基于HDP版本的YDB安装部署
第三章 YDB依赖环境准备
一、硬件环境
硬件如何搭配,能做到比较高的性价比,不存在短板。合理的硬件搭配,对系统的稳定性也很关键。
1.CPU不是核数越高越好,性价比才是关键。
经常遇到很多的企业级客户,他们机器配置非常高,CPU有128 VCore,256G内存,但是只挂载了1块8T的SATA硬盘,千兆网卡。
这样的机器配置比较适合计算密集型的业务,但是如果是IO密集型的业务的话,就会发现磁盘成为瓶颈,会发现磁盘利用率100%,网络利用率100%,但是CPU只用了不到5%。存在巨大的资源浪费。
这种问题在Hadoop系统中尤为突出,如果是这样的配置的话,很可能一个MapReduce程序就会导致全部的磁盘与网络都是使用率100%,这样所有的心跳都发送不出来,而本身Hadoop又没有很好的网络限速机制,就会导致DataNode与TaskManager陆续的因为心跳超时而挂掉。
2.SAS、SATA与SSD 磁盘的选择与对比
IOPS (Input/Output Per Second)即每秒的输入输出量(或读写次数),是衡量磁盘性能的主要指标之一。IOPS是指单位时间内系统能处理的I/O请求数量,I/O请求通常为读或写数据操作请求。对于随机读写频繁的应用,如OLTP(Online Transaction Processing),IOPS是关键衡量指标。
吞吐量(Throughput),指单位时间内可以成功传输的数据数量。对于大量顺序读写的应用,如VOD(Video On Demand),则更关注吞吐量指标。
一般SSD的IOPS是普通磁盘的千倍以上,但是吞吐量只是普通磁盘的2倍左右。所以如果我们的业务是顺序读写偏多的则建议选用普通SAS盘(如存储形业务,以及Hive的文本数据分析),但是如果我们的业务是随机读写偏多,那么选择SSD 更划算(如采用列存储的系统,以及YDB的索引系统)
如下图所示,普通磁盘的IOPS与SSD磁盘的性能相差悬殊,特别是企业级SSD磁盘,能相差千倍以上。


