【代码】Fluent Python
14.1 Sentence类第1版:单词序列
从 Python 3.4 开始,检查对象 x 能否迭代,最准确的方法是:调用 iter(x) 函数,如果不可迭代,再处理 TypeError 异常。这比使用 isinstance(x, abc.Iterable) 更准确,因为 iter(x) 函数会考虑到遗留的__getitem__方法,而 abc.Iterable 类则不考虑。
>>> class F():
def __iter__(self):
pass
>>> f = F()
>>> iter(f)
Traceback (most recent call last):
File "", line 1, in
iter(f)
TypeError: iter() returned non-iterator of type 'NoneType'
>>> isinstance(f, collections.abc.Iterable)
True
>>> class G():
def __getitem__(self):
pass
>>> g = G()
>>> iter(g)
>>> isinstance(g, collections.abc.Iterable)
False
14.3 典型的迭代器
构建可迭代的对象和迭代器时经常会出现错误,原因是混淆了二者。要知道,可迭代的对象有个__iter__方法,每次都实例化一个新的迭代器;而迭代器要实现__next__方法,返回单个元素,此外还要实现__iter__方法,返回迭代器本身。因此,迭代器可以迭代,但是可迭代的对象不是迭代器。
14.4 生成器函数
可迭代对象中:
__iter__方法调用迭代器类的构造方法创建一个迭代器并将其返回:
def__iter__(self):
return SentenceIterator(self.words)
迭代器可以是生成器对象,每次调用__iter__方法都会自动创建,因为这里的__iter__方法是生成器函数:
def__iter__(self):
for word in self.words:
yield word
14.12 深入分析iter函数
内置函数 iter 的文档中有个实用的例子。这段代码逐行读取文件,直到遇到空行或者到达文件末尾为止:
with open('mydata.txt') as fp:
for line in iter(fp.readline, '\n'):
process_line(line)
用print(line)实测发现,必须要有至少一个整个空行,否则到达结尾也不会结束
14 杂谈
。。。。。。。
生成器与迭代器的语义对比
。。。。。。。
第三方面是概念。
根据《设计模式:可复用面向对象软件的基础》一书的定义,在典型的迭代器设计模式中,迭代器用于遍历集合,从中产出元素。迭代器可能相当复杂,例如,遍历树状数据结构。但是,不管典型的迭代器中有多少逻辑,都是从现有的数据源中读取值;而且,调用 next(it) 时,迭代器不能修改从数据源中读取的值,只能原封不动地产出值。
而生成器可能无需遍历集合就能生成值,例如 range 函数。即便依附了集合,生成器不仅能产出集合中的元素,还可能会产出派生自元素的其他值。enumerate 函数是很好的例子。根据迭代器设计模式的原始定义,enumerate 函数返回的生成器不是迭代器,因为创建的是生成器产出的元组。
15.2 上下文管理器和with块
with 语句的目的是简化 try/finally 模式。这种模式用于保证一段代码运行完毕后执行某项操作,即便那段代码由于异常、return 语句或 sys.exit() 调用而中止,也会执行指定的操作。finally 子句中的代码通常用于释放重要的资源,或者还原临时变更的状态。
上下文管理器协议包含__enter__和__exit__两个方法。with 语句开始运行时,会在上下文管理器对象上调用__enter__方法。with 语句运行结束后,会在上下文管理器对象上调用__exit__方法,以此扮演 finally 子句的角色。
15.3 contextlib模块中的实用工具
。。。。。。。。
@contextmanager
这个装饰器把简单的生成器函数变成上下文管理器,这样就不用创建类去实现管理器协议了。
。。。。。。。。
显然,在这些实用工具中,使用最广泛的是 @contextmanager 装饰器,因此要格外留心。这个装饰器也有迷惑人的一面,因为它与迭代无关,却要使用 yield 语句。由此可以引出协程,这是下一章的主题。
Python魔法模块之contextlib
使用 @contextmanager 装饰器时,要把 yield 语句放在 try/finally 语句中(或者放在 with 语句中),这是无法避免的,因为我们永远不知道上下文管理器的用户会在 with 块中做什么。
16.2 用作协程的生成器的基本行为
最先调用 next(my_coro) 函数这一步通常称为“预激”(prime)协程(即,让协程向前执行到第一个 yield 表达式,准备好作为活跃的协程使用)。
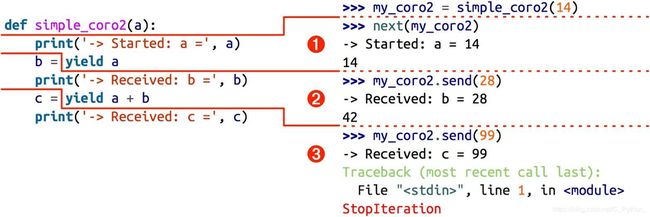
图 16-1:执行 simple_coro2 协程的 3 个阶段(注意,各个阶段都在 yield 表达式中结束,而且下一个阶段都从那一行代码开始,然后再把 yield 表达式的值赋给变量)
16.4 预激协程的装饰器
from functools import wraps
def coroutine(func):
""" 装饰器,向前执行第一个yield表达式"""
@wraps(func)
def primer(*args, **kwargs):
gen = func(*args, **kwargs)
next(gen)
return gen
return primer
