用各种工具对数据进行分类汇总
数据分类汇总的方法有很多种,工具也有很多,这次为大家一一介绍,各种工具如何进行分类汇总,大家自行判断,觉得哪种最好用,就用哪种,毕竟工具不重要,高效出结果才最重要。
为了方便举例,所用的数据集就是鸾尾花数据集,5个字段(Sepal.Length、Sepal.Width、Petal.Length、Petal.Width、Species),每个字段150个观测值,
1)根据Species来计算各种类型的花萼的长度均值
1.Excel—数据透视表
在Excel中选择插入—数据透视表—选中所有的数据——在右侧的行标签选中Species,数值选择Sepal.Length,值字段设置计算类型为平均值

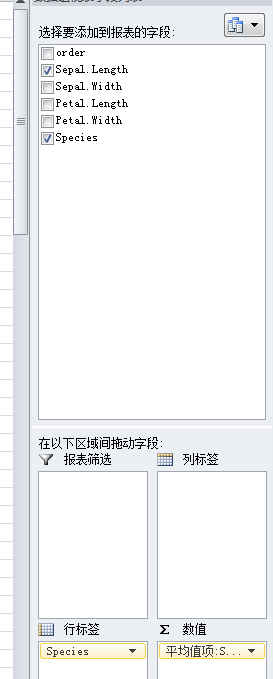
2.SPSS—分析—个案汇总
将数据导入spss中,选择分析——个案汇总
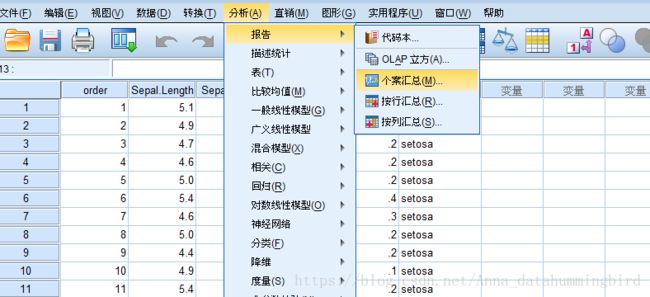
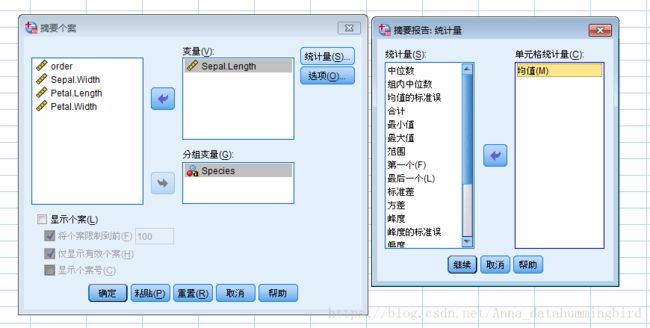
在分组变量中选择Species,在变量中选择Sepal.Length,在统计量中选择均值,记得不要勾选显示个案哦!输出结果如下:
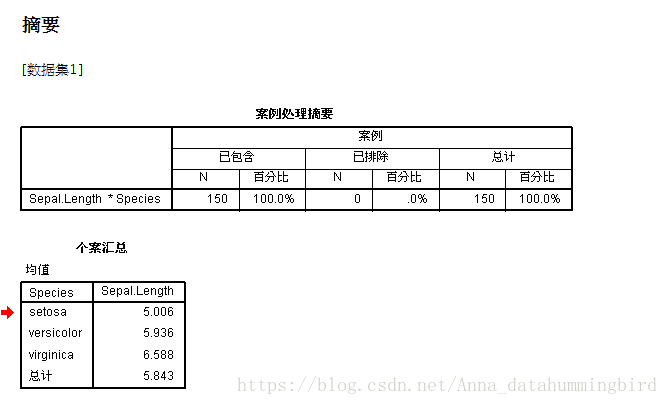
可以看到数据没有缺失值,汇总结果在图表中展示。SPSS操作偏傻瓜式,比较好上手,输出结果也很直观。
3. R—aggregate()函数
加载dplyr包,使用aggregate()函数,选定统计的字段、分类的字段以及统计函数代码如下:
> result<-aggregate(x=iris$Sepal.Length, by= list(iris$Species), FUN = mean)
> result
Group.1 x
1 setosa 5.006
2 versicolor 5.936
3 virginica 6.588R语言的优势不言而喻,一行代码出结果,直观,唯一的缺陷是没有对合计值求均值。
2)对花瓣的长度Petal.Length进行分类,0~2定义为短,3~4定义为正常,5~6定义为长,然后统计各种类型的各种情况
1.Excel实现,ifelse函数+数据透视表
首先定义出花瓣情况:IF(D2>=4,"长",IF(D2>=3,"正常","短"))
