本系列文章为《Node.js Design Patterns Second Edition》的原文翻译和读书笔记,在GitHub连载更新,同步翻译版链接。
欢迎关注我的专栏,之后的博文将在专栏同步:
- Encounter的掘金专栏
- 知乎专栏 Encounter的编程思考
- segmentfault专栏 前端小站
Advanced Asynchronous Recipes
几乎所有我们迄今为止看到的设计模式都可以被认为是通用的,并且适用于应用程序的许多不同的领域。但是,有一套更具体的模式,专注于解决明确的问题。我们可以调用这些模式。就像现实生活中的烹饪一样,我们有一套明确的步骤来实现预期的结果。当然,这并不意味着我们不能用一些创意来定制设计模式,以配合我们的客人的口味,对于书写Node.js程序来说是必要的。在本章中,我们将提供一些常见的解决方案来解决我们在日常Node.js开发中遇到的一些具体问题。这些模式包括以下内容:
- 异步引入模块并初始化
- 在高并发的应用程序中使用批处理和缓存异步操作的性能优化
- 运行与
Node.js处理并发请求的能力相悖的阻塞事件循环的同步CPU绑定操作
异步引入模块并初始化
在Chapter2-Node.js Essential Patterns中,当我们讨论Node.js模块系统的基本属性时,我们提到了require()是同步的,并且module.exports也不能异步设置。
这是在核心模块和许多npm包中存在同步API的主要原因之一,是否同步加载会被作为一个option参数被提供,主要用于初始化任务,而不是替代异步API。
不幸的是,这并不总是可能的。同步API可能并不总是可用的,特别是对于在初始化阶段使用网络的组件,例如执行三次握手协议或在网络中检索配置参数。 许多数据库驱动程序和消息队列等中间件系统的客户端都是如此。
广泛适用的解决方案
我们举一个例子:一个名为db的模块,它将会连接到远程数据库。 只有在连接和与服务器的握手完成之后,db模块才能够接受请求。在这种情况下,我们通常有两种选择:
- 在开始使用之前确保模块已经初始化,否则则等待其初始化。每当我们想要在异步模块上调用一个操作时,都必须完成这个过程:
const db = require('aDb'); //The async module
module.exports = function findAll(type, callback) {
if (db.connected) { //is it initialized?
runFind();
} else {
db.once('connected', runFind);
}
function runFind() {
db.findAll(type, callback);
};
};- 使用依赖注入(
Dependency Injection)而不是直接引入异步模块。通过这样做,我们可以延迟一些模块的初始化,直到它们的异步依赖被完全初始化。 这种技术将管理模块初始化的复杂性转移到另一个组件,通常是它的父模块。 在下面的例子中,这个组件是app.js:
// 模块app.js
const db = require('aDb'); // aDb是一个异步模块
const findAllFactory = require('./findAll');
db.on('connected', function() {
const findAll = findAllFactory(db);
// 之后再执行异步操作
});
// 模块findAll.js
module.exports = db => {
//db 在这里被初始化
return function findAll(type, callback) {
db.findAll(type, callback);
}
}我们可以看出,如果所涉及的异步依赖的数量过多,第一种方案便不太适用了。
另外,使用DI有时也是不理想的,正如我们在Chapter7-Wiring Modules中看到的那样。在大型项目中,它可能很快变得过于复杂,尤其对于手动完成并使用异步初始化模块的情况下。如果我们使用一个设计用于支持异步初始化模块的DI容器,这些问题将会得到缓解。
但是,我们将会看到,还有第三种方案可以让我们轻松地将模块从其依赖关系的初始化状态中分离出来。
预初始化队列
将模块与依赖项的初始化状态分离的简单模式涉及到使用队列和命令模式。这个想法是保存一个模块在尚未初始化的时候接收到的所有操作,然后在所有初始化步骤完成后立即执行这些操作。
实现一个异步初始化的模块
为了演示这个简单而有效的技术,我们来构建一个应用程序。首先创建一个名为asyncModule.js的异步初始化模块:
const asyncModule = module.exports;
asyncModule.initialized = false;
asyncModule.initialize = callback => {
setTimeout(() => {
asyncModule.initialized = true;
callback();
}, 10000);
};
asyncModule.tellMeSomething = callback => {
process.nextTick(() => {
if(!asyncModule.initialized) {
return callback(
new Error('I don\'t have anything to say right now')
);
}
callback(null, 'Current time is: ' + new Date());
});
};在上面的代码中,asyncModule展现了一个异步初始化模块的设计模式。 它有一个initialize()方法,在10秒的延迟后,将初始化的flag变量设置为true,并通知它的回调调用(10秒对于真实应用程序来说是很长的一段时间了,但是对于具有互斥条件的应用来说可能会显得力不从心)。
另一个方法tellMeSomething()返回当前的时间,但是如果模块还没有初始化,它抛出产生一个异常。
下一步是根据我们刚刚创建的服务创建另一个模块。 我们设计一个简单的HTTP请求处理程序,在一个名为routes.js的文件中实现:
const asyncModule = require('./asyncModule');
module.exports.say = (req, res) => {
asyncModule.tellMeSomething((err, something) => {
if(err) {
res.writeHead(500);
return res.end('Error:' + err.message);
}
res.writeHead(200);
res.end('I say: ' + something);
});
};在handler中调用asyncModule的tellMeSomething()方法,然后将其结果写入HTTP响应中。 正如我们所看到的那样,我们没有对asyncModule的初始化状态进行任何检查,这可能会导致问题。
现在,创建app.js模块,使用核心http模块创建一个非常基本的HTTP服务器:
const http = require('http');
const routes = require('./routes');
const asyncModule = require('./asyncModule');
asyncModule.initialize(() => {
console.log('Async module initialized');
