ngxin请求行与请求头处理
上一篇文件分析了nginx服务器接收到客户端的连接后,会创建一个连接对象,但此时没有涉及到任何http模块。本文在上一篇基础下分析nginx接收到http请求后的初始化流程、接收http请求行、以及接收http请求头部的流程。先来看下从ngixn服务器接收到客户端的连接,到开始接收http数据(请求行,请求头,包体)时,会做哪些操作。
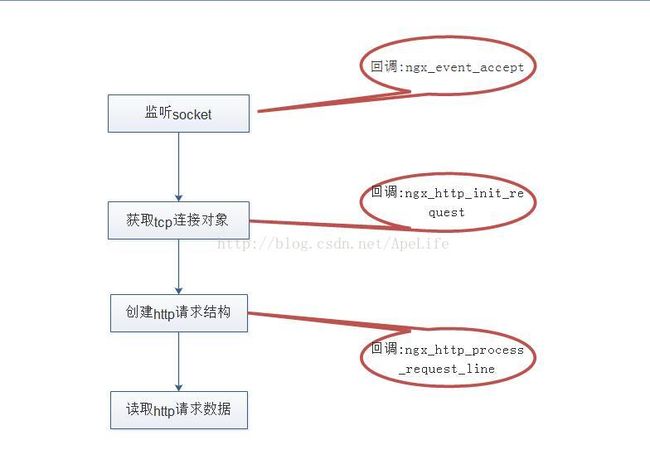
从图中可以看出,ningx在实际接收http数据时,一共会经过4个阶段。
(1)监听socket阶段: 对于每一个work进程,在进程间同步时,如果其中一个work进程抢到了监听socket,则可以把这些监听socket加入到epoll中,同时会设置读事件的回调为:ngx_event_accept。监听事件在前面的博文中已经分析过了,可以参考:http://blog.csdn.net/apelife/article/details/53647316这篇文章的分析。
(2)获取tcp连接对象阶段: 当ngx_event_accept函数被调用时,会与客户端建立一个tcp连接。在建立完tcp连接后,会获取一个连接对象,同时这个连接对象还会关联一个读事件,一个写事件。这样对于每一个tcp连接,都会有一个读事件,一个写事件与之一一对应。同时这个阶段会设置读事件的回调函数为: nginx_http_init_request。获取TCP连接阶段在前面的博文也已经分析过了,可以参考:http://blog.csdn.net/apelife/article/details/53892405这篇文章。
(3)创建http请求结构阶段: 获取tcp连接对象阶段,会设置读事件的回调为ngx_http_init_request,如果此时有客户端发起了http请求,则这个回调会被调用。用于建立一个ngx_http_request_t这样的http结构。在这个阶段只是创建一个http请求结构,并创建一个接收缓冲区,一个发送缓冲区等,并没有实际处理来自客户端的数据。与此同时会修改读事件的回调为:ngx_http_process_request_line, 在这个回调中开始真正读取来自客户端的http请求行数据, 例如: /GET /home/abc.txt HTTP/1.1
有个疑问,当客户端与服务器进行了tcp连接,为什么不在获取tcp连接对象阶段创建一个http请求结构呢? 事实上,http框架并不会在tcp建立成功后就开始初始化请求,而是在这个连接对应的套接字缓冲区确实接收到了客户端发来的请求内容时,才会创建一个http请求结构。这种设计体现了Nginx出于高性能的考虑减少了无畏的内存消耗,降低了一个请求占用的内存资源。因此当有客户端建立了tcp连接后一直都没有发送内容,nginx服务器检测到超时都没有收到客户端的请求,则会关闭这个tcp连接。
(4)读取http请求数据阶段: 在这个阶段开始实际的请求行,请求头,请求包体的读取。
前两个阶段在之前的博文中已经分析过了,因此本文将重点分析创建http请求结构阶段与读取http请求数据阶段
一、创建http请求结构
ngx_http_init_request函数在客户端发起http请求时,创建一个http请求结构ngx_http_request_t。这个函数的逻辑比较多,但整体功能就是创建请求结构,并为这个结构的成员初始化,例如,创建接收缓冲区,发送缓冲区,查找这个tcp连接对应的默认server块,设置读事件的回调等。这个函数并没有实际读取数据,只是初始化http请求结构,但会设置读事件的回调为ngx_http_process_request_line,用于真正读取请求行数据。
//首次建立tcp连接后,读事件的回调,用于创建一个http请求对象
// 1、创建一个ngx_http_request_t对象
// 2、开辟请求对象的接收缓冲区与发送缓冲区成员,以及其它成员初始化
// 3、或者这个tcp连接对应的server配置块信息
// 4、设置读事件的回调
static void ngx_http_init_request(ngx_event_t *rev)
{
c = rev->data;
//事件超时,也就是没有在一段时间内收到http头部请求,则关闭连接。
//前面已经分析过了,tcp建立成功后,但客户端一直都不发送http请求,则服务器检测到超时后,会关闭这个连接。
//如果超时,ngx_event_expire_timers函数会调用该回调,会将timeout设置为1
if (rev->timedout)
{
ngx_http_close_connection(c);
return;
}
//统计请求的连接数,
//因为一个一个tcp连接可以对应多个请求,例如当一个http请求结束后,这个tcp可以不关闭,这样在有新http请求到来时,
//仍然使用的是这个tcp连接。因此会统计基于这个tcp连接,接收了多少个客户端请求
c->requests++;
//开辟一个http请求结构
r = ngx_pcalloc(c->pool, sizeof(ngx_http_request_t));
port = c->listening->servers;
