【初学】C# 爬虫小实战-批量导出学院新闻信息
【初学】爬虫小实战-批量导出学院新闻信息
中秋过后,闲来无事,忽然间对大数据的数据挖掘感兴趣,然后就开始研究研究网络爬虫的原理,经过一晚上的折腾,勉强爬了学院的新闻列表,程序还有很大的改进空间,特发此文,让学爬虫的同学借鉴和交流,大家共同进步(●’◡’●)
源码传送门地址:点我传送
上效果图:
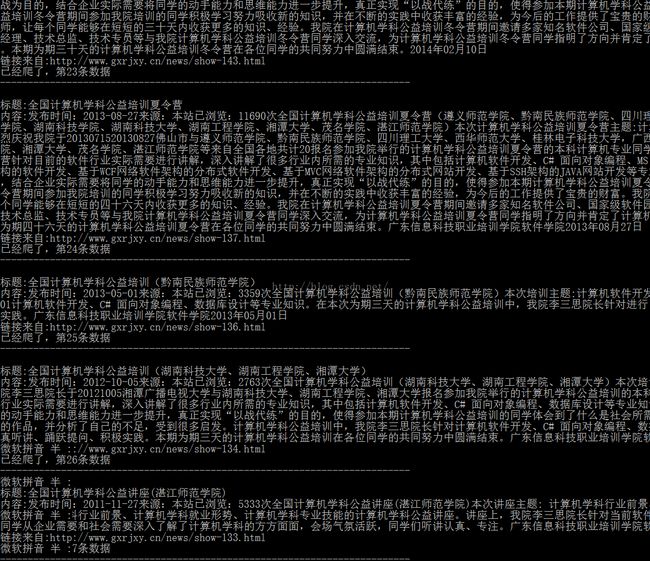
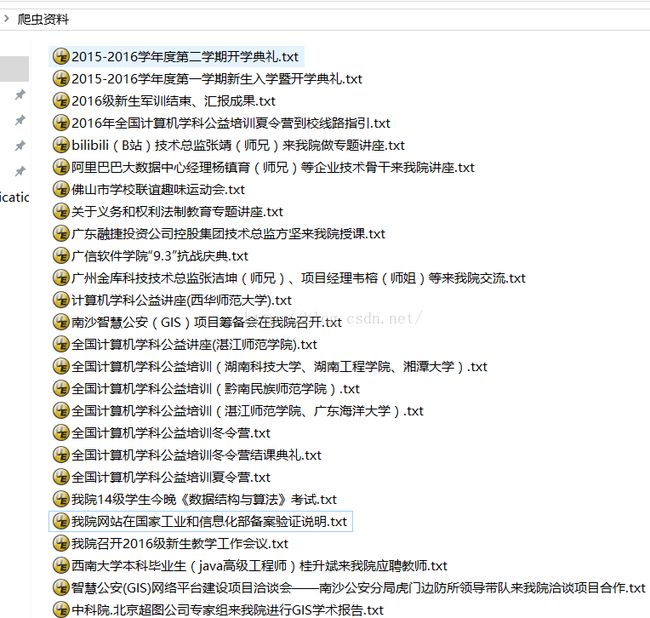
主要实现方法:
///
///获取URL网站源码
///
///
///
private string GetHttpWebRequest(string url)
{
HttpWebResponse result;
string strHTML = string.Empty;
try
{
Uri uri =newUri(url);
WebRequest webReq =WebRequest.Create(uri);
WebResponse webRes =webReq.GetResponse();
HttpWebRequest myReq = (HttpWebRequest)webReq;
myReq.UserAgent = "User-Agent:Mozilla/4.0(compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.0.3705";
myReq.Accept = "*/*";
myReq.KeepAlive = true;
myReq.Headers.Add("Accept-Language","zh-cn,en-us;q=0.5");
result = (HttpWebResponse)myReq.GetResponse();
Stream receviceStream =result.GetResponseStream();
StreamReader readerOfStream =newStreamReader(receviceStream,System.Text.Encoding.GetEncoding("utf-8"));
strHTML =readerOfStream.ReadToEnd();
readerOfStream.Close();
receviceStream.Close();
result.Close();
}
catch
{
try {
Uri uri =newUri(url);
WebRequest webReq =WebRequest.Create(uri);
HttpWebRequest myReq = (HttpWebRequest)webReq;
myReq.UserAgent = "User-Agent:Mozilla/4.0(compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.0.3705";
myReq.Accept = "*/*";
myReq.KeepAlive = true;
myReq.Headers.Add("Accept-Language","zh-cn,en-us;q=0.5");
//result =(HttpWebResponse)myReq.GetResponse();
try
{
result = (HttpWebResponse)myReq.GetResponse();
}
catch (WebException ex)
{
result = (HttpWebResponse)ex.Response;
}
Stream receviceStream =result.GetResponseStream();
StreamReader readerOfStream =newStreamReader(receviceStream,System.Text.Encoding.GetEncoding("gb2312"));
strHTML =readerOfStream.ReadToEnd();
readerOfStream.Close();
receviceStream.Close();
result.Close();
}
catch
{
}
}
return strHTML;
}
///
///提取HTML代码中的网址
///
///
///
private static List<string> GetHyperLinks(string htmlCode,string url)
{
ArrayList al =newArrayList();
bool IsGenxin = false;
StringBuilder weburlSB =newStringBuilder();//SQL
StringBuilder linkSb =newStringBuilder();//展示数据
List<string> Weburllistzx =newList<string>();//新增
List<string> Weburllist =newList<string>();//旧的
string ProductionContent =htmlCode;
Regex reg =newRegex(@"http(s)?://([\w-]+\.)+[\w-]+/?");
string wangzhanyuming =reg.Match(url, 0).Value;
