数据结构基础19:字典树
前言:字典树(Trie)可以保存一些字符串->值的对应关系。基本上,它跟 Java 的 HashMap 功能相同,都是 key-value 映射,只不过 Trie 的 key 只能是字符串。Trie 的强大之处就在于它的时间复杂度。它的插入和查询时间复杂度都为 O(k) ,其中 k 为 key 的长度,与 Trie 中保存了多少个元素无关。Hash 表号称是 O(1) 的,但在计算 hash 的时候就肯定会是 O(k) ,而且还有碰撞之类的问题。
一、字典树有什么用?
1.以最节约空间的方式存储大量字符串,且存好后是有序的
2.快速查询某字符串s在字典树中是否已存在,甚至出现过几次
二、字典树的定义
Trie树,又称单词查找树或前缀树,是一颗多叉树,属于哈希树的变种。典型应用是用于统计,排序和保存大量的字符串,所以经常被搜索引擎系统用于文本词频统计。
下面我们有and,as,at,cn,com这些关键词,其trie树如下:
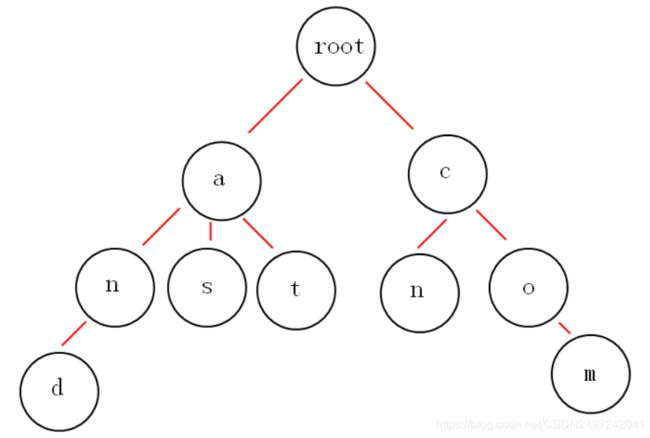
与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。、一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
1、基本性质
- 根节点不包含字符,除根节点意外每个节点只包含一个字符。
- 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符串不相同。
2、优缺点
①优点
处理大量字符串,利用字符串的公共前缀在存储时节约存储空间,并在查询时最大限度的减少无谓的字符串比较,查询效率比哈希树高。
②缺点
虽然不同单词共享前缀,但其实Trie树是一个以空间换时间的算法。其每一个字符都可能包含至多字符集大小数目的指针。
3、常见应用
串的快速检索
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。
在这道题中,我们可以用数组枚举,用哈希,用字典树,先把熟词建一棵树,然后读入文章进行比较,这种方法效率是比较高的。
“串”排序
给定N个互不相同的仅由一个单词构成的英文名,让你将他们按字典顺序从小到大输出
用字典树进行排序,采用数组的方式创建字典树,这棵树的每个结点的所有儿子很显然地按照其字母大小排序。对这棵树进行先序遍历即可。
最长公共前缀
对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的结点的公共祖先个数,于是,问题就转化为当时公共祖先问题。
三、字典树的构建
Trie树的创建要考虑的是父节点如何保存孩子节点,主要有链表和数组两种方式:
(1)使用节点数组,因为是英文字符,可以用Node[26]来保存孩子节点(如果是数字我们可以用Node[10]),这种方式最快,但是并不是所有节点都会有很多孩子,所以这种方式浪费的空间太多
(2)用一个链表根据需要动态添加节点。这样我们就可以省下不小的空间,但是缺点是搜索的时候需要遍历这个链表,增加了时间复杂度。
给出一组单词,inn, int, at, age, adv, ant, 我们可以得到下面的Trie:

可以看出:
每条边对应一个字母。
每个节点对应一项前缀。叶节点对应最长前缀,即单词本身。
单词inn与单词int有共同的前缀“in”, 因此他们共享左边的一条分支,root->i->in。同理,ate, age, adv, 和ant共享前缀"a",所以他们共享从根节点到节点"a"的边。
(1)查询操作
查询操作非常简单。比如要查找int,顺着路径i -> in -> int就找到了。
(2)如何构建
Trie树的构建也很简单,无非是逐一把每则单词的每个字母插入Trie。
插入前先看前缀是否存在。如果存在,就共享,否则创建对应的节点和边。
比如要插入单词add,就有下面几步:
考察前缀"a",发现边a已经存在。于是顺着边a走到节点a。
考察剩下的字符串"dd"的前缀"d",发现从节点a出发,已经有边d存在。于是顺着边d走到节点ad
考察最后一个字符"d",这下从节点ad出发没有边d了,于是创建节点ad的子节点add,并把边ad->add标记为d。
四、Java实现字典树
/*
* 字典树
*/
public class Trie18
{
private int SIZE=26;
private TrieNode root;//字典树的根
Trie18() //初始化字典树
{
root=new TrieNode();
}
private class TrieNode //字典树节点
{
private int num;//有多少单词通过这个节点,即由根至该节点组成的字符串模式出现的次数
private TrieNode[] son;//所有的儿子节点
private boolean isEnd;//是不是最后一个节点
private char val;//节点的值
TrieNode()
{
num=1;
son=new TrieNode[SIZE];
isEnd=false;
}
}
//1、建立字典树
public void insert(String str) //在字典树中插入一个单词
{
if(str==null||str.length()==0)
{
return;
}
TrieNode node=root;
char[]letters=str.toCharArray();
for(int i=0,len=str.length(); i