//查找到这个监听对象所在的ningx.conf配置文件中的哪个server块
if (port->naddrs > 1)
{
//将监听地址struct sockaddr结构转为点分十进制ip地址格式(172.16.3.180)
if (ngx_connection_local_sockaddr(c, NULL, 0) != NGX_OK)
{
ngx_http_close_connection(c);
return;
}
switch (c->local_sockaddr->sa_family)
{
default: /* AF_INET */
sin = (struct sockaddr_in *) c->local_sockaddr;
//找到server块的位置
addr = port->addrs;
for (i = 0; i < port->naddrs - 1; i++)
{
if (addr[i].addr == sin->sin_addr.s_addr)
{
break;
}
}
addr_conf = &addr[i].conf;
break;
}
}
//查找到虚拟主机位置,里面有一个哈希表,存放了监听同一个socket的所有域名。
//后续在解析http头部时会根据http请求头部的host字段,在这个哈希表中查找真正的server块,
//而不是采用下面这个默认server块的配置信息
r->virtual_names = addr_conf->virtual_names;
//当前这个请求是使用nginx.conf配置中的哪一个默认server块来处理请求的
//后面在解析http头部时会查找哈希表从而获取正在server块,这里只是给一个默认的server块
cscf = addr_conf->default_server;
//使用默认server块的配置,设置这个请求对应的main,srv,loc级别的配置项。后续会修改
r->main_conf = cscf->ctx->main_conf;
r->srv_conf = cscf->ctx->srv_conf;
r->loc_conf = cscf->ctx->loc_conf;
//注册事件回调,用于接收并解析完整的http请求行,
//而之前的回调方法为ngx_http_init_request, 则用于初始化请求
rev->handler = ngx_http_process_request_line;
r->read_event_handler = ngx_http_block_reading;
//开辟接收缓冲区,缓存区大小client_header_buffer_size
if (c->buffer == NULL)
{
c->buffer = ngx_create_temp_buf(c->pool, cscf->client_header_buffer_size);
}
//ngx_http_request_s对象的header_in成员指向和ngx_connection_t的buffer指向同一个接收缓冲区
//为什么要这么做呢? 还是因为一个tcp连接可以对应多个http请求,多个http请求公用连接对象的接收缓冲区
//当一个http请求结束后,又新建了一个新的http请求,则这个新http请求可以继续复用这个连接对象的接收缓冲区,而不需要重新创建
if (r->header_in == NULL)
{
r->header_in = c->buffer;
}
//创建发送缓冲区,这个缓冲区存放所有要发送给客户端的http响应头部信息
//例如: content_type:text/html
ngx_list_init(&r->headers_out.headers, r->pool, 20,sizeof(ngx_table_elt_t));
//存放所有http模块对一个请求的上下文结构, 每一个http模块都可以介入这个请求
//因此开辟这样的空间
r->ctx = ngx_pcalloc(r->pool, sizeof(void *) * ngx_http_max_module);
cmcf = ngx_http_get_module_main_conf(r, ngx_http_core_module);
//开辟变量数组空间
r->variables = ngx_pcalloc(r->pool, cmcf->variables.nelts
* sizeof(ngx_http_variable_value_t));
//表示客户端发起的独立连接,不是nginx服务器主动发起向头部服务器的连接
c->single_connection = 1;
//tcp连接未销毁
c->destroyed = 0;
//保存原始请求
r->main = r;
r->count = 1;
//记录请求开始处理的时间,用于限速功能,后续会根据请求的开始时间,来限制是否本次需要给客户端发送响应,从而达到限速目的
tp = ngx_timeofday();
r->start_sec = tp->sec;
r->start_msec = tp->msec;