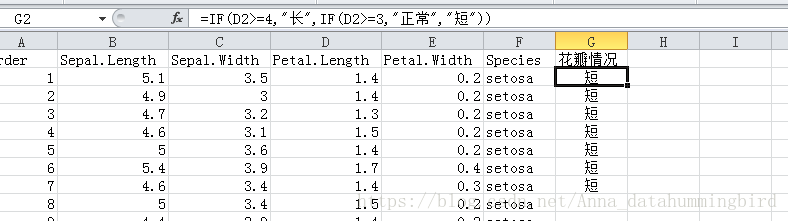
然后输出统计结果
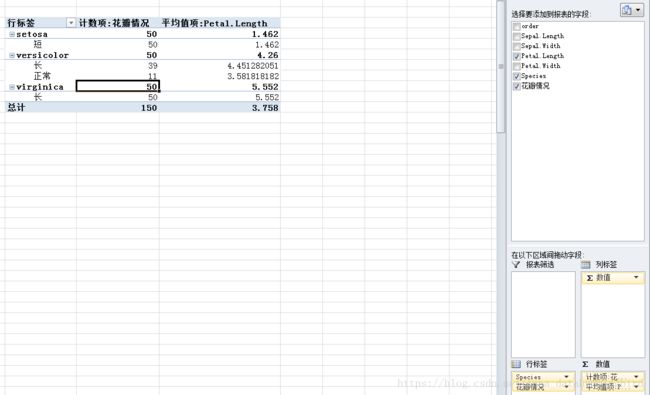
这里的目录分为两级,一级是种类,二级是花瓣情况,分别统计了各种情况花瓣的数量和对应均值
2)SPSS—转换—重新编码为不同变量+个案汇总

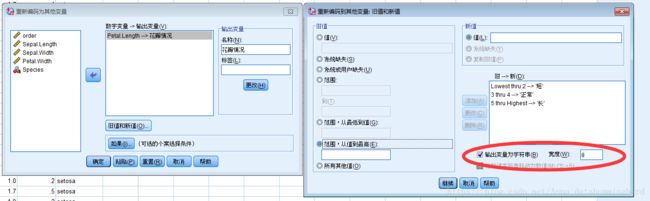
输出花瓣情况后,选择个案汇总,将Species和花瓣情况都选入分组变量,变量中输入Petal.Length,统计量选择个案数和均值
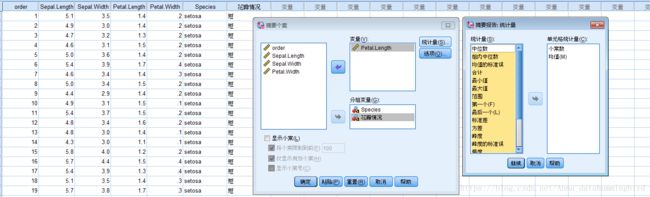
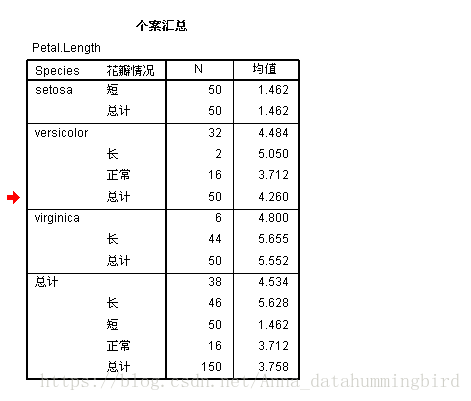
输出个案汇总结果
3. R实现:需要用到within函数和aggregate函数,利用within函数定义出长、正常、短,利用aggregate函数按照Species和花瓣情况计算均值
testdata<-within(
iris,{
a<-NA
a[iris$Petal.Length<=2]<-"短"
a[iris$Petal.Length<=4&iris$Petal.Length>=2]<-"正常"
a[iris$Petal.Length>4]<-"长"
}
)
aggregate(testdata$Petal.Length,by=list(testdata$Species,testdata$a),FUN="mean")> aggregate(testdata$Petal.Length,by=list(testdata$Species,testdata$a),FUN="mean")
Group.1 Group.2 x
1 setosa 短 1.462000
2 versicolor 长 4.517647
3 virginica 长 5.552000
4 versicolor 正常 3.712500> table(list(testdata$Species,testdata$a))
.2
.1 短 长 正常
setosa 50 0 0
versicolor 0 34 16
virginica 0 50 0直接对Species和花瓣情况统计,可以很直观看到汇总结果。
以上就是对分类汇总分享的内容,有问题欢迎沟通讨论!