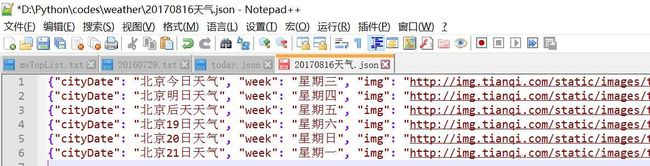
Scrapy实例1-爬取天气预报存储到Json
目标: 爬取天气网天气
目标链接: http://beijing.tianqi.com/
我们依据上篇文章http://blog.csdn.net/co_zy/article/details/77189416
建立一个工程和一个爬虫
> scrapy startproject weather
> > scrapy genspider BeijingSpider tianqi.com在本次爬虫项目案例中,需要修改,填空的只有4个文件,分别是items.py,settings.py,pipelines.py,BeijingSpider.py
(1)打开目标链接,审查元素
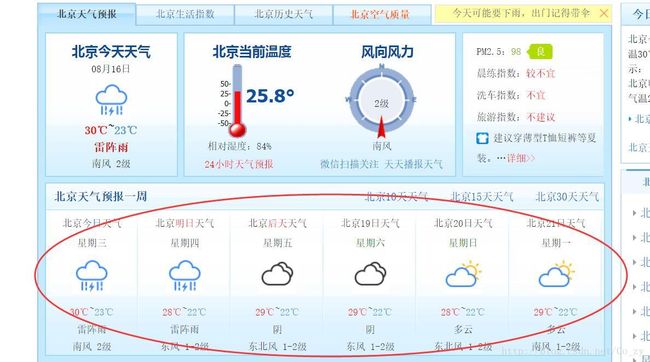
在这里,包含的信息有城市日期,星期,天气图标,温度,天气状况以及风向.至此,items.py文件已经呼之欲出
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class WeatherItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
cityDate = scrapy.Field()
week = scrapy.Field()
img = scrapy.Field()
temperature = scrapy.Field()
weather = scrapy.Field()
wind = scrapy.Field()
(2)编辑spider/文件夹下的BeijingSpider.py文件
# -*- coding: utf-8 -*-
import scrapy
from weather.items import WeatherItem
class WuhanspiderSpider(scrapy.Spider):
name = "BeijingSpider"
allowed_domains = ["tianqi.com"]
citys = ['beijing']
start_urls = []
for city in citys:
start_urls.append('http://' + city + '.tianqi.com/')
def parse(self, response):
subSelector = response.xpath('//div[@class="tqshow1"]')
items = []
for sub in subSelector:
item = WeatherItem()
cityDates = ''
for cityDate in sub.xpath('./h3//text()').extract():
cityDates += cityDate
item['cityDate'] = cityDates
item['week'] = sub.xpath('./p//text()').extract()[0]
item['img'] = sub.xpath('./ul/li[1]/img/@src').extract()[0]
temps = ''
for temp in sub.xpath('./ul/li[2]//text()').extract():
temps += temp
item['temperature'] = temps
item['weather'] = sub.xpath('./ul/li[3]//text()').extract()[0]
item['wind'] = sub.xpath('./ul/li[4]//text()').extract()[0]
items.append(item)
print("this"+items)
return items(3)修改pipelines.py,处理Spider的结果
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import time
import os.path
import requests
class WeatherPipeline(object):
def process_item(self, item, spider):
today = time.strftime('%Y%m%d',time.localtime())
filename = today + '.txt'
#打开一个文件用于追加
with open(filename,'wb+') as f:
f.write(item['cityDate'])
f.write(item['week'])
imgName = os.path.basename(item['img'])
f.write(imgName)
if os.path.exists(imgName):
pass
else:
with open(imgName,'wb') as f:
response = requests.get(item['img'])
f.write(response.read())
f.write(item['temperature'])
f.write(item['weather'])
f.write(item['wind'])
time.sleep(1)
return item(4)修改seetings.py,决定由那个文件来处理获取的数据
# -*- coding: utf-8 -*-
# Scrapy settings for weather project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'weather'
SPIDER_MODULES = ['weather.spiders']
NEWSPIDER_MODULE = 'weather.spiders'
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
'weather.pipelines.WeatherPipeline': 1,
}
只要稍微更改一下即可
ITEM_PIPELINES = {
'weather.pipelines.WeatherPipeline': 1,
}(5)最后,回到weather项目下,执行命令
scrapy crawl BeijingSpider将pipelines.py改为以下,将能保存为json
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import time
import os.path
import requests
import json
import codecs
class WeatherPipeline(object):
def process_item(self, item, spider):
today = time.strftime('%Y%m%d',time.localtime())
fileName = today + '天气.json'
with codecs.open(fileName,'a',encoding='utf-8') as fp:
line = json.dumps(dict(item),ensure_ascii=False) + '\n'
fp.write(line)
return item