//调用ngx_http_process_request_line开始接收、解析http请求行
rev->handler(rev);
}需要注意的是,如果当前http请求已经处理完了,http请求是被释放了,但http连接并没有关闭, 此时会把读事件的回调再次设置为ngx_http_init_request。如果客户端再发起http请求,则会在这个连接上再次调用这个函数,从而创建一个新的http请求对象。
二、接收http请求行
在分析接收http请求行时,先来看下nginx服务器是如何存储http请求行、请求头部的。

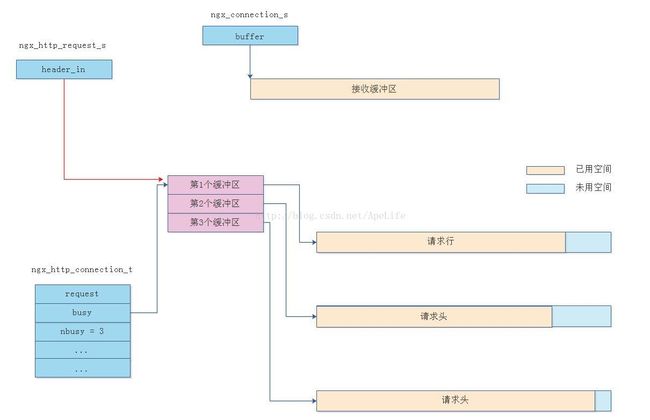
图中有三个缓冲区,第一个缓冲区存放的是请求行,例如: /GET /home/abc.txt HTTP/1.1内容。 第二,三个缓冲区则存放的http请求头部信息,例如: connection: keep-alive; host: mypage.jp。由于http请求头部很多,因此可能一个缓冲区存放不下所有的请求头部,因此图中使用了2个缓冲区存放头部信息。
ngx_http_process_request_line函数则用来接收来自客户端的http请求行,将把读取到的请求行数据存放到http请求结构中的header_in缓冲区中。然后使用状态机解析这个缓冲区中的数据,从而提取到请求行数据,并把解析后的结果存放到ngx_http_request_t结构的相应成员中。当然如果http请求行太长导致一次性无法从套接字缓冲区中读取到应用层缓冲区,则这个函数会再下一次事件循环中被调用,读取剩余的数据。函数也会修改读事件的回调为:ngx_http_process_request_headers, 用于接收http请求头部
//接收http请求行(格式:GET /uri HTTP/1.1), 然后使用状态机解析这个请求行,
//并把结果存放到ngx_http_request_t结构的相应成员中
static void ngx_http_process_request_line(ngx_event_t *rev)
{
//如果超时后都没有收到http头部信息,则退出
if (rev->timedout)
{
ngx_http_close_request(r, NGX_HTTP_REQUEST_TIME_OUT);
return;
}
rc = NGX_AGAIN;
for ( ;; )
{
if (rc == NGX_AGAIN)
{
//从内核中读取数据,存放到应用层的接收缓冲区
n = ngx_http_read_request_header(r);
//读取过程发送错误,或者本次没有接收到tcp流(缓冲区没有内容),则退出。待下次事件循环后在执行本函数
if (n == NGX_AGAIN || n == NGX_ERROR)
{
return;
}
}
//使用状态机解析已经收到的tcp字符流
rc = ngx_http_parse_request_line(r, r->header_in);
//解析完了http请求行,则保存请求行的内容到相应成员
if (rc == NGX_OK)
{
//请求行的位置
r->request_line.len = r->request_end - r->request_start;
r->request_line.data = r->request_start;
//更新uri内容
r->uri.data = ngx_pnalloc(r->pool, r->uri.len + 1);
if (r->uri.data == NULL)
{
ngx_http_close_request(r, NGX_HTTP_INTERNAL_SERVER_ERROR);
return;
}
//初始化请求头部链表,为获取请求头做准备。因此接下来要开始获取http请求头部,
//将获取到的头部信息保存到这个链表中,因此要开辟链表空间
if (ngx_list_init(&r->headers_in.headers, r->pool, 20,
sizeof(ngx_table_elt_t))
!= NGX_OK)
{
ngx_http_close_request(r, NGX_HTTP_INTERNAL_SERVER_ERROR);
return;
}
//重新设置读事件回调,准备接收http头部
rev->handler = ngx_http_process_request_headers;
//接收头部
ngx_http_process_request_headers(rev);
return;
}
//请求头解析过程中遇到错误,一般为客户端发送了不符合协议规范的头部,返回400错误
if (rc != NGX_AGAIN)
{
ngx_http_finalize_request(r, NGX_HTTP_BAD_REQUEST);
return;
}
//判断接收缓冲区是否还有空闲的内存,没有则开辟更大的缓冲区
if (r->header_in->pos == r->header_in->end)
{
//开辟一个大的缓冲区,并把旧缓冲区的数据拷贝到新缓冲区中
rv = ngx_http_alloc_large_header_buffer(r, 1);