####################测试用例#############################
@coroutine
def ave():
total = 0.0
count = 0
ave = None
while 1:
term = yield ave
total += term
count += 1
ave = total/count
if __name__ == "__main__":
aa = ave()
#next(aa) 不在需要
print aa.send(1)
print aa.send(2)
print aa.send(3)
=========================================================
(python2.7) C:\Users\ASUS\Desktop>ipython main2.py
1.0
1.5
2.0
作者:你呀呀呀
链接:https://www.jianshu.com/p/813ca3081d3f
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
使用 yield from 句法(参见 16.7 节)调用协程时,会自动预激,因此与示例 16-5 中的@coroutine 等装饰器不兼容。Python 3.4 标准库里的 asyncio.coroutine 装饰器(第18 章介绍)不会预激协程,因此能兼容 yield from 句法。
16.5 终止协程和异常处理
示例 16-7 暗示了终止协程的一种方式:发送某个哨符值,让协程退出。内置的 None 和Ellipsis 等常量经常用作哨符值。Ellipsis 的优点是,数据流中不太常有这个值。我还见过有人把 StopIteration 类(类本身,而不是实例,也不抛出)作为哨符值;也就是说,是像这样使用的:my_coro.send(StopIteration)。
从 Python 2.5 开始,客户代码可以在生成器对象上调用两个方法,显式地把异常发给协程。这两个方法是 throw 和 close。
16.7 使用yield from
第 14 章说过,yield from 可用于简化 for 循环中的 yield 表达式。
在 Beazley 与 Jones 的《Python Cookbook(第 3 版)中文版》一书中,“4.14 扁平化处理嵌套型的序列”一节有个稍微复杂(不过更有用)的 yield from 示例
from collections import Iterable
def flattern(items, ignore_type=(str, bytes)):
for item in items:
if isinstance(item, Iterable) and not isinstance(item, ignore_type):
yield from flattern(item)
else:
yield item
items = [1,2,[3,4,[5,6],7],8]
for item in flattern(items):
print(item)
items = ['www','bai',['du','com']]
for item in flattern(items):
print(item)
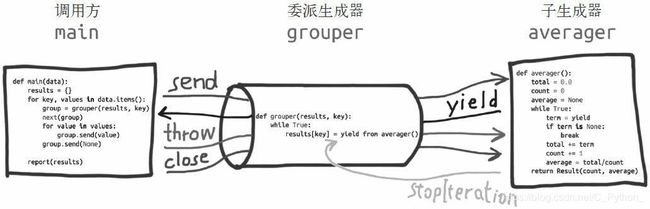
图 16-2:委派生成器在 yield from 表达式处暂停时,调用方可以直接把数据发给子生成器,子生成器再把产出的值发给调用方。子生成器返回之后,解释器会抛出StopIteration 异常,并把返回值附加到异常对象上,此时委派生成器会恢复
示例 16-17 展示了 yield from 结构最简单的用法,只有一个委派生成器和一个子生成器。因为委派生成器相当于管道,所以可以把任意数量个委派生成器连接在一起:一个委派生成器使用 yield from 调用一个子生成器,而那个子生成器本身也是委派生成器,使用 yield from 调用另一个子生成器,以此类推。最终,这个链条要以一个只使用 yield表达式的简单生成器结束;不过,也能以任何可迭代的对象结束,如示例 16-16 所示。
任何 yield from 链条都必须由客户驱动,在最外层委派生成器上调用 next(…) 函数或 .send(…) 方法。可以隐式调用,例如使用 for 循环。
16.10 本章小结
本章最后举了一个离散事件仿真示例,说明如何使用生成器代替线程和回调,实现并发。那个出租车仿真系统虽然简单,但是首次一窥了事件驱动型框架(如 Tornado 和asyncio)的运作方式:在单个线程中使用一个主循环驱动协程执行并发活动。使用协程做面向事件编程时,协程会不断把控制权让步给主循环,激活并向前运行其他协程,从而执行各个并发活动。这是一种协作式多任务:协程显式自主地把控制权让步给中央调度程序。而多线程实现的是抢占式多任务。调度程序可以在任何时刻暂停线程(即使在执行一个语句的过程中),把控制权让给其他线程。
17.1.1 依序下载的脚本
sys.stdout.flush()
win下不需要,ubuntu下需要刷新标准输出,才能实时显示
17.1.2 使用concurrent.futures模块下载
import requests
import re
import os
import time
from concurrent import futures
from tqdm import tqdm
# 最大线程数
MAX_TASKS = 10
def download_one(bn):
img = requests.get("http://imgsrc.baidu.com/forum/pic/item/" + bn) # 请求图片原图地址
fpic = open(os.path.join(r".\saito_asuka", bn), "wb") # 新建图片文件
