集群服务器环境下安装Caffe深度学习库(GPU)
关于配置Berkeley Caffe深度学习库的帖子网上已经有很多了, 不过大多数都是基于本地机进行配置.
我个人的一部分研究涉及到用深度学习对数字病理学图片进行分类(基于像素),因为图像量很大所以需要用到集群计算并利用GPU加速.个人觉得自己在算法和理论上并不算深入,在具体应用上大概有一年左右经历.
集群环境下配置和本地机配置过程最大区别在于大多数情况下我们没有根权限, 因此需要把Caffe和依赖库安装在用户目录下.
我在两个不同的集群环境中进行过Caffe的配置和运行, 资源管理软件分别是Grid Engine(CWRU)和SLURM(Buffalo), 二者在对于运行Caffe上大同小异,在具体环境和资源申请时候会有略微不同.
CWRU和Buffalo的集群服务器都支持模块管理,因此方便动态按需求加载和卸载资源. Caffe对于依赖库的版本要求比较苛刻,因此使用模块管理可以更好的控制依赖库版本和对应的环境变量.
首先,我们需要查一下Caffe依赖的库,具体可以从官网查到,大致概括一下:
1.CUDA肯定是必须的, 如果用GPU.推荐7.0版本,6.5也行,5.5以下不确定是否会出问题
2.BLAS(线性代数和矢量操作库), 可以是ATLAS,MKS,OpenBLAS中的任意一个
3.Boost,大于1.55版本
4.OpenCVS,大于2.4版本(3.0可以)
5.protobuf, glog, gflags 等等
6.hdf5, leveldb, snappy, lmdb
7.如果需要python和matlab接口,需要分别编译其各自接口:
1)Python Caffe, python 2.7 或者 python 3.3+, numpy版本大于1.7, 含有boost的boost.python
2)Matlab, MATLAB还有mex编译器
8.cuDNN (如果GPU支持cuDNN并且想启用cuDNN加速)
现在,我们先检测一下集群服务器上有哪些库已经安装我们只需要加载即可,使用命令,module avial
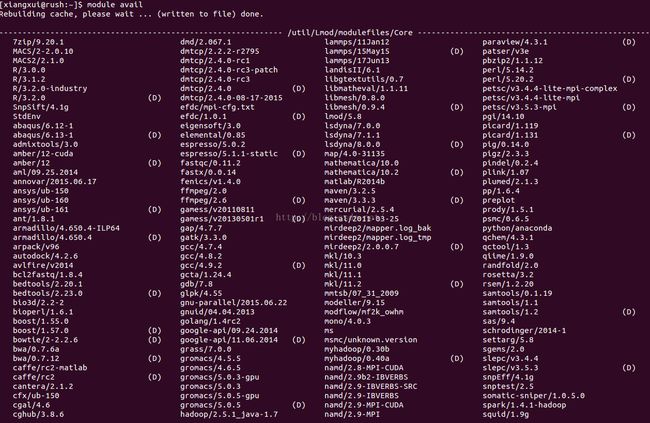
可以发现其实很多库已经存在,只需加载即可. 为了运行Caffe时方便,我的做法是写一个脚本,把所有要加载的库都写在里面,用Caffe之前运行一下即可. 具体做法是, 我在这个路径下简历一个文件~/.usr/local/share/modulefiles/caffe_dependencies
- module load cmake
- module load hdf/5-1.8.11
- module load cuda/6.5
- module load intel-mpi/4.1.3
- module load vtk/6.0.0
- module load python/anaconda
- module load opencv/2.4.10
- module load boost/1.57.0
- module load mkl/11.2
- module load google-api/11.06.2014
- git clone https://github.com/google/leveldb.git
- git clone https://github.com/schuhschuh/gflags.git
- git clone https://github.com/google/protobuf.git
- git clone https://github.com/google/glog.git
- git clone https://gitorious.org/mdb/mdb.git
- git clone https://github.com/google/snappy.git
2.如果有autogen.sh,先运行一下
3.如果用make编译,则会有configure的脚本文件, 可以选择文件编译安装的位置,我的习惯是放在~/.usr/local下. 因此,
. ./configure --prefix=~/.usr/local/
mkdir build, cd build, cmake -DCMAKE_INSTALL_PREFIX= /nfs /01 /cwr0463 /.usr /local / ..
set root /nfs /01 /cwr0463 /.usr /local /prepend-path PATH $root /binprepend-path CPLUS_INCLUDE_PATH $root /includeprepend-path C_INCLUDE_PATH $root /includeprepend-path LD_LIBRARY_PATH $root /libprepend-path LIBRARY_PATH $root /libprepend-path MANPATH $root /share
好了,现在对于在自己目录下编译的库设置完环境后,我们在打开刚才的caffe_dependencies文本, 把1.0也加入进去.最终结果看上去类似这样
[xiangxui@rush:~/.usr/local/share/modulefiles]$ cat caffe_dependencies
module use -a /user/xiangxui/.usr/local/share/modulefiles
module load depends_xxw/1.0
module load cmake
module load hdf/5-1.8.11
module load cuda/6.5
module load intel-mpi/4.1.3
module load vtk/6.0.0
module load python/anaconda
module load opencv/2.4.10
module load boost/1.57.0
module load mkl/11.2
module load google-api/11.06.2014
至此依赖库及环境的设置就完成了. 接下来就开始编译Caffe的过程
首先, 依旧git Caffe源码
git clone https://github.com/BVLC/caffe.git
根据官方建议,
cp Makefile.config.example Makefile.config
根据自己实际情况更改一些路径和配置:
我个人使用cuDNN因此
因为使用mkl, 所以< # USE_CUDNN := 1
改为
> USE_CUDNN := 1
< BLAS := atlas
< # Custom (MKL/ATLAS/OpenBLAS) include and lib directories.
改为
> BLAS := mkl
> # Custom (MKL/ATLAS/OpenBLAS) include and lib directories
接下来继续改变路径到自己安装的路径, 需要注意的是PYTHON可能会有比较多的版本,每个版本的包含文件可能存在几个不同的位置,需要都进行包含