}
}
}
ngx_http_parse_request_line这个函数会使用状态机解析存放在r->header_in缓冲区中的数据,进而获取到http请求行中的各字段,存放在r中的相应的相应成员中。这个解析过程并不复杂,读者仔细分析下代码接就可以明白。但有2点需要特别说明:
(1)状态机解析接收缓冲区的数据,进而提取http请求行中的各个字段时。如果缓冲区的数据不足以解析到所有http请求行字段。则需要保存已经解析到缓冲区的哪个位置,以及当前状态机的状态, 目的是为了再次从socket中读取数据到缓冲区中后,下一次开始进入状态机解析函数时,可以知道当前的状态,以及从哪个位置开始解析。
(2)如果状态机解析函数一次性成功解析完所有的http请求行数据,则也需要保存已经解析到缓冲区的哪个位置,目的是为了接下来获取http请求头部时,可以把http请求头部的数据放到缓冲区的哪个位置。 同时把状态机状态设置为初始状态,目的是为了在接下来状态机解析http请求头部时,从初始状态开始解析http请求头部。
如果http的请求行太长了,接收缓冲区无法存放这个请求行,那怎么处理。nginx使用ngx_http_alloc_large_header_buffer这个函数重新开辟一个新缓冲区,并把旧缓冲区中的数据拷贝到新缓冲区中,因此这个操作有可能会产生上图的缓冲区内存布局。
//开辟一个大的缓冲区,并把旧缓冲区的数据拷贝到新缓冲区中
//request_line值为1表示处理的是请求行,值为0表示处理的是请求头
static ngx_int_t ngx_http_alloc_large_header_buffer(ngx_http_request_t *r,
ngx_uint_t request_line)
{
/* 在解析请求行阶段,如果客户端在发送请求行之前发送了大量回车换行符将
* 缓冲区塞满了,针对这种情况,nginx只是简单的重置缓冲区,丢弃这些垃圾
* 数据,不需要分配更大的内存。 */
if (request_line && r->state == 0)
{
/* the client fills up the buffer with "\r\n" */
//这些\r\n也被当做是http请求的一部分,也会进行统计长度。虽然是垃圾数据
r->request_length += r->header_in->end - r->header_in->start;
//重置缓冲区,丢弃这些垃圾数据,不需要分配更大的内存。
r->header_in->pos = r->header_in->start;
r->header_in->last = r->header_in->start;
return NGX_OK;
}
/* 保存请求行或者请求头在旧缓冲区中的起始地址 */
old = request_line ? r->request_start : r->header_name_start;
//如果一个大缓冲区还装不下请求行或者一个请求头,则返回错误
//考虑一个场景,如果之前的接收缓冲区大小为512字节,而设置的每一个最大缓冲区大小为256字节,比原有的
//缓存还小,肯定是一个非法的请求行
if (r->state != 0
&& (size_t) (r->header_in->pos - old)
>= cscf->large_client_header_buffers.size)
{
return NGX_DECLINED;
}
hc = r->http_connection;
if (hc->nbusy < cscf->large_client_header_buffers.num)
{
/* 检查给该请求分配的请求头缓冲区个数是否已经超过限制,默认最大个数为4个 */
if (hc->busy == NULL)
{
hc->busy = ngx_palloc(r->connection->pool,cscf->large_client_header_buffers.num * sizeof(ngx_buf_t *));
}
/* 如果还没有达到最大分配数量,则分配一个新的大缓冲区 */
b = ngx_create_temp_buf(r->connection->pool,cscf->large_client_header_buffers.size);
}
else
{
/* 如果已经达到最大的分配限制,则返回错误 */
return NGX_DECLINED;
}
/* 将从空闲队列取得的或者新分配的缓冲区加入已使用队列 */
hc->busy[hc->nbusy++] = b;
/*
* 因为nginx中,所有的请求头的保存形式都是指针(起始和结束地址),
* 所以一行完整的请求头必须放在连续的内存块中。如果旧的缓冲区不能
* 再放下整行请求头,则分配新缓冲区,并从旧缓冲区拷贝已经读取的部分请求头,
* 拷贝完之后,需要修改所有相关指针指向到新缓冲区。
* status为0表示解析完一行请求头之后,缓冲区正好被用完,这种情况不需要拷贝
*/
if (r->state == 0)
{
//更新请求行的长度
r->request_length += r->header_in->end - r->header_in->start;