});
http.createServer((req, res) => {
if (req.method === 'GET' && req.url === '/say') {
return routes.say(req, res);
}
res.writeHead(404);
res.end('Not found');
}).listen(8000, () => console.log('Started'));上述模块是我们应用程序的入口点,它所做的只是触发asyncModule的初始化并创建一个HTTP服务器,它使用我们以前创建的handler(routes.say())来对网络请求作出相应。
我们现在可以像往常一样通过执行app.js模块来尝试启动我们的服务器。
在服务器启动后,我们可以尝试使用浏览器访问URL:http://localhost:8000/并查看从asyncModule返回的内容。
和预期的一样,如果我们在服务器启动后立即发送请求,结果将是一个错误,如下所示:
Error:I don't have anything to say right now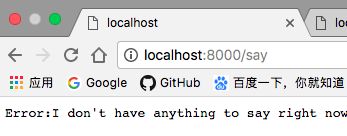
显然,在异步模块加载好了之后:
这意味着asyncModule尚未初始化,但我们仍尝试使用它,则会抛出一个错误。
根据异步初始化模块的实现细节,幸运的情况是我们可能会收到一个错误,乃至丢失重要的信息,崩溃整个应用程序。 总的来说,我们刚刚描述的情况总是必须要避免的。
大多数时候,可能并不会出现上述问题,毕竟初始化一般来说很快,以至于在实践中,它永远不会发生。 然而,对于设计用于自动调节的高负载应用和云服务器,情况就完全不同了。
用预初始化队列包装模块
为了维护服务器的健壮性,我们现在要通过使用我们在本节开头描述的模式来进行异步模块加载。我们将在asyncModule尚未初始化的这段时间内对所有调用的操作推入一个预初始化队列,然后在异步模块加载好后处理它们时立即刷新队列。这就是状态模式的一个很好的应用!我们将需要两个状态,一个在模块尚未初始化的时候将所有操作排队,另一个在初始化完成时将每个方法简单地委托给原始的asyncModule模块。
通常,我们没有机会修改异步模块的代码;所以,为了添加我们的排队层,我们需要围绕原始的asyncModule模块创建一个代理。
接下来创建一个名为asyncModuleWrapper.js的新文件,让我们依照每个步骤逐个构建它。我们需要做的第一件事是创建一个代理,并将原始异步模块的操作委托给这个代理:
const asyncModule = require('./asyncModule');
const asyncModuleWrapper = module.exports;
asyncModuleWrapper.initialized = false;
asyncModuleWrapper.initialize = () => {
activeState.initialize.apply(activeState, arguments);
};
asyncModuleWrapper.tellMeSomething = () => {
activeState.tellMeSomething.apply(activeState, arguments);
};在前面的代码中,asyncModuleWrapper将其每个方法简单地委托给activeState。 让我们来看看这两个状态是什么样子
从notInitializedState开始,notInitializedState是指还没初始化的状态:
// 当模块没有被初始化时的状态
let pending = [];
let notInitializedState = {
initialize: function(callback) {
asyncModule.initialize(function() {
asyncModuleWrapper.initalized = true;
activeState = initializedState;
pending.forEach(function(req) {
asyncModule[req.method].apply(null, req.args);
});
pending = [];
callback();
});
},
tellMeSomething: function(callback) {
return pending.push({
method: 'tellMeSomething',
args: arguments
});
}
};当initialize()方法被调用时,我们触发初始化asyncModule模块,提供一个回调函数作为参数。 这使我们的asyncModuleWrapper知道什么时候原始模块被初始化,在初始化后执行预初始化队列的操作,之后清空预初始化队列,再调用作为参数的回调函数,以下为具体步骤:
- 把
initializedState赋值给activeState,表示预初始化已经完成了。 - 执行先前存储在待处理队列中的所有命令。
- 调用原始回调。
由于此时的模块尚未初始化,此状态的tellMeSomething()方法仅创建一个新的Command对象,并将其添加到预初始化队列中。
此时,当原始的asyncModule模块尚未初始化时,代理应该已经清楚,我们的代理将简单地把所有接收到的请求防到预初始化队列中。 然后,当我们被通知初始化完成时,我们执行所有预初始化队列的操作,然后将内部状态切换到initializedState。来看这个代理模块最后的定义:
let initializedState = asyncModule;不出意外,initializedState对象只是对原始的asyncModule的引用!事实上,初始化完成后,我们可以安全地将任何请求直接发送到原始模块。
最后,设定异步模块还没加载好的的状态,即notInitializedState
let activeState = notInitializedState;我们现在可以尝试再次启动我们的测试服务器,但首先,我们不要忘记用我们新的asyncModuleWrapper对象替换原始的asyncModule模块的引用; 这必须在app.js和routes.js模块中完成。
这样做之后,如果我们试图再次向服务器发送一个请求,我们会看到在asyncModule模块尚未初始化的时候,请求不会失败; 相反,他们会挂起,直到初始化完成,然后才会被实际执行。我们当然可以肯定,比起之前,容错率变得更高了。
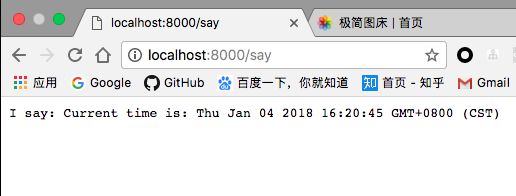
可以看到,在刚刚初始化异步模块的时候,服务器会等待请求的响应:

在异步模块加载完成后,服务器才会返回响应的信息:

模式:如果模块是需要异步初始化的,则对每个操作进行排队,直到模块完全初始化释放队列。
现在,我们的服务器可以在启动后立即开始接受请求,并保证这些请求都不会由于其模块的初始化状态而失败。我们能够在不使用DI的情况下获得这个结果,也不需要冗长且容易出错的检查来验证异步模块的状态。
其它场景的应用
我们刚刚介绍的模式被许多数据库驱动程序和ORM库所使用。 最值得注意的是Mongoose,它是MongoDB的ORM。使用Mongoose,不必等待数据库连接打开,以便能够发送查询,因为每个操作都排队,稍后与数据库的连接完全建立时执行。 这显然提高了其API的可用性。
看一下Mongoose的源码,它的每个方法是如何通过代理添加预初始化队列。 可以看看实现这中模式的代码片段: https://github.com/Automattic...
