前言
在上一篇“5分钟Serverless实践”系列文章中,我们介绍了什么是Serverless,以及如何构建一个无服务器的图片鉴黄Web应用,本文将延续这个话题,以敏感词过滤为例,介绍如何构建一个无服务器API,即无服务器的后端系统。
函数工作流
函数工作流(FunctionGraph,FGS)是一项基于事件驱动的函数托管计算服务,托管函数具备以毫秒级弹性伸缩、免运维、高可靠的方式运行。通过函数工作流,开发者无需配置和管理服务器,只需关注业务逻辑,编写函数代码,以无服务器的方式构建应用,便能开发出一个弹性高可用的后端系统,并按实际运行消耗的资源计费。极大地提高了开发和运维效率,减小了运作成本。
相比于传统的架构,函数工作流构建的无服务器架构具有如下优点:
1.无需关注任何服务器,只需关注核心业务逻辑,提高开发和运维效率
2.函数运行随业务量弹性伸缩,按需付费,执行才计费,对于负载波峰波谷非常明显的场景可以减少大量成本
3.通过简单的配置即可连通函数工作流和其它各云服务,甚至云服务和云服务
构建无服务器的敏感词过滤后端系统
为了进一步让大家感受函数工作流的优势,我们将介绍如何通过函数工作流快速构建一个无服务器的敏感词过滤系统,本文我们主要关注后端系统,前端的表现形式很多,大家可以自行构建。如下图,该系统会识别用户上传的文本内容是否包含敏感信息(如×××、政治等),并对这些词语进行过滤。
●试想,如果我们通过传统的模式开发此应用,需要如何开发?即使是基于现在的云平台,我们也仍需要购买云服务器,关注其规格、镜像、网络等各指标的选型和运维,然后在开发过程中可能还需要考虑与其他云服务的集成使用问题,使代码中耦合大量非业务代码,并且服务器等资源也并非是按需的,特别是对于访问量波峰波谷非常明显的场景,会造成大量多余的费用。
现在我们可以通过函数工作流服务来快速构建这个系统,并且完全无需关注服务器,且弹性伸缩运行、按需计费,如图: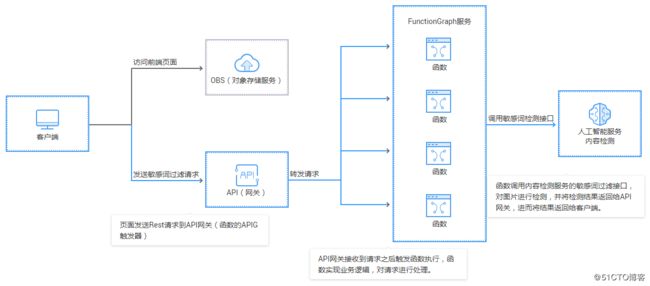
创建函数,在函数中调用华为云内容检测服务提供的文本检测接口,实现文本的敏感词检测,并为该函数配置一个APIG触发器,这样便可以对外提供一个敏感词过滤的API,从而构建出一个完整的敏感词过滤的无服务器后端系统。客户端调用API,他会自动触发函数执行,而开发者编写的函数只需实现接收到文本之后如何处理文本的逻辑即可,最后将结果返回给客户端。至此,我们就构建了一个完整的无服务器敏感词过滤后端系统。
接下来,我们将介绍如何完整地将此无服务器后端系统构建出来。
1.准备工作
进入华为云内容检测服务,申请开通文本内容检测,成功申请后便可以调用内容检测服务提供的文本检测接口了。
2.创建函数
进入函数工作流服务页面,创建函数,实现文本检测的接口调用和敏感词过滤,代码如下:
# -*- coding:utf-8 -*-
import json
import base64
import urllib
import urllib2
import ssl
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def do_filter(msg,str_list):
result = ''
try:
if len(str_list) <=0:
return msg
for str in str_list:
str_tmp = msg.replace(str,'')
msg = str_tmp
result = msg
except:
print("_do_filter catch an exception!")
return result
def filter(context, msg):
result = ''
try:
ssl._create_default_https_context = ssl._create_unverified_context
token = context.getToken();
headers = {'Content-Type':'application/json;charset=utf8','X-Auth-Token':token}
url = "https://ais.cn-north-1.myhwclouds.com/v1.0/moderation/text"
values = {}
values['categories'] = ['porn','ad','politics','abuse','contraband']
#msg = base64.b64encode(msg)
item = {'type':'content','text':msg}
values['items'] = [item]
data = json.dumps(values)
print("data: %s"%data)
request = urllib2.Request(url,data,headers)
rsp = urllib2.urlopen(request)
http_rsp = rsp.read()
print("http response: %s" %http_rsp)
json_rsp = json.loads(http_rsp)
result = json_rsp['result']
suggestion = result['suggestion']
if suggestion == 'pass':
print("input msg have passed the checking!")