//header_in指向这个新的空缓冲区
r->header_in = b;
return NGX_OK;
}
//更新请求行的长度(有个疑问? old - r->header_in->start首次有可能为0, 那request_length +0相当于没有加,
//是否意味着这部分数据没有统计长度呢? 其实不是,nginx这里的设计采用的是每次开辟一个新的内存缓冲块时,才统计
//上一个缓冲区中数据大小。例如在下次接收请求头时,如果还需要开辟另一个块才能接收完成的头部信息,
//则此时old - r->header_in->start就是这个上一个内存块有效数据大小)
r->request_length += old - r->header_in->start;
new = b->start;
/* 拷贝旧缓冲区中不完整的请求头 */
ngx_memcpy(new, old, r->header_in->pos - old);
//更新新缓冲区的pos,last指向
b->pos = new + (r->header_in->pos - old);
b->last = new + (r->header_in->pos - old);
//header_in指向这个新的缓冲区, 连接对象的缓冲区仍然为旧的缓冲区,大小没有改变
r->header_in = b;
return NGX_OK;
}原先http请求对象中的header_in缓冲区指向的是连接对象的buffer缓冲区。nginx为什么要这么做? 还是因为一个tcp连接可以对应多个http请求,多个http请求公用连接对象的接收缓冲区。当一个http请求结束后,又新建了一个新的http请求,则这个新http请求可以继续复用这个连接对象的接收缓冲区,而不需要重新创建。内部布局如下图:
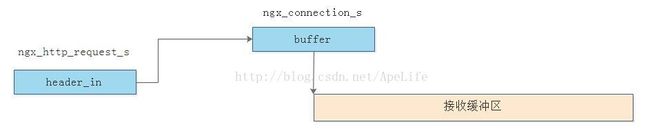
而如果客户端发的http请求行,或者http请求头部长度太长,导致连接对象的接收缓冲区buffer不能够存储这么长的数据。nginx服务器则会在当前这个http请求上创建多个接收缓冲区。在http请求上创建的缓冲区是这个http请求独有的,与连接对象的接收缓冲区buffer没有关系。具体在http请求对象上创建多少个缓冲区以及每一个缓冲区的大小是可以在nginx.conf配置文件中指定的。通常会创建4个接收缓冲区,每一个接收缓冲区为1024字节。此时的内存布局如下图,可以看到这个http请求对象中的header_in指向自己创建出来的接收缓冲区,而不是指向连接对象的接收缓冲区buffer
 、
、
ngx_http_connection_t对象中的busy, free成员就是用于维护http的接收缓冲区。busy表示在用缓冲区,用来接收来自客户端的http请求行,或者请求头数据。而free表示空闲缓冲区,当不需要接收来自客户端的数据时,将把空间从busy移动到free缓冲区中。
三、接收http请求头部
接收http请求头部与请求行类似,都是把内容存放到r->header_in缓冲区。然后使用状态机解析这个缓冲区的数据,进而获取到每一个http请求头部,最后将解析后的头部信息保存到链表中。当然如果http请求头部太多导致一次性无法从套接字缓冲区中读取到应用层缓冲区,则这个函数会再下一次事件循环中被调用,读取剩余的数据。在接收完http请求头部后,还会调用ngx_http_process_request函数,由各个模块共同处理接收到的请求行、请求头部信息。如下图所示,nginx服务器将会把接收到来自客户端的每一个http请求头部放入到headers链表中。

//解析http请求头部,把接收到的内容存放到r->header_in缓冲区。
//然后使用状态机解析这个缓冲区的数据,进而获取到每一个http请求头部,
//最后将解析后的头部信息保存到链表中
static void ngx_http_process_request_headers(ngx_event_t *rev)
{
//如果超时后都没有收到http头部信息,则退出。
if (rev->timedout)
{
ngx_http_close_request(r, NGX_HTTP_REQUEST_TIME_OUT);
return;
}
rc = NGX_AGAIN;
for ( ;; )
{
if (rc == NGX_AGAIN)
{
//当接收缓冲区没有空间了,则开辟更大的缓冲区。同时将旧缓冲区的内容拷贝到新缓冲区中
if (r->header_in->pos == r->header_in->end)
{
rv = ngx_http_alloc_large_header_buffer(r, 0);
}
//读取接收缓冲区的tcp流
n = ngx_http_read_request_header(r);
//一次性不能读取完,则在下次事件触发时读取剩余数据
if (n == NGX_AGAIN || n == NGX_ERROR)
{
return;
}
}
//使用状态机获取http请求头部中的每一个键值对,underscores_in_headers表示key是否支持下划线
