Tuesday, September 12, 2017
Posted by The TensorFlow Team
TensorFlow 1.3 introduces two important features that you should try out:
Datasets: A completely new way of creating input pipelines (that is, reading data into your program).
Estimators: A high-level way to create TensorFlow models. Estimators include pre-made models for common machine learning tasks, but you can also use them to create your own custom models.
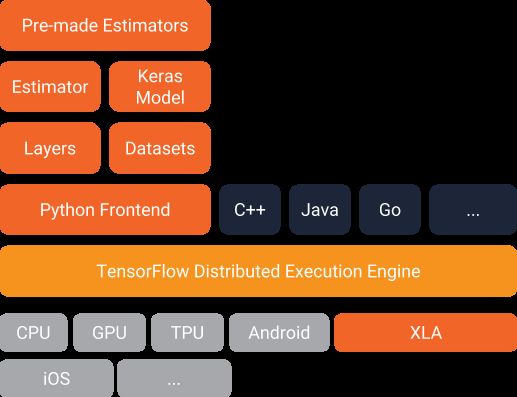
Below you can see how they fit in the TensorFlow architecture. Combined, they offer an easy way to create TensorFlow models and to feed data to them:
Our Example Model
To explore these features we're going to build a model and show you relevant code snippets. The complete code is available here, including instructions for getting the training and test files. Note that the code was written to demonstrate how Datasets and Estimators work functionally, and was not optimized for maximum performance.
The trained model categorizes Iris flowers based on four botanical features (sepal length, sepal width, petal length, and petal width). So, during inference, you can provide values for those four features and the model will predict that the flower is one of the following three beautiful variants:
From left to right: Iris setosa (by Radomil, CC BY-SA 3.0), Iris versicolor (by Dlanglois, CC BY-SA 3.0), and Iris virginica(by Frank Mayfield, CC BY-SA 2.0).
We're going to train a Deep Neural Network Classifier with the below structure. All input and output values will be float32, and the sum of the output values will be 1 (as we are predicting the probability for each individual Iris type):
For example, an output result might be 0.05 for Iris Setosa, 0.9 for Iris Versicolor, and 0.05 for Iris Virginica, which indicates a 90% probability that this is an Iris Versicolor.
Alright! Now that we have defined the model, let's look at how we can use Datasets and Estimators to train it and make predictions.
Introducing The Datasets
Datasets is a new way to create input pipelines to TensorFlow models. This API is much more performant than using feed_dict or the queue-based pipelines, and it's cleaner and easier to use. Although Datasets still resides in tf.contrib.data at 1.3, we expect to move this API to core at 1.4, so it's high time to take it for a test drive.
At a high-level, the Datasets consists of the following classes:
Where:
- Dataset: Base class containing methods to create and transform datasets. Also allows you initialize a dataset from data in memory, or from a Python generator.
- TextLineDataset: Reads lines from text files.
- TFRecordDataset: Reads records from TFRecord files.
- FixedLengthRecordDataset: Reads fixed size records from binary files.
- Iterator: Provides a way to access one dataset element at a time.
Our dataset
To get started, let's first look at the dataset we will use to feed our model. We'll read data from a CSV file, where each row will contain five values-the four input values, plus the label:
The label will be:
- 0 for Iris Setosa
- 1 for Versicolor
- 2 for Virginica.
Representing our dataset
To describe our dataset, we first create a list of our features:
feature_names = [
'SepalLength',
'SepalWidth',
'PetalLength',
'PetalWidth']
When we train our model, we'll need a function that reads the input file and returns the feature and label data. Estimators requires that you create a function of the following format:
def input_fn():
......
return ({ 'SepalLength':[values], ...., 'PetalWidth':[values] },
[IrisFlowerType])
The return value must be a two-element tuple organized as follows: :
- The first element must be a dict in which each input feature is a key, and then a list of values for the training batch.
- The second element is a list of labels for the training batch.
Since we are returning a batch of input features and training labels, it means that all lists in the return statement will have equal lengths. Technically speaking, whenever we referred to "list" here, we actually mean a 1-d TensorFlow tensor.
