python下载漫画
下载漫画的脚本
身为漫画迷,一直想直接将漫画下载到电脑上看,于是就有这个python脚本。
系统:Ubuntu 14.04
python版本:2.7.6
用到的python库有:
- os (操作系统接口的标准库,用于创建文件)
- sys (标准库,获取命令行参数)
- string (字符串操作的标准库,用于将字符串中的数值转换为整型)
- getopt (对命令行参数进行处理)
- lxml (当中的html,相当于Jsoup,这里用于快速查找网页的元素)
- requests (通过URL获取网页)
- urllib2 (作用和requests差不多)
其中非标准库getopt、lxml、requests、urlslibs可以通过pip安装。
思路:
- 选择漫画网站进行解析,显示漫画章节
- 选择漫画章节,找到本章漫画图片的路径
- 按漫画图片的路径下载到本地保存
要求:了解Python、XPath、URL、html即可。
- 下载漫画的脚本
- 步骤
- 解析漫画章节列表
- 解析获得漫画图片
- 下载漫画图片到本地
- 查找漫画
- 显示
- 显示搜索结果
- 显示漫画目录
- 显示下载结果
- 总结
- 步骤
步骤
1.解析漫画章节列表
以纳米漫画网下的盘龙为例(以前叫国漫吧,很多国漫都能看,我挺喜欢的,不过chromium却显示这网站有毒*=*,注意)
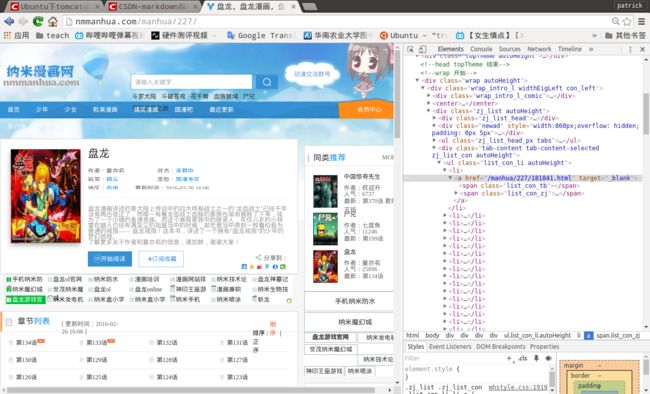
为了方便下载,需要将漫画的每个章节标题和相应的链接记录下来。
查看章节列表的源码,发现章节是用无序列表关联的,查看其中一个章节的XPath,/html/body/div[2]/div[1]/div[2]/div[3]/ul/li[1]/a。但是每个章节的xpath都是不一样的,我们不可能一个一个地计算,这时就要找到它们的共同点。
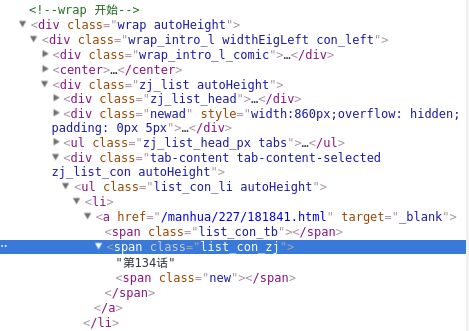
很明显,可以用含class的xpath代替,xpath可以理解为网页元素的标识、位置。
这里用//div[@class=”tab-content tab-content-selected zj_list_con autoHeight”]/ul[@class=”list_con_li autoHeight”]/li代替每个章节,
那么章节标题就是
**//div[@class="tab-content tab-content-selected zj_list_con autoHeight"]/ul[@class="list_con_li autoHeight"]/li/a/span[@class="list_con_zj"]/text()**,
章节的链接就是**//div[@class="tab-content tab-content-selected zj_list_con autoHeight"]/ul[@class="list_con_li autoHeight"]/li/a[@href]/@href**
代码如下
#获取漫画的目录
def getIndexLinkFromDirectory(comic_directory_url):
page = requests.get(comic_directory_url)
tree = html.fromstring(page.content)
comic_title = tree.xpath('//div[@class="comic_deCon"]/h3[1]/a/text()')
chapter_link = tree.xpath('//div[@class="tab-content tab-content-selected zj_list_con autoHeight"]/ul[@class="list_con_li autoHeight"]/li/a[@href]/@href')
chapter_title = tree.xpath('//div[@class="tab-content tab-content-selected zj_list_con autoHeight"]/ul[@class="list_con_li autoHeight"]/li/a/span[@class="list_con_zj"]/text()')
#print "Cretae directory"