MatchCollection mc =Regex.Matches(ProductionContent.Replace("href=\"/","href=\"" +wangzhanyuming).Replace("href='/","href='" +wangzhanyuming).Replace("href=/","href=" +wangzhanyuming).Replace("href=\"./","href=\"" + wangzhanyuming), @"<[aA][^>]*href=[^>]*>", RegexOptions.Singleline);
int Index = 1;
foreach (Match min mc)
{
MatchCollection mc1 =Regex.Matches(m.Value,@"[a-zA-z]+://[^\s]*", RegexOptions.Singleline);
if (mc1.Count > 0)
{
foreach (Match m1in mc1)
{
string linkurlstr =string.Empty;
linkurlstr =m1.Value.Replace("\"","").Replace("'","").Replace(">","").Replace(";","");
weburlSB.Append("$-$");
weburlSB.Append(linkurlstr);
weburlSB.Append("$_$");
if(!Weburllist.Contains(linkurlstr) &&!Weburllistzx.Contains(linkurlstr))
{
IsGenxin = true;
Weburllistzx.Add(linkurlstr);
linkSb.AppendFormat("{0}
", linkurlstr);
}
}
}
else
{
if (m.Value.IndexOf("javascript") == -1)
{
string amstr =string.Empty;
stringwangzhanxiangduilujin =string.Empty;
wangzhanxiangduilujin =url.Substring(0, url.LastIndexOf("/") + 1);
amstr =m.Value.Replace("href=\"","href=\"" +wangzhanxiangduilujin).Replace("href='","href='" +wangzhanxiangduilujin);
MatchCollection mc11 =Regex.Matches(amstr,@"[a-zA-z]+://[^\s]*", RegexOptions.Singleline);
foreach (Match m1in mc11)
{
string linkurlstr =string.Empty;
linkurlstr =m1.Value.Replace("\"","").Replace("'","").Replace(">","").Replace(";","");
weburlSB.Append("$-$");
weburlSB.Append(linkurlstr);
weburlSB.Append("$_$");
if(!Weburllist.Contains(linkurlstr) &&!Weburllistzx.Contains(linkurlstr))
{
IsGenxin = true;
Weburllistzx.Add(linkurlstr);
linkSb.AppendFormat("{0}
", linkurlstr);
}
}
}
}
Index++;
}
return Weburllistzx;
}
///
/// //导出到txt文件
///
///
///
public static void WriteTxt(string Context,string fileName)
{
if (!File.Exists(@"C:\Users\chenluliang\Desktop\爬虫资料\"+ fileName +".txt"))
{
FileStream fs1 =newFileStream(@"C:\Users\chenluliang\Desktop\爬虫资料\"+ fileName +".txt",FileMode.Create, FileAccess.Write);//创建写入文件
StreamWriter sw =newStreamWriter(fs1);
sw.WriteLine(Context);//开始写入值
sw.Close();
fs1.Close();
}
}
///
/// //把网址写入xml文件
///
///
///
public static void WriteToXml(string strURL,List<string> alHyperLinks)
{
Program o =newProgram();
XmlTextWriter writer =newXmlTextWriter(@"D:\HyperLinks.xml",Encoding.UTF8);
writer.Formatting = Formatting.Indented;
writer.WriteStartDocument(false);
writer.WriteDocType("HyperLinks",null,"urls.dtd",null);
writer.WriteComment("提取自" + strURL +"的超链接");
writer.WriteStartElement("HyperLinks");
writer.WriteStartElement("HyperLinks",null);
writer.WriteAttributeString("DateTime",DateTime.Now.ToString());
foreach (string strin alHyperLinks)
{
