Python3.X网络爬虫学习(一)
刚刚研一,导师要求我开始学习Python网络爬虫,于是结合《精通Python网络爬虫:核心技术、框架与项目实战》和各种博客对比学习,开始真正接触网络爬虫。
关于Python的入门基础可以参考MOOC上的课程,简单易懂,也有相应的练习和资料,在此不加赘述。
我用的IDE是PyCharm,然后下载了Anaconda作为管理环境资源的工具。
一、什么是网络爬虫
网络爬虫又称网络蜘蛛、网络机器人等,可以自动化浏览网络中的信息,也可以按照我们制定的规则进行,这些规则被叫做网络爬虫算法。不同的人学习爬虫,可能目的有所不同,一般有以下几个原因:
- 学习爬虫,可以订制一个搜索引擎,并且可以对搜索引擎的数据采集工作原理进行更深层次的理解;
- 大数据时代,要进行数据分析,首先要有数据源,学习爬虫可以让我们获取更多的数据源,并且按照我们的目的进行采集和去掉许多无关数据;
- 从就业的角度来说,爬虫工程师目前来说属于紧缺人才,深层次地掌握这门技术,对就业来说比较有利。
网络爬虫由控制节点、爬虫节点和资源库构成。网络爬虫中可以有多个控制节点,每个控制节点下可以有多个爬虫节点,控制节点之间可以相互通信,同时控制节点和其下的各爬虫节点之间也可以进行互相通信。
Urllib库
该库是Python提供的一个用于操作URL的模块,在Python3.X中Urllib2合并到了Urllib中,这是与Python2.X不同的地方。
- urllib.request模块是用来打开和读取URLs的;
- urllib.error模块包含一些有urllib.request产生的错误,可以使用try进行捕捉处理;
- urllib.parse模块包含了一些解析URLs的方法;
- urllib.robotparser模块用来解析robots.txt文本文件.它提供了一个单独的RobotFileParser类,通过该类提供的can_fetch()方法测试爬虫是否可以下载一个页面。
下面讲解如何使用Urllib快速爬取一个网页。
二、写一个简单的爬虫
import urllib.request
file = urllib.request.urlopen("https://baike.baidu.com/item/Python/407313")
data = file.read()
print(data.decode("utf-8"))
filehandle = open("E://1.html","wb")
filehandle.write(data)
filehandle.close()首先导入需要用到的模块,并通过urlopen打开并爬取一个网页,并赋给file,此时我们还需要将对应的网页内容读取出来,并通过decode("utf-8")将读取到的内容按照utf-8进行解码并输出,即可得到该网页的源码。
然后新建一个文件1.html,并将网页的源代码写入该文件,这样执行代码后,打开该文件就可得到该网页的效果(图片可能无法加载)。
三、通过网络参数获取在线翻译的结果
下面通过一个在线翻译的例子,讲解利用urlopen的data参数获取翻译的结果。
首先打开有道翻译,右键点击审查元素,输入love,并点击翻译。
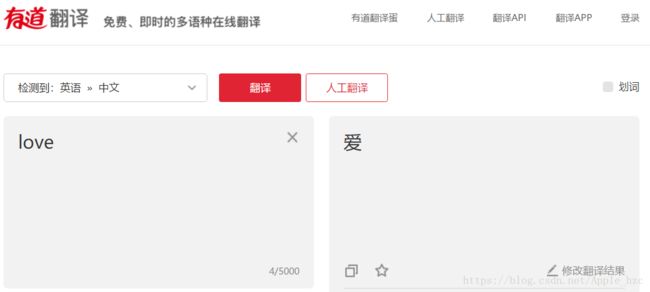
点击审查元素中的Network,当点击翻译时,会出现下列data,这时点击第二行的"translate..."。