for (var i in Collection.prototype) {
(function(i){
NativeCollection.prototype[i] = function () {
if (this.buffer) {
// mongoose中,在缓冲区不为空时,只是简单地把这个操作加入缓冲区内
this.addQueue(i, arguments);
return;
}
var collection = this.collection
, args = arguments
, self = this
, debug = self.conn.base.options.debug;
if (debug) {
if ('function' === typeof debug) {
debug.apply(debug
, [self.name, i].concat(utils.args(args, 0, args.length-1)));
} else {
console.error('\x1B[0;36mMongoose:\x1B[0m %s.%s(%s) %s %s %s'
, self.name
, i
, print(args[0])
, print(args[1])
, print(args[2])
, print(args[3]))
}
}
return collection[i].apply(collection, args);
};
})(i);
}
异步批处理和缓存
在高负载的应用程序中,缓存起着至关重要的作用,几乎在网络中的任何地方,从网页,图像和样式表等静态资源到纯数据(如数据库查询的结果)都会使用缓存。 在本节中,我们将学习如何将缓存应用于异步操作,以及如何充分利用缓存解决高请求吞吐量的问题。
实现没有缓存或批处理的服务器
在这之前,我们来实现一个小型的服务器,以便用它来衡量缓存和批处理等技术在解决高负载应用程序的优势。
让我们考虑一个管理电子商务公司销售的web服务器,特别是对于查询我们的服务器所有特定类型的商品交易的总和的情况。 为此,考虑到LevelUP的简单性和灵活性,我们将再次使用LevelUP。我们要使用的数据模型是存储在sales这一个sublevel中的简单事务列表,它是以下的形式:
transactionId {amount, item}key由transactionId表示,value则是一个JSON对象,它包含amount,表示销售金额和item,表示项目类型。
要处理的数据是非常基本的,所以让我们立即在名为的totalSales.js文件中实现API,将如下所示:
const level = require('level');
const sublevel = require('level-sublevel');
const db = sublevel(level('example-db', {valueEncoding: 'json'}));
const salesDb = db.sublevel('sales');
module.exports = function totalSales(item, callback) {
console.log('totalSales() invoked');
let sum = 0;
salesDb.createValueStream() // [1]
.on('data', data => {
if(!item || data.item === item) { // [2]
sum += data.amount;
}
})
.on('end', () => {
callback(null, sum); // [3]
});
};该模块的核心是totalSales函数,它也是唯一exports的API;它进行如下工作:
- 我们从包含交易信息的
salesDb的sublevel创建一个Stream。Stream将从数据库中提取所有条目。 - 监听
data事件,这个事件触发时,将从数据库Stream中提取出每一项,如果这一项的item参数正是我们需要的item,就去累加它的amount到总的sum里面。 - 最后,
end事件触发时,我们最终调用callback()方法。
上述查询方式可能在性能方面并不好。理想情况下,在实际的应用程序中,我们可以使用索引,甚至使用增量映射来缩短实时计算的时间;但是,由于我们需要体现缓存的优势,对于上述例子来说,慢速的查询实际上更好,因为它会突出显示我们要分析的模式的优点。
为了完成总销售应用程序,我们只需要从HTTP服务器公开totalSales的API;所以,下一步是构建一个(app.js文件):
const http = require('http');
const url = require('url');
const totalSales = require('./totalSales');
http.createServer((req, res) => {
const query = url.parse(req.url, true).query;
totalSales(query.item, (err, sum) => {
res.writeHead(200);
res.end(`Total sales for item ${query.item} is ${sum}`);
});
}).listen(8000, () => console.log('Started'));我们创建的服务器是非常简单的;我们只需要它暴露totalSales API。
在我们第一次启动服务器之前,我们需要用一些示例数据填充数据库;我们可以使用专用于本节的代码示例中的populate_db.js脚本来执行此操作。该脚本将在数据库中创建100K个随机销售交易。
好的! 现在,一切都准备好了。 像往常一样,启动服务器,我们执行以下命令:
node app请求这个HTTP接口,访问至以下URL:
http://localhost:8000/?item=book但是,为了更好地了解服务器的性能,我们需要连续发送多个请求;所以,我们创建一个名为loadTest.js的脚本,它以200 ms的间隔发送请求。它已经被配置为连接到服务器的URL,因此,要运行它,执行以下命令:
node loadTest我们会看到这20个请求需要一段时间才能完成。注意测试的总执行时间,因为我们现在开始我们的服务,并测量我们可以节省多少时间。
批量异步请求
在处理异步操作时,最基本的缓存级别可以通过将一组调用集中到同一个API来实现。这非常简单:如果我们在调用异步函数的同时在队列中还有另一个尚未处理的回调,我们可以将回调附加到已经运行的操作上,而不是创建一个全新的请求。看下图的情况:
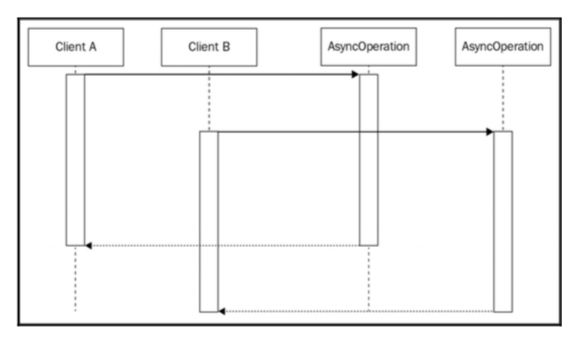
前面的图像显示了两个客户端(它们可以是两台不同的机器,或两个不同的Web请求),使用完全相同的输入调用相同的异步操作。 当然,描述这种情况的自然方式是由两个客户开始两个单独的操作,这两个操作将在两个不同的时刻完成,如前图所示。现在考虑下一个场景,如下图所示:
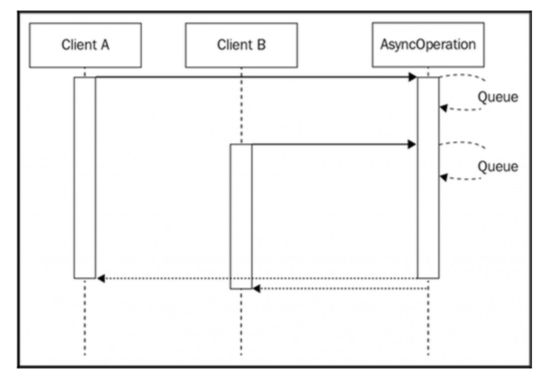
上图向我们展示了如何对API的两个请求进行批处理,或者换句话说,对两个请求执行到相同的操作。通过这样做,当操作完成时,两个客户端将同时被通知。这代表了一种简单而又非常强大的方式来降低应用程序的负载,而不必处理更复杂的缓存机制,这通常需要适当的内存管理和缓存失效策略。
在电子商务销售的Web服务器中使用批处理
现在让我们在totalSales API上添加一个批处理层。我们要使用的模式非常简单:如果在API被调用时已经有另一个相同的请求挂起,我们将把这个回调添加到一个队列中。当异步操作完成时,其队列中的所有回调立即被调用。
现在,让我们来改变之前的代码:创建一个名为totalSalesBatch.js的新模块。在这里,我们将在原始的totalSales API之上实现一个批处理层:
const totalSales = require('./totalSales');
const queues = {};
module.exports = function totalSalesBatch(item, callback) {
if(queues[item]) { // [1]
console.log('Batching operation');
return queues[item].push(callback);
}
queues[item] = [callback]; // [2]
totalSales(item, (err, res) => {
const queue = queues[item]; // [3]
queues[item] = null;
queue.forEach(cb => cb(err, res));
});
};totalSalesBatch()函数是原始的totalSales() API的代理,它的工作原理如下:
- 如果请求的
item已经存在队列中,则意味着该特定item的请求已经在服务器任务队列中。在这种情况下,我们所要做的只是将回调push到现有队列,并立即从调用中返回。不进行后续操作。 - 如果请求的
item没有在队列中,这意味着我们必须创建一个新的请求。为此,我们为该特定item的请求创建一个新队列,并使用当前回调函数对其进行初始化。 接下来,我们调用原始的totalSales() API。 - 当原始的
totalSales()请求完成时,则执行我们的回调函数,我们遍历队列中为该特定请求的item添加的所有回调,并分别调用这些回调函数。
totalSalesBatch()函数的行为与原始的totalSales() API的行为相同,不同之处在于,现在对于相同内容的请求API进行批处理,从而节省时间和资源。
想知道相比于totalSales() API原始的非批处理版本,在性能方面的优势是什么?然后,让我们将HTTP服务器使用的totalSales模块替换为我们刚刚创建的模块,修改app.js文件如下:
//const totalSales = require('./totalSales');
const totalSales = require('./totalSalesBatch');
http.createServer(function(req, res) {
// ...