To allow simple reuse of the input_fn we're going to add some arguments to it. This allows us to build input functions with different settings. The arguments are pretty straightforward:
-
file_path: The data file to read. -
perform_shuffle: Whether the record order should be randomized. -
repeat_count: The number of times to iterate over the records in the dataset. For example, if we specify 1, then each record is read once. If we specify None, iteration will continue forever.
Here's how we can implement this function using the Dataset API. We will wrap this in an "input function" that is suitable when feeding our Estimator model later on:
def my_input_fn(file_path, perform_shuffle=False, repeat_count=1):
def decode_csv(line):
parsed_line = tf.decode_csv(line, [[0.], [0.], [0.], [0.], [0]])
label = parsed_line[-1:] # Last element is the label
del parsed_line[-1] # Delete last element
features = parsed_line # Everything (but last element) are the features
d = dict(zip(feature_names, features)), label
return d
dataset = (tf.contrib.data.TextLineDataset(file_path) # Read text file
.skip(1) # Skip header row
.map(decode_csv)) # Transform each elem by applying decode_csv fn
if perform_shuffle:
# Randomizes input using a window of 256 elements (read into memory)
dataset = dataset.shuffle(buffer_size=256)
dataset = dataset.repeat(repeat_count) # Repeats dataset this # times
dataset = dataset.batch(32) # Batch size to use
iterator = dataset.make_one_shot_iterator()
batch_features, batch_labels = iterator.get_next()
return batch_features, batch_labels
Note the following: :
-
TextLineDataset: The Dataset API will do a lot of memory management for you when you're using its file-based datasets. You can, for example, read in dataset files much larger than memory or read in multiple files by specifying a list as argument. -
shuffle: Reads buffer_size records, then shuffles (randomizes) their order. -
map: Calls thedecode_csvfunction with each element in the dataset as an argument (since we are using TextLineDataset, each element will be a line of CSV text). Then we applydecode_csvto each of the lines. -
decode_csv: Splits each line into fields, providing the default values if necessary. Then returns a dict with the field keys and field values. The map function updates each elem (line) in the dataset with the dict.
That's an introduction to Datasets! Just for fun, we can now use this function to print the first batch:
next_batch = my_input_fn(FILE, True) # Will return 32 random elements
# Now let's try it out, retrieving and printing one batch of data.
# Although this code looks strange, you don't need to understand
# the details.
with tf.Session() as sess:
first_batch = sess.run(next_batch)
print(first_batch)
# Output
({'SepalLength': array([ 5.4000001, ...], dtype=float32),
'PetalWidth': array([ 0.40000001, ...], dtype=float32),
...
},
[array([[2], ...], dtype=int32) # Labels
)
That's actually all we need from the Dataset API to implement our model. Datasets have a lot more capabilities though; please see the end of this post where we have collected more resources.
Introducing Estimators
Estimators is a high-level API that reduces much of the boilerplate code you previously needed to write when training a TensorFlow model. Estimators are also very flexible, allowing you to override the default behavior if you have specific requirements for your model.
There are two possible ways you can build your model using Estimators:
- Pre-made Estimator - These are predefined estimators, created to generate a specific type of model. In this blog post, we will use the DNNClassifier pre-made estimator.
- Estimator (base class) - Gives you complete control of how your model should be created by using a model_fn function. We will cover how to do this in a separate blog post.
Here is the class diagram for Estimators:
We hope to add more pre-made Estimators in future releases.
As you can see, all estimators make use of input_fn that provides the estimator with input data. In our case, we will reuse my_input_fn, which we defined for this purpose.
The following code instantiates the estimator that predicts the Iris flower type:
# Create the feature_columns, which specifies the input to our model.
# All our input features are numeric, so use numeric_column for each one.
feature_columns = [tf.feature_column.numeric_column(k) for k in feature_names]
# Create a deep neural network regression classifier.
# Use the DNNClassifier pre-made estimator
classifier = tf.estimator.DNNClassifier(
feature_columns=feature_columns, # The input features to our model
hidden_units=[10, 10], # Two layers, each with 10 neurons
n_classes=3,
model_dir=PATH) # Path to where checkpoints etc are stored
We now have a estimator that we can start to train.