string title =GetDomain(str);
string body = str;
stringStrContent=GetContent(o.GetHttpWebRequest(str));
if (StrContent!="") {
string strTitle=GetTitle(o.GetHttpWebRequest(str));
if (strTitle !="")
{
try {WriteTxt(StrContent, strTitle); }catch {
Console.WriteLine("写入文件失败!");
}
Console.WriteLine("标题:" + strTitle);
Console.WriteLine("内容:" + StrContent);
Number++;
Console.WriteLine("链接来自:" + body +"");
Console.WriteLine("已经爬了,第" + Number +"条数据");
Console.WriteLine("--------------------------------------------------------------------------" +"\n");
}
}
writer.WriteElementString(title, null, body);
}
writer.WriteEndElement();
writer.WriteEndElement();
writer.Flush();
writer.Close();
}
///
///获取网址的域名后缀
///
///
///
public static string GetDomain(string strURL)
{
string retVal;
string strRegex = @"(\.com/|\.net/|\.cn/|\.org/|\.gov/)";
Regex r = new Regex(strRegex, RegexOptions.IgnoreCase);
Match m =r.Match(strURL);
retVal = m.ToString();
strRegex = @"\.|/$";
retVal = Regex.Replace(retVal,strRegex,"").ToString();
if (retVal == "")
retVal = "other";
return retVal;
}
///
///获取标题
///
///
///
public static string GetTitle(string html)
{
string titleFilter = @"[\s\S]*?
";
string h1Filter = @"
string clearFilter = @"<.*?>";
string title = "";
Match match =Regex.Match(html,titleFilter,RegexOptions.IgnoreCase);
if (match.Success)
{
title = Regex.Replace(match.Groups[0].Value,clearFilter,"");
}
// 正文的标题一般在h1中,比title中的标题更干净
match = Regex.Match(html,h1Filter,RegexOptions.IgnoreCase);
if (match.Success)
{
string h1 = Regex.Replace(match.Groups[0].Value,clearFilter, "");
if (!String.IsNullOrEmpty(h1)&& title.StartsWith(h1))
{
title = h1;
}
}
return title;
}
///
///获取内容
///
///
///
public static string GetContent(string html)
{
string cukc = "";
string titleFilter = @" [\s\S]*?
string h1Filter = @"
string clearFilter = @"<.*?>";
string Ctitle = "";
Match match=null;
while (true)
{
try
{
html = Regex.Replace(html," ","");
match = Regex.Match(html,titleFilter,RegexOptions.IgnoreCase);
if (match.Success)
{
Ctitle = Regex.Replace(match.Groups[0].Value,clearFilter, "");
}
// 正文的标题一般在h1中,比title中的标题更干净
match = Regex.Match(html,h1Filter,RegexOptions.IgnoreCase);
if (match.Success)
{
string h1 =Regex.Replace(match.Groups[0].Value,clearFilter,"");
cukc += h1;
}
html =html.Replace(match.ToString(), "");//替换字符串,也可以是一个字符,但是需要用双
}
catch {
// Console.WriteLine("正文:"+ cukc);
// Console.WriteLine("--------------------------------------------------------------------------");
break;
}
}
return cukc;
}