吞吐量:连续读写速度,性能提升在2倍左右。

3.SSD的颗粒请不要选择TLC
TLC的寿命太短,虽然便宜,但是用不了几个月就基本报废,一般个人电脑使用。不适合企业级使用,性价比较好的建议选用MLC颗粒。
SSD颗粒目前主要分三种:SLC、MLC和TLC
SLC=Single-LevelCell,即1bit/cell,速度快寿命长,价格超贵(约MLC3倍以上的价格),约10万次擦写寿命
MLC=Multi-LevelCell,即2bit/cell,速度一般寿命一般,价格一般,约3000---10000次擦写寿命
TLC=Trinary-LevelCell,即3bit/cell,也有Flash厂家叫8LC,速度相对慢寿命相对短,价格便宜,约500次擦写寿命,目前还没有厂家能做到1000次擦写。
简单地说SLC的性能最优,价格超高。一般用作企业级或高端发烧友。MLC性能够用,价格适中为消费级SSD应用主流,TLC综合性能最低,价格最便宜。但可以通过高性能主控、主控算法来弥补、提高TLC闪存的性能。
4.延云YDB建议的硬件配置
一、延云YDB最低配置
1.内存:32G
2.磁盘:
离线模式:至少2块独立的物理硬盘分别用于HDFS数据盘、系统盘。
实时模式:至少3块独立的物理磁盘分别用于Kafka数据盘,、HDFS数据盘、系统盘
3.CPU:至少8线程(1颗,4核,8线程)
二、如下场景,延云将不再提供安装技术支持
1.低于最低配置要求的用户。
2.32位系统的用户:这类系统最大只有4G内存。
三、延云YDB高性能配置 (毫秒响应)
1.机器内存:128G
2.磁盘:企业级SSD,600~800G *12个磁盘
3.CPU:32线程(2颗,16核,32线程)
4.万兆网卡
三、延云YDB常规配置 (秒级响应)
1.机器内存:128G
2.磁盘:2T*12的磁盘
3.CPU:24线程(2颗,12核,24线程)
4.千兆网卡
二、磁盘如何挂载?
1.逻辑卷的问题
一般很多Linux的默认安装,会将磁盘直接以逻辑卷的方式挂载,逻辑卷的优点是后期的扩容以及调整磁盘非常的方便,看着比RAID好用多了,但是默认的逻辑卷配置方式是只有一块盘在工作 ,其他几块盘都闲着,发挥不出来多块盘的性能,也就是说如果在逻辑卷里面挂了10块盘,那么默认的逻辑卷的配置,只能发挥出一块盘的性能。所以对于YDB系统来说,大家不要使用逻辑卷。
2.关于RAID
有些客户比较担心数据丢失,将磁盘做了RAID10或者RAID5,其实这样是没有必要的,因为本身默认配置Hadoop是有三份副本的,并不怕磁盘损坏。RAID10与RAID5会导致磁盘容量只有原先的一半,由于需要双写,磁盘整体吞吐量降低了一倍。而且RAID5一旦损坏了一块磁盘,就需要通过奇偶校验还原数据,读的吞吐量直接降低到原先了五分之一,而且更换新盘后,通过校验要还原原先盘的数据的时候,经常会发生雪崩现象,IO瞬间增大,导致其他盘陆续的跟着挂掉。所以对于YDB系统来说,不推荐使用RAID 10或RAID5. 还有一些客户,会将所有的盘都做成一个完整的RAID0,RAID0的缺点就是一块盘损坏,整个系统就坏掉,但是RAID0确实会比单块磁盘速度好,所以如果能做raid0我更推荐2个盘组成一起做一个RAID0,而不是整体所有磁盘都做成一个RAID0.
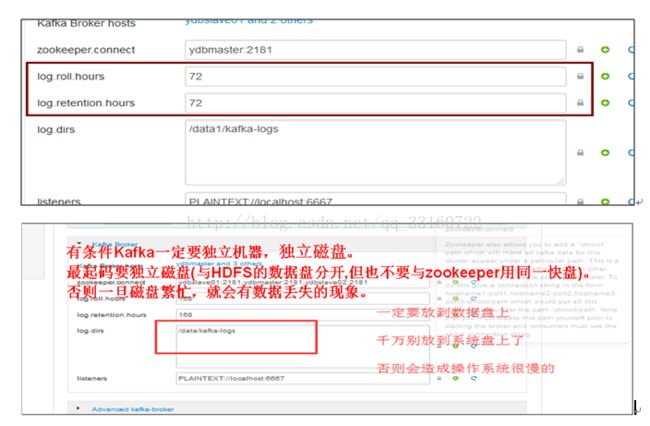
3.关于系统盘与数据盘
好多客户,在挂盘的时候,为了节省磁盘空间,更充分的利用资源,会将一个8T的物理磁盘划分成两个逻辑分区,一个逻辑分区作为系统盘,另一个逻辑分区作为数据盘。但是数据盘一般会比较繁忙的,但是由于他们底层都共用的是同一块物理磁盘,就会导致系统盘实际上也会特别繁忙,系统盘繁忙会导致整个系统会变的非常的慢,执行任何Linux命令都很慢,Socket连接建立也缓慢,很多系统会因此而超时断线,所以延云YDB建议操作系统要独立一块磁盘,数据盘不要与操作系统共用同一块盘,否则数据盘很慢的时候,运行在操作系统上的软件都跟着慢,ZooKeeper之类的服务也很容易挂掉。