Training the model
Training is performed using a single line of TensorFlow code:
# Train our model, use the previously function my_input_fn
# Input to training is a file with training example
# Stop training after 8 iterations of train data (epochs)
classifier.train(
input_fn=lambda: my_input_fn(FILE_TRAIN, True, 8))
But wait a minute... what is this "lambda: my_input_fn(FILE_TRAIN, True, 8)" stuff? That is where we hook up Datasets with the Estimators! Estimators needs data to perform training, evaluation, and prediction, and it uses the input_fn to fetch the data. Estimators require aninput_fn with no arguments, so we create a function with no arguments using lambda, which calls our input_fn with the desired arguments: the file_path, shuffle setting, andrepeat_count. In our case, we use our my_input_fn, passing it:
-
FILE_TRAIN, which is the training data file. -
True, which tells the Estimator to shuffle the data. -
8, which tells the Estimator to and repeat the dataset 8 times.
Evaluating Our Trained Model
Ok, so now we have a trained model. How can we evaluate how well it's performing? Fortunately, every Estimator contains an evaluate method:
# Evaluate our model using the examples contained in FILE_TEST
# Return value will contain evaluation_metrics such as: loss & average_loss
evaluate_result = estimator.evaluate(
input_fn=lambda: my_input_fn(FILE_TEST, False, 4)
print("Evaluation results")
for key in evaluate_result:
print(" {}, was: {}".format(key, evaluate_result[key]))
In our case, we reach an accuracy of about ~93%. There are various ways of improving this accuracy, of course. One way is to simply run the program over and over. Since the state of the model is persisted (in model_dir=PATH above), the model will improve the more iterations you train it, until it settles. Another way would be to adjust the number of hidden layers or the number of nodes in each hidden layer. Feel free to experiment with this; please note, however, that when you make a change, you need to remove the directory specified inmodel_dir=PATH, since you are changing the structure of the DNNClassifier.
Making Predictions Using Our Trained Model
And that's it! We now have a trained model, and if we are happy with the evaluation results, we can use it to predict an Iris flower based on some input. As with training, and evaluation, we make predictions using a single function call:
# Predict the type of some Iris flowers.
# Let's predict the examples in FILE_TEST, repeat only once.
predict_results = classifier.predict(
input_fn=lambda: my_input_fn(FILE_TEST, False, 1))
print("Predictions on test file")
for prediction in predict_results:
# Will print the predicted class, i.e: 0, 1, or 2 if the prediction
# is Iris Sentosa, Vericolor, Virginica, respectively.
print prediction["class_ids"][0]
Making Predictions on Data in Memory
The preceding code specified FILE_TEST to make predictions on data stored in a file, but how could we make predictions on data residing in other sources, for example, in memory? As you may guess, this does not actually require a change to our predict call. Instead, we configure the Dataset API to use a memory structure as follows:
# Let create a memory dataset for prediction.
# We've taken the first 3 examples in FILE_TEST.
prediction_input = [[5.9, 3.0, 4.2, 1.5], # -> 1, Iris Versicolor
[6.9, 3.1, 5.4, 2.1], # -> 2, Iris Virginica
[5.1, 3.3, 1.7, 0.5]] # -> 0, Iris Sentosa
def new_input_fn():
def decode(x):
x = tf.split(x, 4) # Need to split into our 4 features
# When predicting, we don't need (or have) any labels
return dict(zip(feature_names, x)) # Then build a dict from them
# The from_tensor_slices function will use a memory structure as input
dataset = tf.contrib.data.Dataset.from_tensor_slices(prediction_input)
dataset = dataset.map(decode)
iterator = dataset.make_one_shot_iterator()
next_feature_batch = iterator.get_next()
return next_feature_batch, None # In prediction, we have no labels
# Predict all our prediction_input
predict_results = classifier.predict(input_fn=new_input_fn)
# Print results
print("Predictions on memory data")
for idx, prediction in enumerate(predict_results):
type = prediction["class_ids"][0] # Get the predicted class (index)
if type == 0:
print("I think: {}, is Iris Sentosa".format(prediction_input[idx]))
elif type == 1:
print("I think: {}, is Iris Versicolor".format(prediction_input[idx]))
else:
print("I think: {}, is Iris Virginica".format(prediction_input[idx])
Dataset.from_tensor_slices() is designed for small datasets that fit in memory. When using TextLineDataset as we did for training and evaluation, you can have arbitrarily large files, as long as your memory can manage the shuffle buffer and batch sizes.