});如果我们现在尝试再次启动服务器并进行负载测试,我们首先看到的是请求被批量返回。
除此之外,我们观察到请求的总时间大大减少;它应该至少比对原始totalSales() API执行的原始测试快四倍!
这是一个惊人的结果,证明了只需应用一个简单的批处理层即可获得巨大的性能提升,比起缓存机制,也没有显得太复杂,因为,无需考虑缓存淘汰策略。
批处理模式在高负载应用程序和执行较为缓慢的
API中发挥巨大作用,正是由于这种模式的运用,可以批量处理大量的请求。
异步请求缓存策略
异步批处理模式的问题之一是对于API的答复越快,我们对于批处理来说,其意义就越小。有人可能会争辩说,如果一个API已经很快了,那么试图优化它就没有意义了。然而,它仍然是一个占用应用程序的资源负载的因素,总结起来,仍然可以有解决方案。另外,如果API调用的结果不会经常改变;因此,这时候批处理将并不会有较好的性能提升。在这种情况下,减少应用程序负载并提高响应速度的最佳方案肯定是更好的缓存模式。
缓存模式很简单:一旦请求完成,我们将其结果存储在缓存中,该缓存可以是变量,数据库中的条目,也可以是专门的缓存服务器。因此,下一次调用API时,可以立即从缓存中检索结果,而不是产生另一个请求。
对于一个有经验的开发人员来说,缓存不应该是多么新的技术,但是异步编程中这种模式的不同之处在于它应该与批处理结合在一起,以达到最佳效果。原因是因为多个请求可能并发运行,而没有设置缓存,并且当这些请求完成时,缓存将会被设置多次,这样做则会造成缓存资源的浪费。
基于这些假设,异步请求缓存模式的最终结构如下图所示:
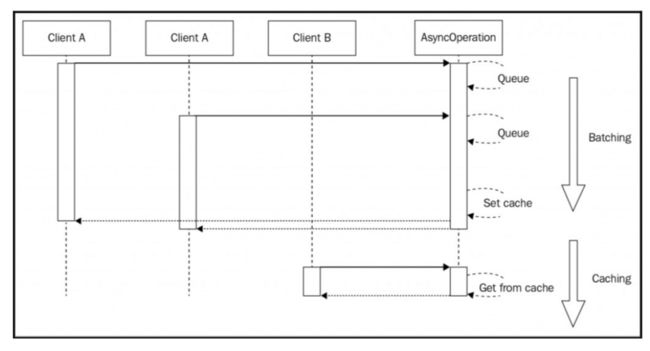
上图给出了异步缓存算法的两个步骤:
- 与批处理模式完全相同,与在未设置高速缓存时接收到的任何请求将一起批处理。这些请求完成时,缓存将会被设置一次。
- 当缓存最终被设置时,任何后续的请求都将直接从缓存中提供。
另外我们需要考虑Zalgo的反作用(我们已经在Chapter 2-Node.js Essential Patterns中看到了它的实际应用)。在处理异步API时,我们必须确保始终以异步方式返回缓存的值,即使访问缓存只涉及同步操作。
在电子商务销售的Web服务器中使用异步缓存请求
实践异步缓存模式的优点,现在让我们将我们学到的东西应用到totalSales() API。
与异步批处理示例程序一样,我们创建一个代理,其作用是添加缓存层。
然后创建一个名为totalSalesCache.js的新模块,代码如下:
const totalSales = require('./totalSales');
const queues = {};
const cache = {};
module.exports = function totalSalesBatch(item, callback) {
const cached = cache[item];
if (cached) {
console.log('Cache hit');
return process.nextTick(callback.bind(null, null, cached));
}
if (queues[item]) {
console.log('Batching operation');
return queues[item].push(callback);
}
queues[item] = [callback];
totalSales(item, (err, res) => {
if (!err) {
cache[item] = res;
setTimeout(() => {
delete cache[item];
}, 30 * 1000); //30 seconds expiry
}
const queue = queues[item];
queues[item] = null;
queue.forEach(cb => cb(err, res));
});
};我们可以看到前面的代码与我们异步批处理的很多地方基本相同。 其实唯一的区别是以下几点:
- 我们需要做的第一件事就是检查缓存是否被设置,如果是这种情况,我们将立即使用
callback()返回缓存的值,这里必须要使用process.nextTick(),因为缓存可能是异步设定的,需要等到下一次事件轮询时才能够保证缓存已经被设定。 - 继续异步批处理模式,但是这次,当原始
API成功完成时,我们将结果保存到缓存中。此外,我们还设置了一个缓存淘汰机制,在30秒后使缓存失效。 一个简单而有效的技术!
现在,我们准备尝试我们刚创建的totalSales模块。 先更改app.js模块,如下所示:
// const totalSales = require('./totalSales');
// const totalSales = require('./totalSalesBatch');
const totalSales = require('./totalSalesCache');
http.createServer(function(req, res) {
// ...
