。即u.f > v.f。因此对于任一条边(u, v),必有v.f < u.f。
强连通分量
续