Freebies
Using a pre-made Estimator like DNNClassifier provides a lot of value. In addition to being easy to use, pre-made Estimators also provide built-in evaluation metrics, and create summaries you can see in TensorBoard. To see this reporting, start TensorBoard from your command-line as follows:
# Replace PATH with the actual path passed as model_dir argument when the
# DNNRegressor estimator was created.
tensorboard --logdir=PATH
The following diagrams show some of the data that TensorBoard will provide:
Summary
In this this blogpost, we explored Datasets and Estimators. These are important APIs for defining input data streams and creating models, so investing time to learn them is definitely worthwhile!
For more details, be sure to check out
- The complete source code used in this blogpost is available here.
- Josh Gordon's excellent Jupyter notebook on the matter. Using that notebook, you will learn how to run a more extensive example that has many different types of features (inputs). As you recall from our model, we just used numeric features.
- For Datasets, see a new chapter in the Programmer's guide and reference documentation.
- For Estimators, see a new chapter in the Programmer's guide and reference documentation.
But it doesn't stop here. We will shortly publish more posts that describe how these APIs work, so stay tuned for that!
Until then, Happy TensorFlow coding!
原文来源:Google Developers Blog
作者:TensorFlow团队
在TensorFlow 1.3版本里面有两个重要的特征,你应该好好尝试一下:
•数据集(Datasets):一种创建输入流水线的全新方法(即将数据读取到程序中)。
•评估器(Estimator):一种创建TensorFlow模型的高级方法。评估器包括用于常见机器学习任务的预制模型,当然,你也可以使用它们来创建你的自定义模型。
接下来你将看到它们如何是如何适应TensorFlow架构的。如果将它们结合起来,它们将提供了一种创建TensorFlow模型并向其馈送数据的简单方法:
我们的示例模型
为了能够更好地对这些特征进行深一步探索,我们将构建一个模型并展示相关代码片段。点击此处链接,你将获得完整代码资源(https://github.com/mhyttsten/Misc/blob/master/Blog_Estimators_DataSet.py),其中包含关于训练和测试文件的说明。有一点需要注意的是,此代码只是为了演示数据集和评估器在功能方面的有效性,因此并未针对最大性能进行优化。
一个经过训练的模型根据四种植物特征(萼片长度、萼片宽度、花瓣长度和花瓣宽度)对鸢尾花进行分类。因此,在推理过程中,你可以为这四个特征提供值,并且该模型将预测出该花是以下三种美丽的变体之一:

从左至右:Iris setosa(山鸢尾,Radomil,CC BY-SA 3.0),Iris versicolor(杂色鸢尾,Dlanglois,CC BY-SA 3.0)和Iris virginica(维吉尼亚鸢尾,Frank Mayfield,CC BY-SA 2.0)。
我们将用下面的结构对一个深度神经网络分类器进行训练。所有输入和输出值都将为float32,输出值的和为1(正如我们所预测的每个单独鸢尾花类型的概率):

例如,一个输出结果是Iris Setosa(山鸢尾)的概率为0.05,是Iris Versicolor(杂色鸢尾)的概率为0.9,是Iris Virginica(维吉尼亚鸢尾)的概率为0.05,这表明该花是Iris Versicolor(杂色鸢尾)的概率为90%。
好的!既然我们已经定义了这个模型,接下来就看一下该如何使用Datasets(数据集)和Estimator(评估器)对其进行训练并做出预测。
Datasets(数据集)的简介
Dataset是一种为TensorFlow模型创建输入流水线的新方式。相较于使用feed_dict或基于队列的流水线,这个API要好用得多,而且它更干净,更易于使用。虽然在1.3版本中,Datasets仍然位于tf.contrib.data中,但我们希望将该API移动到1.4版本中,所以现在是对其进行测试驱动器的时候了。
在高级别中,Dataset涵盖以下几级:
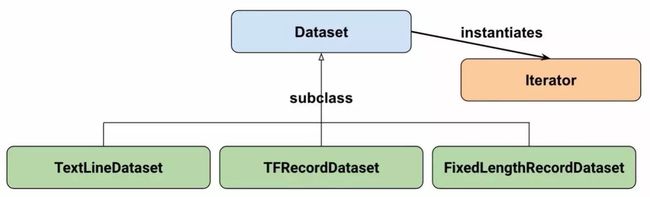
其中:
•Dataset:包含创建和转换数据集方法的基类。还使得你能够对内存中或来自Python生成器的数据初始化数据集。