});现在,重新启动服务器,并使用loadTest.js脚本进行配置,就像我们在前面的例子中所做的那样。使用默认的测试参数,与简单的异步批处理模式相比,很明显地有了更好的性能提升。 当然,这很大程度上取决于很多因素;例如收到的请求数量,以及一个请求和另一个请求之间的延迟等。当请求数量较高且跨越较长时间时,使用高速缓存批处理的优势将更为显著。
Memoization被称做缓存函数调用的结果的算法。 在npm中,你可以找到许多包来实现异步的memoization,其中最著名的之一之一是 memoizee。
有关实现缓存机制的说明
我们必须记住,在实际应用中,我们可能想要使用更先进的失效技术和存储机制。 这可能是必要的,原因如下:
- 大量的缓存值可能会消耗大量内存。 在这种情况下,可以应用最近最少使用(
LRU)算法来保持恒定的存储器利用率。 - 当应用程序分布在多个进程中时,对缓存使用简单变量可能会导致每个服务器实例返回不同的结果。如果这对于我们正在实现的特定应用程序来说是不希望的,那么解决方案就是使用共享存储来存储缓存。 常用的解决方案是Redis和Memcached。
- 与定时淘汰缓存相比,手动淘汰高速缓存可使得高速缓存使用寿命更长,同时提供更新的数据,但当然,管理起缓存来要复杂得多。
使用Promise进行批处理和缓存
在Chapter4-Asynchronous Control Flow Patterns with ES2015 and Beyond中,我们看到了Promise如何极大地简化我们的异步代码,但是在处理批处理和缓存时,它则可以提供更大的帮助。
利用Promise进行异步批处理和缓存策略,有如下两个优点:
- 多个
then()监听器可以附加到相同的Promise实例。 -
then()监听器最多保证被调用一次,即使在Promise已经被resolve了之后,then()也能正常工作。 此外,then()总是会被保证其是异步调用的。
简而言之,第一个优点正是批处理请求所需要的,而第二个优点则在Promise已经是解析值的缓存时,也会提供同样的的异步返回缓存值的机制。
下面开始看代码,我们可以尝试使用Promises为totalSales()创建一个模块,在其中添加批处理和缓存功能。创建一个名为totalSalesPromises.js的新模块:
const pify = require('pify'); // [1]
const totalSales = pify(require('./totalSales'));
const cache = {};
module.exports = function totalSalesPromises(item) {
if (cache[item]) { // [2]
return cache[item];
}
cache[item] = totalSales(item) // [3]
.then(res => { // [4]
setTimeout(() => {delete cache[item]}, 30 * 1000); //30 seconds expiry
return res;
})
.catch(err => { // [5]
delete cache[item];
throw err;
});
return cache[item]; // [6]
};Promise确实很好,下面是上述函数的功能描述:
- 首先,我们需要一个名为pify的模块,它允许我们对
totalSales()模块进行promisification。这样做之后,totalSales()将返回一个符合ES2015标准的Promise实例,而不是接受一个回调函数作为参数。 - 当调用
totalSalesPromises()时,我们检查给定的项目类型是否已经在缓存中有相应的Promise。如果我们已经有了这样的Promise,我们直接返回这个Promise实例。 - 如果我们在缓存中没有针对给定项目类型的
Promise,我们继续通过调用原始(promisified)的totalSales()来创建一个Promise实例。 - 当
Promise正常resolve了,我们设置了一个清除缓存的时间(假设为30秒),我们返回res将操作的结果返回给应用程序。 - 如果
Promise被异常reject了,我们立即重置缓存,并再次抛出错误,将其传播到Promise chain中,所以任何附加到相同Promise的其他应用程序也将收到这一异常。 - 最后,我们返回我们刚才创建或者缓存的
Promise实例。
非常简单直观,更重要的是,我们使用Promise也能够实现批处理和缓存。
如果我们现在要尝试使用totalSalesPromise()函数,稍微调整app.js模块,因为现在使用Promise而不是回调函数。 让我们通过创建一个名为appPromises.js的app模块来实现:
const http = require('http');
const url = require('url');
const totalSales = require('./totalSalesPromises');
http.createServer(function(req, res) {
const query = url.parse(req.url, true).query;
totalSales(query.item).then(function(sum) {
res.writeHead(200);
res.end(`Total sales for item ${query.item} is ${sum}`);
});
}).listen(8000, function() {console.log('Started')});它的实现与原始应用程序模块几乎完全相同,不同的是现在我们使用的是基于Promise的批处理/缓存封装版本; 因此,我们调用它的方式也略有不同。
运行以下命令开启这个新版本的服务器:
node appPromises运行与CPU-bound的任务
虽然上面的totalSales()在系统资源上面消耗较大,但是其也不会影响服务器处理并发的能力。 我们在Chapter1-Welcome to the Node.js Platform中了解到有关事件循环的内容,应该为此行为提供解释:调用异步操作会导致堆栈退回到事件循环,从而使其免于处理其他请求。
但是,当我们运行一个长时间的同步任务时,会发生什么情况,从不会将控制权交还给事件循环?
这种任务也被称为CPU-bound,因为它的主要特点是CPU利用率较高,而不是I/O操作繁重。
让我们立即举一个例子上看看这些类型的任务在Node.js中的具体行为。
解决子集总和问题
现在让我们做一个CPU占用比较高的高计算量的实验。下面来看的是子集总和问题,我们计算一个数组中是否具有一个子数组,其总和为0。例如,如果我们有数组[1, 2, -4, 5, -3]作为输入,则满足问题的子数组是[1, 2, -3]和[2, -4, 5, -3]。
最简单的算法是把每一个数组元素做遍历然后依次计算,时间复杂度为O(2^n),或者换句话说,它随着输入的数组长度成指数增长。这意味着一组20个整数则会有多达1, 048, 576中情况,显然不能够通过穷举来做到。当然,这个问题的解决方案可能并不算复杂。为了使事情变得更加困难,我们将考虑数组和问题的以下变化:给定一组整数,我们要计算所有可能的组合,其总和等于给定的任意整数。
const EventEmitter = require('events').EventEmitter;
class SubsetSum extends EventEmitter {
constructor(sum, set) {
super();
this.sum = sum;
this.set = set;
this.totalSubsets = 0;
} //...