另外还有一部分客户,可能因某种习惯,默认会给系统盘的跟目录预留的存储空间特别小,比如说只预留了10~30个G的空间,这样其实对大数据系统来说风险较大,以Ambari为例,他的log默认是记录在/var/log下的,这30G的空间会很快的被LOG记满,大家都知道一旦操作系统根目录满了意味着什么? 将是所有服务不可用,这样隐患太大了。所以延云建议系统跟目录尽量留大一点的磁盘空间,如200G,默认CentOS给分配50G空间也太小,如果Hadoop等日志没有及时清理掉,将来隐患较大
4.关于磁盘阵列与云
有相当一部分的客户使用云服务器,将机器虚拟化后确实节省了很多的资源,提高了硬件的利用率。目前的云服务器有相当一部分的解决方案是采用外挂存储的方式将磁盘统一的挂载到远程的一个磁盘阵列上去。这个时候磁盘阵列是单点,一旦发生断电或者磁盘阵列出现问题,因为Hadoop的三分副本都存储在这一个磁盘阵列上,一但丢失就会导致整个Hadoop集群不可用。如果有条件,我更建议做多个磁盘阵列而不是一个磁盘阵列单点,这样通过Hadoop的机架策略,可以将 Hadoop 的三份副本分别存储在不同的磁盘阵列上,NameNode以及SNameNode也分别存储在不同的磁盘阵列上,这样即使其中一个磁盘阵列出现了故障,我们的Hadoop也能够恢复服务,而且不丢数据。
另外由于虚拟化以后,一个真实的物理机上面可能会开多个虚拟机,如果这个物理机硬件发生损坏,这个物理机上的虚拟机也有异常,三个副本都存储在这台机器上的文件的数据会丢失,延云建议虚拟机厂商与Hadoop厂商协同,采用Hadoop机架技术,将位于同一物理机上的虚拟机标记在同一个机架上,以免造成数据丢失。
虚拟化后也存在系统盘与数据盘的问题,虽然在虚拟机里看到了系统盘与数据盘确实分离了,但是在物理机上有可能是在虚拟机A里面的系统盘,又作为了虚拟机B的数据盘,这样当虚拟机B的数据盘特别繁忙的时候,会造成虚拟机A的响应非常慢。针对这种情况延云YDB建议,将物理机的磁盘分类,一些磁盘专门用于挂系统盘,一些磁盘专门用于挂数据盘,不允许交叉使用,即不允许一个物理盘即挂数据盘又被挂成系统盘
5.将大磁盘空间的硬盘与小磁盘空间的硬盘混合挂载
可能是处于历史原因,部分客户的系统上出现了大小盘混合挂载的情况,比如说10块磁盘,有的是300G,有的是8T的磁盘,他们混搭在一起。但是目前的hadoop对这样的盘支持的并不友好,会出现300G的硬盘已经满了,8T的硬盘还没使用到原先的十分之一的情况,针对这种情况,延云建议数据盘尽量大小一样,别出现有的盘很大,有的盘很小的情况。那种300G的磁盘还是留作操作系统盘为好。
三、操作系统如何选择
1.延云推荐使用CentOS 6.6,6.5的系统(请不要使用CentOS7)
2.尽量选择安装英文语言环境,中文版Ambari有时会有问题,。
3.安装桌面版,请别安装最简版。
4.配置系统的yum源,如果部署Ambari会用到。
开源世界确实好,选择很多,但是意味着也坑很多。
对于YDB来说,是不挑操作系统版本的,只要您的系统能安装上Hadoop,那么YDB一般都能运行起来。甚至有些同学还在MAC上调试YDB。但是如果您是要运行在生产系统上,操作系统的选择就尤为重要了。
CentOS7笔者在其中一个客户下踩了一个巨坑,一个内核的BUG导致系统不断重启,所以对比较新的内核版本还是比较畏惧,所以笔者不是特别推荐大家使用比较新的系统,建议大家选用经过较多生产系统上验证过的稳定版本。如果非要推荐一个版本,那么延云推荐使用Centos 6.6的系统,因为延云的日常开发与测试均在这个版本上进行。
CentOS7我们当时踩的坑叫Transparent Huge Pages (THP)的BUG,在负载高的时候会造成机器的反复重启,并且从HDP官方也证实了这个BUG,http://www.cloudera.com/documentation/enterprise/latest/topics/cdh_admin_performance.html,但是我们按照上面的方法进行设置后,机器不重启了,但是依然发生偶尔断网的情况。