•TextLineDataset:从文本文件中读取行。
•TFRecordDataset:读取TFRecord文件中的记录。
•FixedLengthRecordDataset:从二进制文件读取固定大小的记录。
•Iterator(迭代器):提供一种一次访问一个数据集元素的方法。
我们的数据集
首先,我们先来看看那些将用来馈送模型的数据集。我们将从CSV文件中读取数据,其中每行将包含五个值——四个输入值以及标签:

标签将是:
0为Iris Setosa(山鸢尾);
1为Versicolor(杂色鸢尾);
2为Virginica(维吉尼亚鸢尾)
表征数据集
为了描述我们的数据集,我们首先创建一个关于特征的列表:
feature_names = [
'SepalLength',
'SepalWidth',
'PetalLength',
'PetalWidth']
当训练模型时,我们需要一个读取输入文件并返回特征和标签数据的函数。Estimators(评估器)要求你按照以下格式创建一个函数:
def input_fn():
......
return ({ 'SepalLength':[values], ...., 'PetalWidth':[values] },
[IrisFlowerType])
返回值必须是一个双元素元组,其组织如下:
•第一个元素必须是一个dict(命令),其中每个输入特征都是一个键,然后是训练批量的值列表。
•第二个元素是训练批量的标签列表。
由于我们返回了一批输入特征和训练标签,所以这意味着返回语句中的所有列表将具有相同的长度。从技术上说,每当我们在这里提到“列表”时,实际上指的是一个1-d TensorFlow张量。
为了使得能够重用input_fn,我们将添加一些参数。从而使得我们能够用不同的设置构建输入函数。这些配置是很简单的:
file_path:要读取的数据文件。
perform_shuffle:记录顺序是否应该是随机的。
repeat_count:迭代数据集中记录的次数。例如,如果我们指定1,则每个记录将被读取一次。如果我们指定None,则迭代将永远持续下去。
以下是使用Dataset API实现此函数的方法。我们将把它封装在一个“输入函数”中,它将与我们馈送评估器模型相适应。
def my_input_fn(file_path, perform_shuffle=False, repeat_count=1):
def decode_csv(line):
parsed_line = tf.decode_csv(line, [[0.], [0.], [0.], [0.], [0]])
label = parsed_line[-1:] # Last element is the label
del parsed_line[-1] # Delete last element
features = parsed_line # Everything (but last element) are the features
d = dict(zip(feature_names, features)), label
return d
dataset = (tf.contrib.data.TextLineDataset(file_path) # Read text file
.skip(1) # Skip header row
.map(decode_csv)) # Transform each elem by applying decode_csv fn
if perform_shuffle:
# Randomizes input using a window of 256 elements (read into memory)
dataset = dataset.shuffle(buffer_size=256)
dataset = dataset.repeat(repeat_count) # Repeats dataset this # times
dataset = dataset.batch(32) # Batch size to use
iterator = dataset.make_one_shot_iterator()
batch_features, batch_labels = iterator.get_next()
return batch_features, batch_labels
请注意以下事项:
TextLineDataset:当你使用其基于文件的数据集时,Dataset API将为你处理大量的内存管理。例如,你可以通过指定列表作为参数,读取比内存大得多的数据集文件或读入多个文件。
Shuffle(随机化):读取buffer_size记录,然后shuffle(随机化)其顺序。
Map(映射):将数据集中的每个元素调用decode_csv函数,作为参数(因为我们使用的是TextLineDataset,每个元素都将是一行CSV文本)。然后我们将decode_csv应用于每一行。
decode_csv:将每行拆分为字段,如有必要,提供默认值。然后返回一个带有字段键和字段值的dict(命令)。映射函数使用dict更新数据集中的每个elem(行)。
当然,以上只是对Datasets的粗略介绍!接下来,我们可以使用此函数打印第一个批次:
next_batch = my_input_fn(FILE, True) # Will return 32 random elements
# Now let's try it out, retrieving and printing one batch of data.
# Although this code looks strange, you don't need to understand
# the details.
with tf.Session() as sess:
first_batch = sess.run(next_batch)
print(first_batch)
# Output
({'SepalLength': array([ 5.4000001, ...], dtype=float32),
'PetalWidth': array([ 0.40000001, ...], dtype=float32),
...