}SubsetSum类是EventEmitter类的子类;这使得我们每次找到一个匹配收到的总和作为输入的新子集时都会发出一个事件。 我们将会看到,这会给我们很大的灵活性。
接下来,让我们看看我们如何能够生成所有可能的子集组合:
开始构建一个这样的算法。创建一个名为subsetSum.js的新模块。在其中声明一个SubsetSum类:
_combine(set, subset) {
for(let i = 0; i < set.length; i++) {
let newSubset = subset.concat(set[i]);
this._combine(set.slice(i + 1), newSubset);
this._processSubset(newSubset);
}
}不管算法其中到底是什么内容,但有两点要注意:
-
_combine()方法是完全同步的;它递归地生成每一个可能的子集,而不把CPU控制权交还给事件循环。如果我们考虑一下,这对于不需要任何I/O的算法来说是非常正常的。 - 每当生成一个新的组合时,我们都会将这个组合提供给
_processSubset()方法以供进一步处理。
_processSubset()方法负责验证给定子集的元素总和是否等于我们要查找的数字:
_processSubset(subset) {
console.log('Subset', ++this.totalSubsets, subset);
const res = subset.reduce((prev, item) => (prev + item), 0);
if (res == this.sum) {
this.emit('match', subset);
}
}简单地说,_processSubset()方法将reduce操作应用于子集,以便计算其元素的总和。然后,当结果总和等于给定的sum参数时,会发出一个match事件。
最后,调用start()方法开始执行算法:
start() {
this._combine(this.set, []);
this.emit('end');
}通过调用_combine()触发算法,最后触发一个end事件,表明所有的组合都被检查过,并且任何可能的匹配都已经被计算出来。 这是可能的,因为_combine()是同步的; 因此,只要前面的函数返回,end事件就会触发,这意味着所有的组合都被计算出来了。
接下来,我们在网络上公开刚刚创建的算法。可以使用一个简单的HTTP服务器对响应的任务作出响应。 特别是,我们希望以/subsetSum?data=这样的请求格式进行响应,传入给定的数组和sum,使用SubsetSum算法进行匹配。
在一个名为app.js的模块中实现这个简单的服务器:
const http = require('http');
const SubsetSum = require('./subsetSum');
http.createServer((req, res) => {
const url = require('url').parse(req.url, true);
if(url.pathname === '/subsetSum') {
const data = JSON.parse(url.query.data);
res.writeHead(200);
const subsetSum = new SubsetSum(url.query.sum, data);
subsetSum.on('match', match => {
res.write('Match: ' + JSON.stringify(match) + '\n');
});
subsetSum.on('end', () => res.end());
subsetSum.start();
} else {
res.writeHead(200);
res.end('I\m alive!\n');
}
}).listen(8000, () => console.log('Started'));由于SubsetSum实例使用事件返回结果,所以我们可以在算法生成后立即对匹配的结果使用Stream进行处理。另一个需要注意的细节是,每次我们的服务器都会返回I'm alive!,这样我们每次发送一个不同于/subsetSum的请求的时候。可以用来检查我们服务器是否挂掉了,这在稍后将会看到。
开始运行:
node app一旦服务器启动,我们准备发送我们的第一个请求;让我们尝试发送一组17个随机数,这将导致产生131,071个组合,那么服务器将会处理一段时间:
curl -G http://localhost:8000/subsetSum --data-urlencode "data=[116,119,101,101,-116,109,101,-105,-102,117,-115,-97,119,-116,-104,-105,115]"--data-urlencode "sum=0"这是如果我们在第一个请求仍在运行的时候在另一个终端中尝试输入以下命令,我们将发现一个巨大的问题:
curl -G http://localhost:8000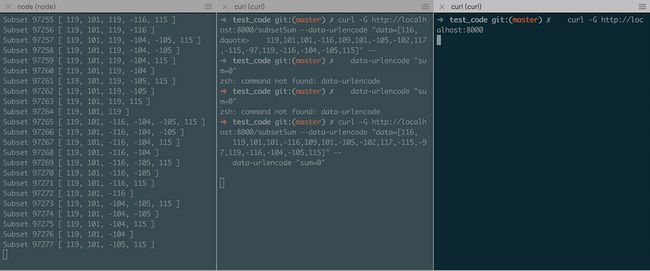
我们会看到直到第一个请求结束之前,最后一个请求一直处于挂起的状态。服务器没有返回响应!这正如我们所想的那样。Node.js事件循环运行在一个单独的线程中,如果这个线程被一个长的同步计算阻塞,它将不能再执行一个循环来响应I'm alive!,
我们必须知道,这种代码显然不能够用于同时接收到多个请求的应用程序。
但是不要对Node.js中绝望,我们可以通过几种方式来解决这种情况。我们来分析一下最常见的两种方案:
使用setImmediate
通常,CPU-bound算法是建立在一定规则之上的。它可以是一组递归调用,一个循环,或者基于这些的任何变化/组合。 所以,对于我们的问题,一个简单的解决方案就是在这些步骤完成后(或者在一定数量的步骤之后),将控制权交还给事件循环。这样,任何待处理的I / O仍然可以在事件循环在长时间运行的算法产生CPU的时间间隔中处理。对于这个问题而言,解决这一问题的方式是把算法的下一步在任何可能导致挂起的I/O请求之后运行。这听起来像是setImmediate()方法的完美用例(我们已经在Chapter2-Node.js Essential Patterns中介绍过这一API)。
模式:使用
setImmediate()交错执行长时间运行的同步任务。
使用setImmediate进行子集求和算法的步骤
现在我们来看看这个模式如何应用于子集求和算法。 我们所要做的只是稍微修改一下subsetSum.js模块。 为方便起见,我们将创建一个名为subsetSumDefer.js的新模块,将原始的subsetSum类的代码作为起点。
我们要做的第一个改变是添加一个名为_combineInterleaved()的新方法,它是我们正在实现的模式的核心:
_combineInterleaved(set, subset) {
this.runningCombine++;
setImmediate(() => {
this._combine(set, subset);
if(--this.runningCombine === 0) {
this.emit('end');
}
});
}正如我们所看到的,我们所要做的只是使用setImmediate()调用原始的同步的_combine()方法。然而,现在的问题是因为该算法不再是同步的,我们更难以知道何时已经完成了所有的组合的计算。
为了解决这个问题,我们必须使用非常类似于我们在Chapter3-Asynchronous Control Flow Patterns with Callbacks看到的异步并行执行的模式来追溯_combine()方法的所有正在运行的实例。 当_combine()方法的所有实例都已经完成运行时,触发end事件,通知任何监听器,进程需要做的所有动作都已经完成。
对于最终子集求和算法的重构版本。首先,我们需要将_combine()方法中的递归步骤替换为异步:
_combine(set, subset) {
for(let i = 0; i < set.length; i++) {
let newSubset = subset.concat(set[i]);
this._combineInterleaved(set.slice(i + 1), newSubset);
this._processSubset(newSubset);
}
}通过上面的更改,我们确保算法的每个步骤都将使用setImmediate()在事件循环中排队,在事件循环队列中I / O请求之后执行,而不是同步运行造成阻塞。
另一个小调整是对于start()方法:
start() {
this.runningCombine = 0;
this._combineInterleaved(this.set, []);
}在前面的代码中,我们将_combine()方法的运行实例的数量初始化为0.我们还通过调用_combineInterleaved()来将调用替换为_combine(),并移除了end的触发,因为现在_combineInterleaved()是异步处理的。
通过这个最后的改变,我们的子集求和算法现在应该能够通过事件循环可以运行的时间间隔交替地运行其可能大量占用CPU的代码,并且不会再造成阻塞。
最后更新app.js模块,以便它可以使用新版本的SubsetSum:
const http = require('http');
// const SubsetSum = require('./subsetSum');
const SubsetSum = require('./subsetSumDefer');
http.createServer(function(req, res) {
// ...