rc = ngx_http_parse_header_line(r, r->header_in, cscf->underscores_in_headers);
//处理一个http请求头成功,则将这个请求头的key,value插入到链表中
if (rc == NGX_OK)
{
h = ngx_list_push(&r->headers_in.headers);
if (h == NULL)
{
ngx_http_close_request(r, NGX_HTTP_INTERNAL_SERVER_ERROR);
return;
}
h->hash = r->header_hash;
//http请求头的key,例如context-length:30,则key为context-length
h->key.len = r->header_name_end - r->header_name_start;
h->key.data = r->header_name_start;
h->key.data[h->key.len] = '\0';
//http请求头的value,例如context-length:30,则value为30
h->value.len = r->header_end - r->header_start;
h->value.data = r->header_start;
h->value.data[h->value.len] = '\0';
//查找key对应的ngx_http_header_t结构,这个哈希表在ngx_http_init_headers_in_hash函数中
//创建并赋值,而ngx_http_init_headers_in_hash又被http模块的初始化函数ngx_http_block调用
//将ngx_http_headers_in数组的值插入到哈希表
hh = ngx_hash_find(&cmcf->headers_in_hash, h->hash,
h->lowcase_key, h->key.len);
//调用常用http请求头部字段的回调,一般都是将headers_in中常用字段指针指向链表中相应头部节点
if (hh && hh->handler(r, h, hh->offset) != NGX_OK)
{
return;
}
continue;
}
//http的所有头部都请求完成,调用处理请求头部函数,处理请求头
if (rc == NGX_HTTP_PARSE_HEADER_DONE)
{
//更新http请求的头部长度(包括请求行)
r->request_length += r->header_in->pos - r->header_in->start;
// 1、根据host查找server块,从而获取到正在的server块,因为前面一直使用的是默认server块的配置
// 2、http请求头部各个字段合法性校验
rc = ngx_http_process_request_header(r);
//到此为止http请求行与请求头已经请求完成,开始对收到的请求进行处理。
//也就是调用各个http模块共同处理这个请求
ngx_http_process_request(r);
return;
}
//缓冲区中的数据不能够构成一个http请求头,则需要继续读取数据到缓冲区中
if (rc == NGX_AGAIN)
{
continue;
}
return;
}
}
(1) ngx_http_parse_header_line这个函数使用状态机解析http请求头部中的每一个键值对,underscores_in_headers表示http头部是否支持下划线 。该函数一次只解析一个http请求头部,因此需要反复调用。同解析http请求行的过程类似,不论解析完一个http请求头部、或者解析完所有的http请求头部、或者在一次调用中无法解析完一个http头部, 都需要保存当前的状态机状态,以及解析到缓冲区的哪一个位置。以便再次解析时,可以知道现在解析到哪个状态,以及从缓冲区中的哪个位置开始解析。
(2) nginx预先定义了一些常见的http请求头部,对这些常见的http头部信息,nginx服务器会将他们插入到哈希表中。因此在上面的代码中,会有根据解析后得到的请求头部,查找哈希表流程。查找到后,调用这个头部的回调函数,目的是为了使用指针指向链表中这个头部所在的节点。避免每次要用这个http头部时,得遍历链表进行查找。
//http请求头部常用头部
ngx_http_header_t ngx_http_headers_in[] =
{
{ ngx_string("Host"), offsetof(ngx_http_headers_in_t, host),
ngx_http_process_host },
{ ngx_string("Connection"), offsetof(ngx_http_headers_in_t, connection),
ngx_http_process_connection },
...
...
} 至此,http请求结构的创建、接收请求行、以及接收请求头部已经分析完成了。下一篇将分析http各个模块是如何协作处理收到的这些请求行,请求头部的。