},
[array([[2], ...], dtype=int32) # Labels
)
实际上,我们需要从Dataset API中实现我们的模型。Datasets具有更多的功能,详情请看这篇文章的结尾,我们收集了更多的资源。
Estimators(评估器)的介绍
Estimator是一种高级API,在训练TensorFlow模型时,它可以减少以前需要编写的大量样板代码。Estimator也非常灵活,如果你对模型有特定要求,它使得你能够覆盖其默认行为。
下面介绍两种可能的方法,你可以用来用Estimator构建模型:
•Pre-made Estimator(预制评估器)——这些是预定义的评估器,用于生成特定类型的模型。在这篇文章中,我们将使用DNNClassifier预制评估器。
•Estimator(基础级别)——通过使用model_fn函数,你可以完全控制如何创建模型。我们将在另一篇文章中对其详细介绍。
以下是评估器的类图:

我们希望在将来的版本中添加更多的预制评估器。
你可以看到,所有的评估器都使用input_fn来提供输入数据。在我们的示例中,我们将重用我们为此定义的my_input_fn。
以下代码实例化了预测鸢尾花类型的评估器:
# Create the feature_columns, which specifies the input to our model.
# All our input features are numeric, so use numeric_column for each one.
feature_columns = [tf.feature_column.numeric_column(k) for k in feature_names]
# Create a deep neural network regression classifier.
# Use the DNNClassifier pre-made estimator
classifier = tf.estimator.DNNClassifier(
feature_columns=feature_columns, # The input features to our model
hidden_units=[10, 10], # Two layers, each with 10 neurons
n_classes=3,
model_dir=PATH) # Path to where checkpoints etc are stored
我们现在有一个评估器,我们可以开始训练了。
训练模型
使用单行TensorFlow代码进行训练:
# Train our model, use the previously function my_input_fn
# Input to training is a file with training example
# Stop training after 8 iterations of train data (epochs)
classifier.train(
input_fn=lambda: my_input_fn(FILE_TRAIN, True, 8))
但等一下... "lambda: my_input_fn(FILE_TRAIN, True, 8)"这是什么东西?这就是我们用评估器连接数据集的地方!评估器需要数据来执行训练、评估和预测,并且使用input_fn来获取数据。评估器需要一个没有参数的input_fn,所以我们使用lambda创建一个没有参数的函数,它使用所需的参数调用input_fn:file_path、shuffle setting和repeat_count。在我们的示例中,我们使用my_input_fn,传递它:
•FILE_TRAIN,它是训练数据文件。
•True,这告诉评估器shuffle数据。
•8,它告诉评估器并重复数据集8次。
评估我们训练过的模型
好的,现在我们有一个训练过的模型。我们如何评估它的表现呢?幸运的是,每个评估器都包含一个评估方法:
# Evaluate our model using the examples contained in FILE_TEST
# Return value will contain evaluation_metrics such as: loss & average_loss
evaluate_result = estimator.evaluate(
input_fn=lambda: my_input_fn(FILE_TEST, False, 4)
print("Evaluation results")
for key in evaluate_result:
print(" {}, was: {}".format(key, evaluate_result[key]))
在我们的示例中,准确度能达到93%。当然有各种各样的方式来提高这个准确性。一种方法是一遍又一遍地运行程序。由于模型的状态是持久的(在上面的model_dir = PATH中),模型将会改进你对其进行的迭代次数的更改,直到它稳定为止。另一种方法是调整隐藏层数或每个隐藏层中的节点数。随意尝试一下,但请注意,当你进行更改时,你需要删除model_dir = PATH中指定的目录,因为你正在更改DNNClassifier的结构。
使用我们训练过模型进行预测
就是这样!我们现在有一个训练过的模型,如果我们对评估结果感到满意,我们可以使用它来基于一些输入来预测鸢尾花。与训练和评估一样,我们使用单个函数调用进行预测:
# Predict the type of some Iris flowers.
# Let's predict the examples in FILE_TEST, repeat only once.
predict_results = classifier.predict(
input_fn=lambda: my_input_fn(FILE_TEST, False, 1))
print("Predictions on test file")
for prediction in predict_results:
# Will print the predicted class, i.e: 0, 1, or 2 if the prediction
# is Iris Sentosa, Vericolor, Virginica, respectively.
print prediction["class_ids"][0]
在内存中对数据进行预测
前面的代码指定了FILE_TEST以对存储在文件中的数据进行预测,但是我们如何对驻留在其他来源的数据进行预测,例如在内存中?你可能会猜到,这并不需要改变我们的预测调用。相反,我们将Dataset API配置为使用记忆结构,如下所示:
# Let create a memory dataset for prediction.
# We've taken the first 3 examples in FILE_TEST.
prediction_input = [[5.9, 3.0, 4.2, 1.5], # -> 1, Iris Versicolor
[6.9, 3.1, 5.4, 2.1], # -> 2, Iris Virginica
[5.1, 3.3, 1.7, 0.5]] # -> 0, Iris Sentosa
def new_input_fn():
def decode(x):
x = tf.split(x, 4) # Need to split into our 4 features
# When predicting, we don't need (or have) any labels
return dict(zip(feature_names, x)) # Then build a dict from them
# The from_tensor_slices function will use a memory structure as input
dataset = tf.contrib.data.Dataset.from_tensor_slices(prediction_input)
dataset = dataset.map(decode)
iterator = dataset.make_one_shot_iterator()
next_feature_batch = iterator.get_next()
return next_feature_batch, None # In prediction, we have no labels
# Predict all our prediction_input
predict_results = classifier.predict(input_fn=new_input_fn)
# Print results
print("Predictions on memory data")
for idx, prediction in enumerate(predict_results):
type = prediction["class_ids"][0] # Get the predicted class (index)
if type == 0:
print("I think: {}, is Iris Sentosa".format(prediction_input[idx]))
elif type == 1:
print("I think: {}, is Iris Versicolor".format(prediction_input[idx]))
else:
print("I think: {}, is Iris Virginica".format(prediction_input[idx])
Dataset.from_tensor_slices()专为适合内存的小型数据集而设计。当我们使用TextLineDataset进行训练和评估时,你可以拥有任意大的文件,只要你的内存可以管理随机缓冲区和批量大小。
使用像DNNClassifier这样的预制评估器提供了很多价值。除了易于使用,预制评估器还提供内置的评估指标,并创建可在TensorBoard中看到的概要。要查看此报告,请从你的命令行启动TensorBoard,如下所示:
# Replace PATH with the actual path passed as model_dir argument when the
# DNNRegressor estimator was created.
tensorboard --logdir=PATH
下面的图显示了一些tensorboard将提供数据:

概要
在这篇文章中,我们探讨了数据集和评估器。这些是用于定义输入数据流和创建模型的重要API,因此投入时间来学习它们是绝对值得的!
有关更多详情,请务必查看:
•此文中使用的完整源代码可在此处获取。(https://goo.gl/PdGCRx)
•Josh Gordon的Jupyter notebook的出色使用。(https://github.com/tensorflow/workshops/blob/master/notebooks/07_structured_data.ipynb)使用Jupyter notebook,你将学习如何运行一个更广泛的例子,其具有许多不同类型的特征(输入)。从我们的模型来看,我们只使用了数值特征。
•有关数据集,请参阅程序员指南(https://www.tensorflow.org/programmers_guide/datasets)和参考文档(https://www.tensorflow.org/api_docs/python/tf/contrib/data)中的新章节。
•有关评估器,请参阅程序员指南(https://www.tensorflow.org/programmers_guide/estimators)和参考文档(https://www.tensorflow.org/versions/master/api_docs/python/tf/estimator)中的新章节。
原文: 关于TensorFlow 1.3的Datasets和Estimator,你了解多少?谷歌大神来解答
原文: Google Developers Blog: Introduction to TensorFlow Datasets and Estimators