})和之前一样的方式开始运行,结果如下:
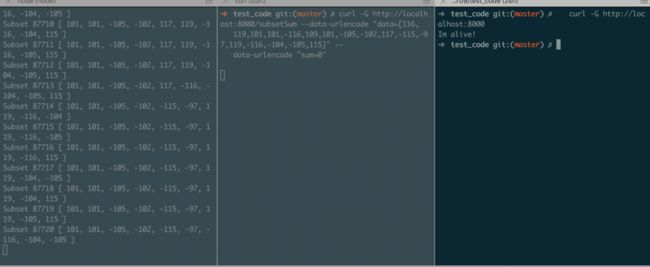
此时,使用异步的方式运行,不再会阻塞CPU了。
interleaving模式
正如我们所看到的,在保持应用程序的响应性的同时运行一个CPU-bound的任务并不复杂,只需要使用setImmediate()把同步执行的代码变为异步执行即可。但是,这不是效率最好的模式;实际上,延迟执行一个任务会额外带来一个小的开销,在这样的算法中,积少成多,则会产生重大的影响。这通常是我们在运行CPU限制任务时所需要的最后一件事情,特别是如果我们必须将结果直接返回给用户,这应该在合理的时间内进行响应。 缓解这个问题的一个可能的解决方案是只有在一定数量的步骤之后使用setImmediate(),而不是在每一步中使用它。但是这仍然不能解决问题的根源。
记住,这并不是说一旦我们想要通过异步的模式来执行CPU-bound的任务,我们就应该不惜一切代价来避免这样的额外开销,事实上,从更广阔的角度来看,同步任务并不一定非常漫长和复杂,以至于造成麻烦。在繁忙的服务器中,即使是阻塞事件循环200毫秒的任务也会产生不希望的延迟。 在那些并发量并不高的服务器来说,即使产生一定短时的阻塞,也不会影响性能,使用交错执行setImmediate()可能是避免阻塞事件循环的最简单也是最有效的方法。
process.nextTick()不能用于交错长时间运行的任务。正如我们在Chapter1-Welcome to the Node.js Platform中看到的,nextTick()会在任何未返回的I / O之前调度,并且在重复调用process.nextTick()最终会导致I / O饥饿。 你可以通过在前面的例子中用process.nextTick()替换setImmediate()来验证。
使用多个进程
使用interleaving模式并不是我们用来运行CPU-bound任务的唯一方法;防止事件循环阻塞的另一种模式是使用子进程。我们已经知道Node.js在运行I / O密集型应用程序(如Web服务器)的时候是最好的,因为Node.js可以使得我们可以通过异步来优化资源利用率。
所以,我们必须保持应用程序响应的最好方法是不要在主应用程序的上下文中运行昂贵的CPU-bound任务,而是使用单独的进程。这有三个主要的优点:
- 同步任务可以全速运行,而不需要交错执行的步骤
- 在
Node.js中处理进程很简单,可能比修改一个使用setImmediate()的算法更容易,并且多进程允许我们轻松使用多个处理器,而无需扩展主应用程序本身。 - 如果我们真的需要超高的性能,可以使用低级语言,如性能良好的
C。
Node.js有一个充足的API库带来与外部进程交互。 我们可以在child_process模块中找到我们需要的所有东西。 而且,当外部进程只是另一个Node.js程序时,将它连接到主应用程序是非常容易的,我们甚至不觉得我们在本地应用程序外部运行任何东西。这得益于child_process.fork()函数,该函数创建一个新的子Node.js进程,并自动创建一个通信管道,使我们能够使用与EventEmitter非常相似的接口交换信息。来看如何用这个特性来重构我们的子集求和算法。
将子集求和任务委托给其他进程
重构SubsetSum任务的目标是创建一个单独的子进程,负责处理CPU-bound的任务,使服务器的事件循环专注于处理来自网络的请求:
- 我们将创建一个名为
processPool.js的新模块,它将允许我们创建一个正在运行的进程池。创建一个新的进程代价昂贵,需要时间,因此我们需要保持它们不断运行,尽量不要产生中断,时刻准备好处理请求,使我们可以节省时间和CPU。此外,进程池需要帮助我们限制同时运行的进程数量,以避免将使我们的应用程序受到拒绝服务(DoS)攻击。 - 接下来,我们将创建一个名为
subsetSumFork.js的模块,负责抽象子进程中运行的SubsetSum任务。 它的角色将与子进程进行通信,并将任务的结果展示为来自当前应用程序。 - 最后,我们需要一个
worker(我们的子进程),一个新的Node.js程序,运行子集求和算法并将其结果转发给父进程。
DoS攻击是企图使其计划用户无法使用机器或网络资源,例如临时或无限中断或暂停连接到Internet的主机的服务。
实现一个进程池
先从构建processPool.js模块开始:
const fork = require('child_process').fork;
class ProcessPool {
constructor(file, poolMax) {
this.file = file;
this.poolMax = poolMax;
this.pool = [];
this.active = [];
this.waiting = [];
} //...