四、操作系统设置
1.Ulimit配置
操作系统默认只能打开1024个文件,打开的文件超过这个数发现程序会有“too many open files”的错误,1024对于大数据系统来说显然是不够的,如果不设置,基本上整个大数据系统是“不可用的”,根本不能用于生产环境。
配置方法如下:
echo "* soft nofile 128000" >> /etc/security/limits.conf
echo "* hard nofile 128000" >> /etc/security/limits.conf
echo "* soft nproc 128000" >> /etc/security/limits.conf
echo "* hard nproc 128000" >> /etc/security/limits.conf
cat /etc/security/limits.conf
sed -i 's/1024/unlimited/' /etc/security/limits.d/90-nproc.conf
cat /etc/security/limits.d/90-nproc.conf
ulimit -SHn 128000
ulimit -SHu 128000
2.Swap的问题
在10~20年前一台服务器的内存非常有限,64m~128m,所以通过swap可以将磁盘的一部分空间用于内存。但是现今我们的服务器内存普遍达到了64G以上,内存已经不再那么稀缺,但是内存的读取速度与磁盘的读取相差倍数太大,如果我们某段程序使用的内存映射到了磁盘上,将会对程序的性能照成非常严重的影响,甚至导致整个服务的瘫痪。对于YDB系统来说,要求一定要禁止使用Swap.
禁用方法如下,让操作系统尽量不使用Swap:
echo "vm.swappiness=1" >> /etc/sysctl.conf
sysctl -p
sysctl -a|grep swappiness
3.网络配置优化
echo " net.core.somaxconn = 32768 " >> /etc/sysctl.conf
sysctl -p
sysctl -a|grep somaxconn
4.SSH无密码登录
安装 Hadoop与Ambari均需要无密码登录
设置方法请参考如下命令
ssh-keygen
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
ssh-copy-id root@ydbslave01
ssh-copy-id root@ydbslave02
…..
5.关闭防火墙
iptables -P INPUT ACCEPT
iptables -P FORWARD ACCEPT
iptables -P OUTPUT ACCEPT
chkconfig iptables off
/etc/init.d/iptables stop
service iptables stop
iptables -F
6.配置机器名,以及hosts域名解析
hostname ydbmaster
vi /etc/sysconfig/network
vi /etc/hosts
切记 hosts文件中 不要将localhost给注释掉,并且配置完毕后,执行下 hostname -f 看下 是否能识别出域名
7.setenforce与Umask配置
•setenforce
setenforce 0
sed -i 's/enabled=1/enabled=0/' /etc/yum/pluginconf.d/refresh-packagekit.conf
cat /etc/yum/pluginconf.d/refresh-packagekit.conf