return comic_title[0],chapter_link,chapter_title主要就是以漫画章节目录网页的URL作为参数,并通过requests获得这一网页page,然后用html生成tree,在tree中可以通过xpath方便地获取网页元素,即章节标题和链接,以及漫画名称,并返回。
注意,python可以在一个函数中返回多个值,所以这里依次返回漫画名称、章节标题数组和链接数组,其中后两者有对应关系(同一下标的标题和链接相关)。
2.解析获得漫画图片
以134话来看源码

漫画图片的地址是http://cartoon.kdm8.com/?u=/manhuatuku/12757/manhua_12_20160225_2016022508144669474.jpg,我们要做的就是获取这章节所有图片的地址。为了流畅快速,一般网站可能会将这些图片地址保存到客户端的浏览器中,也就是JS里面。这时再看回网页源码,发现在某段的JS代码里就有,不过就是有点晕。

本页的图片地址和下一页的图片地址都在,很明显这就是我们要的这一章的图片地址了,这就方便下载。分析这段JS,可以发现在”page_url”的键值对里面,而且以”|”分隔每个图片地址。
代码如下
#获取一章节漫画的链接
def getPictureUrls(data):
page_url = "\"page_url\":\""
if page_url in data:
index = data.find(page_url)
page_url = data[(index+len(page_url)):data.find("\"",index+len(page_url))]
return page_url.split("||")
主要是将requests获得的网页内容作为参数data传入,然后提取图片地址,即”page_url”:”…..”这个键值对,然后在用”|”划分为地址数组并返回。
3.下载漫画图片到本地
通过上一步获取图片地址后,就可以通过其读取图片数据并保存到本地上。为了方便,依次将图片下载保存到以章节标题命名的文件夹中。
先尝试直接下载是否被网站filter,有些网站会过滤掉这种外部请求

明显能访问,所以可行。
代码如下
#下载漫画到本地目录中
def downloadPicture(pic_urls,base_directory):
total = len(pic_urls)
print "开始下载..."
for i in xrange(total):
print "Downloading %d in %d" % (i+1, total)
url = pic_urls[i].replace("\\","").replace("|","")
f = urllib2.urlopen(url)
data = f.read()
with open(base_directory+"/%03d.jpg" % i,"wb") as pic:
pic.write(data)
print "下载完成"以图片地址数组为参数pic_urls,本地目录名(图片保存)为参数base_directory,依次通过urllibs下载到base_directory中,并用格式化字符串按顺序重命名。
注意,因为linux系统下文件路径以”/“为分隔符,所以如果要在windows下适用,文件名(”/%03d.jpg”)也要相应修改。
4.查找漫画
一开始总不能直接输入漫画的网址,因为不知道的,所以就需要实现查找功能,即输入漫画名后在网站上进行查找。
看回这网站的查找界面,尝试查找盘龙

可见网址的形式为http://nmmanhua.com/search/?key=盘龙,那说明只要将搜索的漫画名组成http://nmmanhua.com/search/?key=漫画名再处理即可。
而搜索结果列表如图
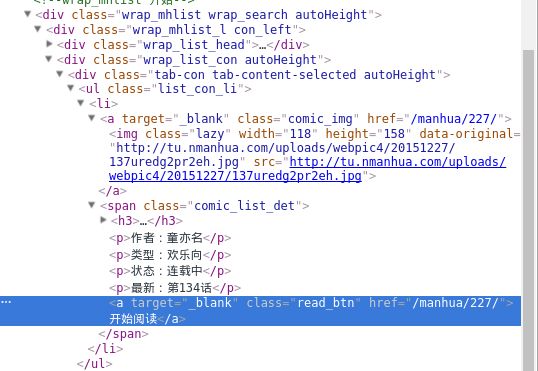
同理,漫画的XPath是//span[@class=”comic_list_det”]/,那么标题就为//span[@class=”comic_list_det”]/h3/a/text(),链接就是//span[@class=”comic_list_det”]/a/@href。
代码如下
#根据漫画名查找,返回漫画名和相应的链接
def searching(content):
print "查找中....."