result = msg
else:
detail = result['detail']
if detail.has_key('porn'):
list_porn = detail['porn']
msg = do_filter(msg,list_porn)
if detail.has_key('ad'):
list_ad = detail['ad']
msg = do_filter(msg,list_ad)
if detail.has_key('politics'):
list_politics = detail['politics']
msg = do_filter(msg,list_politics)
if detail.has_key('abuse'):
list_abuse = detail['abuse']
msg = do_filter(msg,list_abuse)
if detail.has_key('contraband'):
list_contraband = detail['contraband']
msg = do_filter(msg,list_contraband)
result = msg
except Exception, e:
print e
print("filter catch an exception!")
return result
def handler (event, context):
print("message filter begin!")
result = ""
response = {}
http_method = event.get('httpMethod')
if http_method == 'OPTIONS':
response = {
'statusCode': 200,
'isBase64Encoded': True,
'headers': {
"Content-Type": "application/json; charset=utf-8",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Headers": "Content-Type,Accept",
"Access-Control-Allow-Methods": "GET,POST,PUT,DELETE"
},
'body': base64.b64encode('{"result":'+ '"' + result +'"}'),
}
return response
body = event.get('body')
body_decode = base64.b64decode(body)
json_object = json.loads(body_decode)
msg = json_object['msg']
print('msg : %s'%msg)
try:
result = filter(context, msg)
response = {
'statusCode': 200,
'isBase64Encoded': True,
'headers': {
"Content-Type": "application/json; charset=utf-8",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Headers": "Content-Type,Accept",
"Access-Control-Allow-Methods": "GET,POST,PUT,DELETE"
},
'body': base64.b64encode('{"result":'+ '"' + result +'"}'),
}
except:
print("function catch an exception!")
return response
函数创建完成之后,为其配置具有IAM访问权限的委托,因为本函数代码中获取用户的ak、sk需要拥有访问IAM的权限。
3.创建APIG触发器
为函数配置一个APIG触发器,这样便得到一个调用该函数的HTTP(S) API,供外部调用。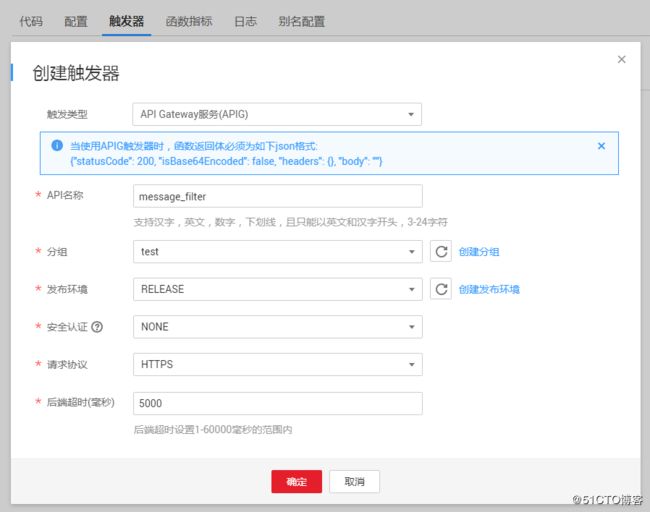
创建成功后,API的URL可以在函数详情页面的“触发器”栏看到: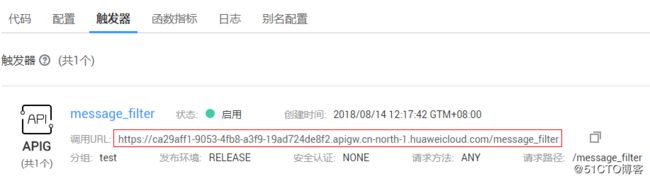
4.测试
使用postman等工具向上一步中创建的APIG触发器的接口发送post请求,body体为:{“msg”: “过滤检测的文本”},查看返回信息。
比如发送 {"msg": "just fuck ..."}, 返回体为 {"result": "just ..."}
至此,我们就完整地构建了一个无服务器的敏感词过滤后端系统。