•Umask
umask 0022
echo umask 0022 >> /etc/profile
8.检查/proc/sys/vm/overcommit_memory的配置值
如果为2,建议修改为0,否则有可能会出现,明明机器可用物理内存很多,但JVM确申请不了内存的情况。
9.语言环境配置
先修改机器的语言环境
#vi /etc/sysconfig/i18n
LANG="en_US.UTF-8"
SUPPORTED="zh_CN.GB18030:zh_CN:zh:en_US.UTF-8:en_US:en"
SYSFONT="latarcyrheb-sun16"
然后配置环境变量为utf8
echo "export LANG=en_US.UTF-8 " >> ~/.bashrc
source ~/.bashrc
export|grep LANG
10.配置时间同步
Hadoop,YDB等均要求机器时钟同步,否则机器时间相差较大,整个集群服务就会不正常,所以一定要配置。建议配置NTP服务。
集群时间必须同步,不然会有严重问题
参考资料如下:http://www.linuxidc.com/Linux/2009-02/18313.htm
11.JDK安装部署
YDB支持JDK1.7,JDK1.8,为了便于管理和使用,建议使用YDB随机提供的JDK1.8
建议统一安装到/opt/ydbsoftware路径下。
12.环境变量
请大家千万不要在公共的环境变量配置HIVE、Spark、LUCENE、HADOOP等环境变量,以免相互冲突。
13.请检查盘符,不要含有中文
尤其是Ambari,有些时候,使用U盘或移动硬盘复制软件,如果这个移动硬盘挂载点是中文路径,这时在安装Ambari的时候会出现问题,一定要注意这个问题。
14.检查磁盘空间,使用率不得超过90%
默认Yarn会为每台机器保留10%的空间,如果剩余空间较少,Yarn就会停掉这些机器上的进程,并出现Container released on a *lost* node错误。
15.关键日志,定时清理,以免时间久了磁盘满了
如可以编辑crontab -e 每小时,清理一次日志,尤其是hadoop日志,特别占磁盘空间
0 */1 * * * find /var/log/hadoop/hdfs -type f -mmin +1440 |grep -E "\.log\." |xargs rm -rf
第四章 基于HDP的YDB部署(推荐)
一、安装前的准备
请参考第三章的基本环境注意事项,准备基础环境,这个很重要
二、软件下载
1.请从HDP官方下载 HDP与HDP-UTILS
http://public-repo-1.hortonworks.com/HDP/centos6/2.x/updates/2.5.0.0/HDP-2.5.0.0-centos6-rpm.tar.gz
http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.21/repos/centos6/HDP-UTILS-1.1.0.21-centos6.tar.gz
http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.4.1.0/ambari-2.4.1.0-centos6.tar.gz
2.请准备好系统安装盘.iso文件或者系统yum源
配置示例
mkdir -p /opt/ydbsoftware/centosyum
mount -o loop /opt/ydbsoftware/CentOS-6.6-x86_64-bin-DVD1.iso /opt/ydbsoftware/centosyum
3.从http://url.cn/42R4CG8获取延云软件
1)下载延云YDB
2)延云YDB提供的Spark (注意不要使用HDP提供的spark)
3)JDK1.8