search_url = "http://nmmanhua.com/search/?key="+content #调用漫画网站进行搜索
page = requests.get(search_url)
tree = html.fromstring(page.content)
comic_title = tree.xpath('//span[@class="comic_list_det"]/h3/a/text()') #显示漫画名
comic_link = tree.xpath('//span[@class="comic_list_det"]/a/@href') #记录漫画的链接
print "查找完成"
return comic_title,comic_link和第一步很相似,只是这里返回漫画标题数组和链接数组。
显示
主要时通过上述处理后,获得相应的相关数组,按顺序显示。
输入相应的下标即为选择下载。
显示搜索结果
搜索盘龙
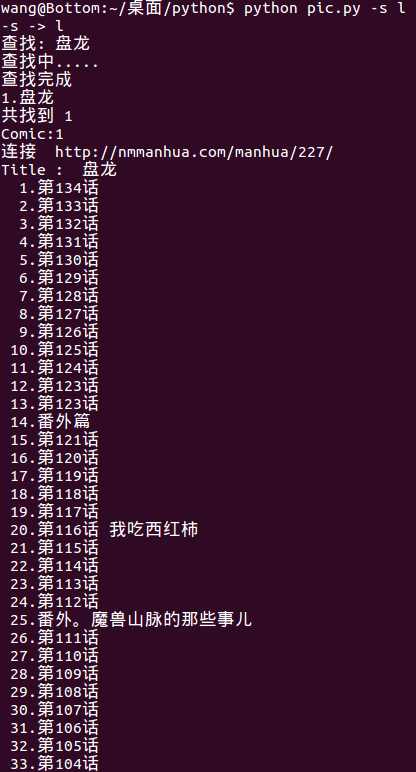
代码如下
#显示漫画搜索的结果
def showSearchResult(comic_title,comic_link):
for i in xrange(len(comic_title)):
print "%d.%-15s" % (i+1,comic_title[i])
print "共找到 %d" % len(comic_title)引用searching(content)后,格式化输出。
显示漫画目录
代码如下
#显示漫画目录
def showDirectory(comic_title,chapter_link,chapter_title):
print "Title : ",comic_title
for i in xrange(len(chapter_title)):
print "%3d.%-15s" % (i+1,chapter_title[i])引用getIndexLinkFromDirectory(comic_directory_url)后,格式化输出。
下载第133话
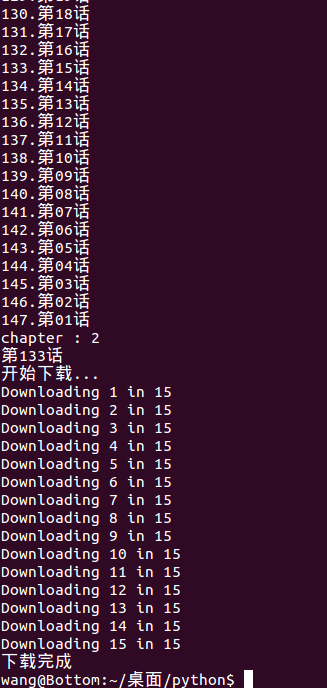
显示下载结果
下载自动保存到本地
下载后看漫画
总结
- 只是CUI,没有GUI。这个脚本为命令行界面,目前只是对纳米漫画网进行查找、下载,不过道理一样。
- 用getopt处理参数,可以添加更多如
-d 网址的options,不过这里只处理了-h和-s。 - 如果想同时用作图片查看的话,可以使用python出名的PIL实现。
- 要跨平台的话,就要修改文件名中的路径分隔符才行。
Future
1. 想尝试用Java实现,因为Jsoup和lxml的html是一样的道理,只是将xpath改用jquery表达式而已。
2. 写一个Android端的app,也用于下载漫画。现在困在怎样异步获取漫画章节等信息并更新。
完整代码:http://download.csdn.net/detail/cceking/9586938