然后在Headers这一栏中第一排会看到Request URL这一项。


下面编写py代码,其中的url是上图中对应的Request URL,data字典用来存储上图中对应的Form Data,运行程序得到翻译的结果。其中JSON是一种轻量级的数据交换格式,我们需要从爬取到的网页中找到JSON格式的数据,这里面保存着我们想要的翻译结果,再将得到的JSON格式的翻译结果进行解析。
注:要将Request URL中translate后的_o删掉,作为下面代码中的url,否则会报错。
import urllib.request
import json
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
data = {}
data["i"] = "love"
data["from"] = "AUTO"
data["to"] = "AUTO"
data["smartresult"] = "dict"
data["client"] = "fanyideskweb"
data["salt"] = "1536044858137"
data["sign"] = "10493a951066ea2626891f7d6342aaee"
data["doctype"] = "json"
data["version"] = "2.1"
data["keyfrom"] = "fanyi.web"
data["action"] = "FY_BY_REALTIME"
#使用urlencode方法转换标准格式
result = urllib.parse.urlencode(data).encode(("utf-8"))
#传递Request对象和转换完格式的数据
response = urllib.request.urlopen(url,result)
#读取信息并解码
html = response.read().decode("utf-8")
#使用JSON
translate_result = json.loads(html)
translate_result = translate_result["translateResult"][0][0]["tgt"]
print("翻译的结果是:%s" % translate_result)四、关于urllib.error异常
urllib.error可以接收有urllib.request产生的异常。urllib.error有两个方法,URLError和HTTPError。
其中URLError是OSError的一个子类,HTTPError是URLError的一个子类,服务器上HTTP的响应会返回一个状态码,根据这个HTTP状态码,我们可以知道我们的访问是否成功。例如常见的200状态码,表示请求成功,再比如常见的404错误等。
一般来说,产生URLError的原因有如下几种可能:
- 连接不上服务器
- 远程URL不存在
- 无网络
- 触发了HTTPError
由此可见,如果想用HTTPError和URLError一起捕获异常,那么需要将HTTPError放在URLError的前面,因为HTTPError是URLError的一个子类。如果URLError放在前面,出现HTTP异常会先响应URLError,这样HTTPError就捕获不到错误信息了。
可以使用hasattr函数判断URLError含有的属性,如果含有reason属性表明是URLError,如果含有code属性表明是HTTPError。
import urllib.request
import urllib.error
url = "http://www.lovemn.com"
req = urllib.request.Request(url)
try:
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))
except urllib.error.URLError as e:
if(hasattr(e,"code")):
print("HTTPError")
print(e.code)
elif(hasattr(e,"reason")):
print("URLError")
print(e.reason)运行代码后得到结果:

五、浏览器的模拟-Headers属性
有时候,我们爬取一些网页的时候,会出现403错误,因为这些网页为了防止别人恶意采集信息所以进行了一些反爬虫的设置。
那么如果我们想进一步爬取这些信息,可以设置一些Headers信息,模拟成浏览器去访问这些网站,模拟成浏览器可以设置User-Agent信息。
任意打开一个网页,比如MOOC,右键审查元素,切换到Network标签页:
这时点击任意一个按钮,让网页发生一个动作,这时我们可以观察到下方的窗口出现了一些数据:

单击一下第一行即可出现如下界面,往下拖动,可以找到如下内容,这一串信息就是我们即将模拟浏览器所需要的信息:
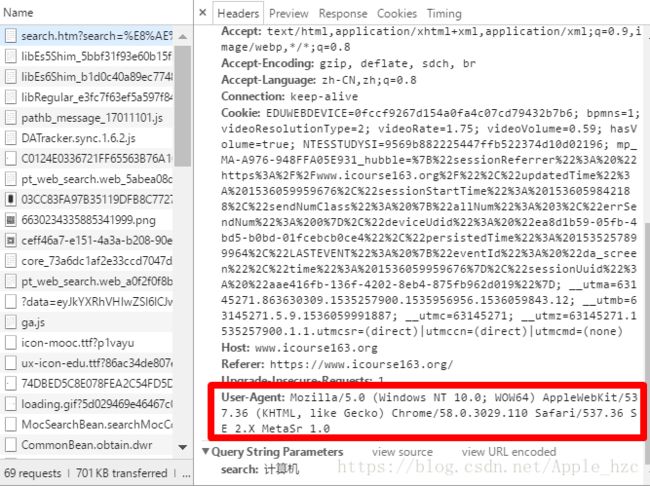
接下来,讲解两种让爬虫模拟成浏览器访问网页的设置方法。
一、使用build_opener()修改报头
import urllib.request
url = "https://blog.csdn.net/qysh123/article/details/44564943"
#定义一个变量headers存储User-Agent信息
headers = ("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0")
opener = urllib.request.build_opener()
opener.addheaders = [headers]
data = opener.open(url).read()
print(data.decode("utf-8"))二、使用add_header()添加报头
import urllib.request
url = "https://blog.csdn.net/qysh123/article/details/44564943"
req = urllib.request.Request(url)
#添加报头信息
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0")
data = urllib.request.urlopen(req).read()
print(data.decode("utf-8"))我们可以发现,这两种方法都是通过设置报头中的User-Agent字段信息来将对应的访问行为模仿成浏览器访问,避免了403错误。方法1中使用的是addheaders()方法,方法2中使用的是add_header()方法,注意末尾有无s以及有无下划线的区别。