三、软件上传
1.JDK安装
将安装包中的JDK安装到/opt/ydbsoftware/jdk1.8.0_60
分发到每台机器上,且路径统一为
/opt/ydbsoftware/jdk1.8.0_60
2.选定一台机器安装YDB的机器,上传软件
将全部软件上传到/opt/ydbsoftware目录下,并解压,注意是/opt/ydbsoftware,千万别写错了,且不能随意更改路径。
3.配置HTTP服务(在解压后的目录执行)
cd /opt/ydbsoftware
nohup Python -m SimpleHTTPServer &
4.YUM源配置
1)备份旧的YUM源
cd /etc/yum.repos.d
mkdir -p bak
mv *.repo bak/
2)配置ambari源与本地系统源
每台机器都要配置
ambari.repo文件名不得更改
本地系统源很重要,一定要配置
配置示例如下
cat << EOF >/etc/yum.repos.d/ambari.repo
[centoslocal]
name=centoslocal
baseurl=http://ydbmaster:8000/centosyum
gpgcheck=0
[AMBARI]
name=AMBARI
baseurl=http://ydbmaster:8000/AMBARI-2.4.1.0/centos6/2.4.1.0-22
gpgcheck=0
[HDP]
name=HDP
baseurl=http://ydbmaster:8000/HDP/centos6
gpgcheck=0
[HDP-UTILS]
name=HDP-UTILS
baseurl=http://ydbmaster:8000/HDP-UTILS-1.1.0.21/repos/centos6
gpgcheck=0
EOF
5.安装与配置ambari-server(只需要在一台机器安装)
yum clean all
yum makecache
yum repolist
yum install ambari-server
6.设置ambari
ambari-server setup
中间除jdk单独指定外,都默认
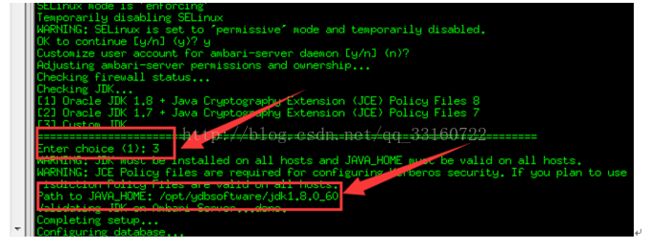
7.启动ambari-server
ambari-server start
然后就可以打开 http://xx.xx.xx.xx:8080 安装hadoop了 默认用户名与密码均为 admin
四、HDP页面设置
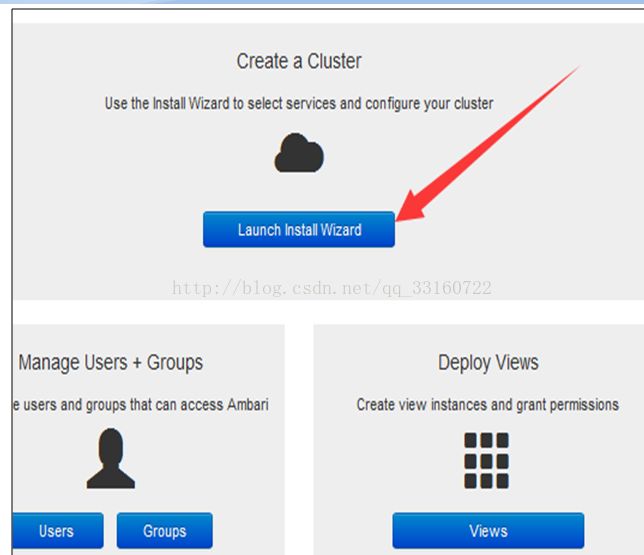
1.开始创建集群