for j in img.iter_content(100000):
fpic.write(j) # 写入文件
fpic.close() # 关闭文件
# bn:basename 图片名
return bn
def save_pic(pic_set):
pic_set = list(pic_set)
workers = min(MAX_TASKS, len(pic_set))
with futures.ThreadPoolExecutor(workers) as executor:
# 适于io密集型任务,如果是cpu密集型任务想绕开GIL:
# with futures.ProcessPoolExecutor() as executor:
# 其默认参数为cpu数量(s.cpu_count(),也是最大线程数)
res = executor.map(download_one, sorted(pic_set))
# 这里res为download_one返回值
# print(list(res))
return len(list(res))
def get_pic(web):
pic = re.compile(r"sign=.*?\.jpg.*?") # 正则表达式
elem = pic.findall(web.text) # findall查询得图片后半地址列表
# 图片名称的集合
pic_set = set()
for i in elem:
basename = i.split("/")[1] # 取得地址中的文件名
if basename not in pic_set:
pic_set.add(basename)
return pic_set
# 此方法监视进度,未被使用
def show(pic_set):
# return pic_set
return tqdm(pic_set)
def download_many(url):
web = requests.get(url)
pic_set = get_pic(web)
return save_pic(pic_set)
def main():
time0 = time.time()
url = "http://tieba.baidu.com/p/5367293540"
count = download_many(url)
cost = time.time() - time0
print("{} pics done in {:.2f}s".format(count, cost))
if __name__ == '__main__':
main()
17.1.3 期物在哪里
executor.submit 方法和 futures.as_completed 函数
executor.map 调用换成两个 for 循环:一个用于创建并排定期物,另一个用于获取期物的结果。
def save_pic(pic_ls):
# 这里发现需要排序,把pic_set改成了pic_ls
pic_ls = pic_ls[:5]
with futures.ThreadPoolExecutor(max_workers=6) as executor:
to_do = []
for bn in sorted(pic_ls):
# submit排定执行时间,返回期物,
# 将表示待执行的操作存入期物列表to_do
future = executor.submit(download_one, bn)
to_do.append(future)
msg = '计划中: {}:{}'
print(msg.format(bn, future))
results = []
for future in futures.as_completed(to_do):
# as_completed在期物运行结束后产出期物(该future不会阻塞),res获取期物结果(是被操作函数返回值吧)
res = future.result()
msg = '{}结果:{}'
print(msg.format(future, res))
results.append(res)
return len(results)
17.4 实验Executor.map方法
具体情况因人而异:对线程来说,你永远不知道某一时刻事件的具体排序;有可能在另一台设备中会看到loiter(1) 在 loiter(0) 结束之前开始,这是因为 sleep 函数总会释放 GIL。因此,即使休眠 0 秒, Python 也可能会切换到另一个线程。
移除GIL非常困难,让我们去购物吧!
至于GIL,不要认为它在那的存在就是静态的和未经分析过的。Antoine Pitrou 在Python 3.2中实现了一个新的GIL,并且带着一些积极的结果。这是自1992年以来,GIL的一次最主要改变。这个改变非常巨大,很难在这里解释清楚,但是从一个更高层次的角度来说,旧的GIL通过对Python指令进行计数来确定何时放弃GIL。这样做的结果就是,单条Python指令将会包含大量的工作,即它们并没有被1:1的翻译成机器指令。在新的GIL实现中,用一个固定的超时时间来指示当前的线程以放弃这个锁。在当前线程保持这个锁,且当第二个线程请求这个锁的时候,当前线程就会在5ms后被强制释放掉这个锁(这就是说,当前线程每5ms就要检查其是否需要释放这个锁)。当任务是可行的时候,这会使得线程间的切换更加可预测。
executor.submit 和 futures.as_completed 这个组合比 executor.map 更灵活,因为 submit 方法能处理不同的可调用对象和参数,而 executor.map 只能处理参数不同的同一个可调用对象。此外,传给 futures.as_completed 函数的期物集合可以来自多个 Executor 实例,例如一些由 ThreadPoolExecutor 实例创建,另一些由 ProcessPoolExecutor 实例创建。