}在模块的第一部分,引入我们将用来创建新进程的child_process.fork()函数。 然后,我们定义ProcessPool的构造函数,该构造函数接受表示要运行的Node.js程序的文件参数以及池中运行的最大实例数poolMax作为参数。然后我们定义三个实例变量:
-
pool表示的是准备运行的进程 -
active表示的是当前正在运行的进程列表 -
waiting包含所有这些请求的任务队列,保存由于缺少可用的资源而无法立即实现的任务
看ProcessPool类的acquire()方法,它负责取出一个准备好被使用的进程:
acquire(callback) {
let worker;
if(this.pool.length > 0) { // [1]
worker = this.pool.pop();
this.active.push(worker);
return process.nextTick(callback.bind(null, null, worker));
}
if(this.active.length >= this.poolMax) { // [2]
return this.waiting.push(callback);
}
worker = fork(this.file); // [3]
this.active.push(worker);
process.nextTick(callback.bind(null, null, worker));
}函数逻辑如下:
- 如果在进程池中有一个准备好被使用的进程,我们只需将其移动到
active数组中,然后通过异步的方式调用其回调函数。 - 如果池中没有可用的进程,或者已经达到运行进程的最大数量,必须等待。通过把当前回调放入
waiting数组。 - 如果我们还没有达到运行进程的最大数量,我们将使用
child_process.fork()创建一个新的进程,将其添加到active列表中,然后调用其回调。
ProcessPool类的最后一个方法是release(),其目的是将一个进程放回进程池中:
release(worker) {
if(this.waiting.length > 0) { // [1]
const waitingCallback = this.waiting.shift();
waitingCallback(null, worker);
}
this.active = this.active.filter(w => worker !== w); // [2]
this.pool.push(worker);
}前面的代码也很简单,其解释如下:
- 如果在
waiting任务队列里面有任务需要被执行,我们只需为这个任务分配一个进程worker执行。 - 否则,如果在
waiting任务队列中都没有需要被执行的任务,我们则把active的进程列表中的进程放回进程池中。
正如我们所看到的,进程从来没有中断,只在为其不断地重新分配任务,使我们可以通过在每个请求不重新启动一个进程达到节省时间和空间的目的。然而,重要的是要注意,这可能并不总是最好的选择,这很大程度上取决于我们的应用程序的要求。为减少进程池长期占用内存,可能的调整如下:
- 在一个进程空闲一段时间后,终止进程,释放内存空间。
- 添加一个机制来终止或重启没有响应的或者崩溃了的进程。
父子进程通信
现在我们的ProcessPool类已经准备就绪,我们可以使用它来实现SubsetSumFork模块,SubsetSumFork的作用是与子进程进行通信得到子集求和的结果。前面曾说到,用child_process.fork()启动一个进程也给了我们创建了一个简单的基于消息的管道,通过实现subsetSumFork.js模块来看看它是如何工作的:
const EventEmitter = require('events').EventEmitter;
const ProcessPool = require('./processPool');
const workers = new ProcessPool(__dirname + '/subsetSumWorker.js', 2);
class SubsetSumFork extends EventEmitter {
constructor(sum, set) {
super();
this.sum = sum;
this.set = set;
}
start() {
workers.acquire((err, worker) => { // [1]
worker.send({sum: this.sum, set: this.set});
const onMessage = msg => {
if (msg.event === 'end') { // [3]
worker.removeListener('message', onMessage);
workers.release(worker);
}
this.emit(msg.event, msg.data); // [4]
};
worker.on('message', onMessage); // [2]
});
}
}
module.exports = SubsetSumFork;首先注意,我们在subsetSumWorker.js调用ProcessPool的构造函数创建ProcessPool实例。 我们还将进程池的最大容量设置为2。
另外,我们试图维持原来的SubsetSum类相同的公共API。实际上,SubsetSumFork是EventEmitter的子类,它的构造函数接受sum和set,而start()方法则触发算法的执行,而这个SubsetSumFork实例运行在一个单独的进程上。调用start()方法时会发生的情况:
- 我们试图从进程池中获得一个新的子进程。在创建进程成功之后,我们尝试向子进程发送一条消息,包含
sum和set。send()方法是Node.js自动提供给child_process.fork()创建的所有进程,这实际上与父子进程之间的通信管道有关。 - 然后我们开始监听子进程返回的任何消息,我们使用
on()方法附加一个新的事件监听器(这也是所有以child_process.fork()创建的进程提供的通信通道的一部分)。 - 在事件监听器中,我们首先检查是否收到一个
end事件,这意味着SubsetSum所有任务已经完成,在这种情况下,我们删除onMessage监听器并释放worker,并将其放回进程池中,不再让其占用内存资源和CPU资源。 -
worker以{event,data}格式生成消息,使得任何时候一旦子进程处理完毕任务,我们在外部都能接收到这一消息。
这就是SubsetSumFork模块现在我们来实现这个worker应用程序。
与父进程进行通信
现在我们来创建subsetSumWorker.js模块,我们的应用程序,这个模块的全部内容将在一个单独的进程中运行:
const SubsetSum = require('./subsetSum');
process.on('message', msg => { // [1]
const subsetSum = new SubsetSum(msg.sum, msg.set);
subsetSum.on('match', data => { // [2]
process.send({event: 'match', data: data});
});
subsetSum.on('end', data => {
process.send({event: 'end', data: data});
});
subsetSum.start();
});由于我们的handler处于一个单独的进程中,我们不必担心这类CPU-bound任务阻塞事件循环,所有的HTTP请求将继续由主应用程序的事件循环处理,而不会中断。
当子进程开始启动时,父进程:
- 子进程立即开始监听来自父进程的消息。这可以通过
process.on()函数轻松实现。我们期望从父进程中唯一的消息是为新的SubsetSum任务提供输入的消息。只要收到这样的消息,我们创建一个SubsetSum类的新实例,并注册match和end事件监听器。最后,我们用subsetSum.start()开始计算。 - 每次子集求和算法收到事件时,把结果它封装在格式为
{event,data}的对象中,并将其发送给父进程。这些消息然后在subsetSumFork.js模块中处理,就像我们在前面的章节中看到的那样。
注意:当子进程不是
Node.js进程时,则上述的通信管道就不可用了。在这种情况下,我们仍然可以通过在暴露于父进程的标准输入流和标准输出流之上实现我们自己的协议来建立父子进程通信的接口。
多进程模式
尝试新版本的子集求和算法,我们只需要替换HTTP服务器使用的模块(文件app.js):
运行结果如下:

更有趣的是,我们也可以尝试同时启动两个subsetSum任务,我们可以充分看到多核CPU的作用。 相反,如果我们尝试同时运行三个subsetSum任务,结果应该是最后一个启动将挂起。这不是因为主进程的事件循环被阻塞,而是因为我们为subsetSum任务设置了两个进程的并发限制。
正如我们所看到的,多进程模式比interleaving模式更加强大和灵活;然而,由于单个机器提供的CPU和内存资源量仍然是一个硬性限制,所以它仍然不可扩展。在这种情况下,将负载分配到多台机器上,则是更优秀的解决办法。
值得一提的是,在运行CPU-bound任务时,多线程可以成为多进程的替代方案。目前,有几个npm包公开了一个用于处理用户级模块的线程的API;其中最流行的是 webworker-threads。但是,即使线程更轻量级,完整的进程也可以提供更大的灵活性,并具备更高更可靠的容错处理。
总结
本章讲述以下三点:
- 异步初始化模块
- 批处理和缓存在
Node.js异步中的运用 - 使用异步或者多进程来处理
CPU-bound的任务