2.配置HDP源
选择Hdp版本为hdp2.5
 、
、

3.部署的机器列表与登录私钥配置

4.部署Ambari-Agent
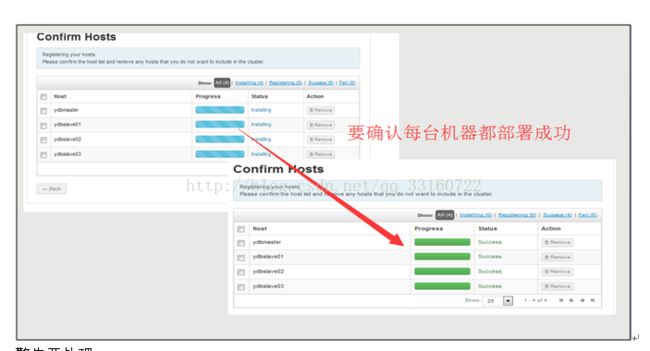
警告要处理

5.选择安装部署服务
切记,不需要选择Hive与Spark

6.服务分配


7.HDFS配置



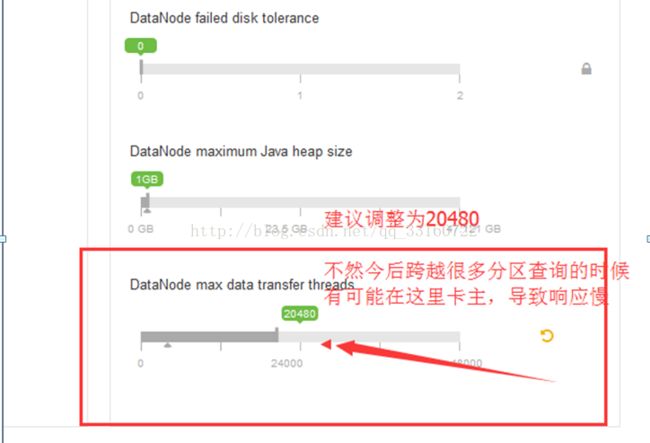

8.YARN配置

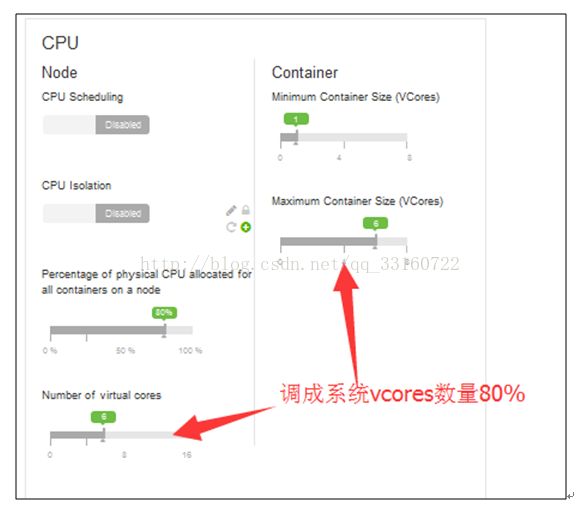



9.MapReduce配置

10.ZooKeeper配置

11.Ambari Metrics 配置

12.KAFKA配置


13.HDP部署完成


五、部署YDB
1.软件解压
解压开随机附带的spark1.6.3_hadoop2.7.3.tar.gz,里面是我们改过bug的Spark
解压开随机附带的ya100.1.x.x.zip,里面是YDB
解压后一定要放在/opt/ydbsoftware目录下
2.注意观察,如下三个目录是否存在
/opt/ydbsoftware/spark1.6.3_hadoop2.7.3
/opt/ydbsoftware/jdk1.8.0_60
/opt/ydbsoftware/ya100/bin
3.安装ydb
ln -s /opt/ydbsoftware/spark1.6.3_hadoop2.7.3 /opt/ydbsoftware/spark
cd /opt/ydbsoftware/ya100/bin
sh ./hdp_install.sh
4.YDB的ambari配置
1)添加服务



2)A组配置:基本配置

3)B组配置:环境路径配置

4)C组配置:存储相关路径配置

5)D组配置:Kafka相关配置

6)开始安装

7)安装完毕

8)服务检查
如果服务异常,可以看这个日志
tail -f /opt/ydbsoftware/ya100/logs/ya100.log 看是否有报错,当出现如下的日志,表示启动成功
打开yarn的8088页面,看启动的container数量以及内存的时候是否正确

UI监控

YDB的监控UI
1.可以查看每台机器的负载、处理数据、内存等情况。
2.可以了解每个表的运行情况,每个分区的数据条数,数据量大小。
默认启动的端口号为1210,如果在 ydb_site.yaml里配置了ydb.httpserver.port,则以配置的端口号为准。

了解延云ya100、ydb的用法、进行测试、生成演示demo
通过随机附带示例了解用法
打开ya100/example目录
第一: ydb_example.sql
包含了YDB的表的创建,ya100与YDB表的连接,查询的使用,数据的导入等
第二:如何通过kafka实时导入数据.txt
阐述了YDB如何通过Kafka实时的进行数据导入
第三:”演示demo搭建.txt”
如何快速的使用YDB生成延云官方提供的演示demo
基本的监控页面

YDB的Spark UI
在spark ui里可以看到 每个用户查询SQL的执行进度,响应时间等,也可以杀掉有异常的一些任务。
进入方法如下
1.首先打开您的yarn调度页面(默认端口是8088端口),并在里面找到ya100 on spark的任务,如下图所示

2.点击Application Master进入
如果点击后,发现域名解析不了,请在您机器本地配置好相关host,或者直接改成对应的IP。
3.点开后会看到如下的页面
