cdh5.14.2中集成安装kylin与使用测试
标签(空格分隔): 大数据平台构建
- 一:kylin 简介
- 二:安装配置kylin
- 三:kylin 运行实例
一:kylin 简介
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。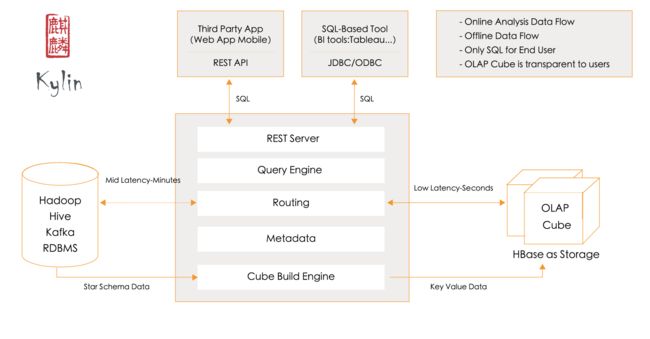
kylin 软件下载:
社区版kylin下载地址:https://archive.apache.org/dist/kylin/ ,本次测试使用apache-kylin-2.3.1.tar.gz 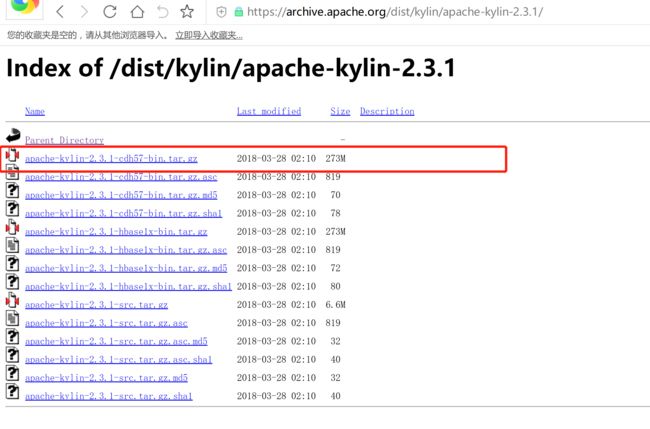
二:在cdh5.14.2 上面配置安装kylin
2.1: kylin 安装的环境配置
login: node-01.flyfish
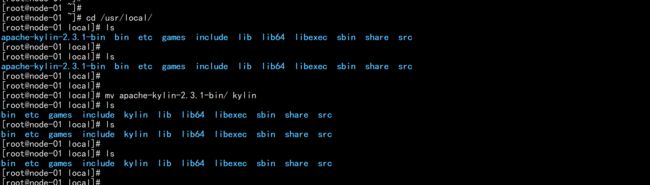
tar -zxvf apache-kylin-2.3.1-cdh57-bin.tar.gz -C /usr/local/
cd /usr/local/
mv apache-kylin-2.3.1-bin/ kylin
vim /etc/profile
----
### kylin ####
export KYLIN_HOME=/usr/local/kylin
PATH=$PATH:$HOME/bin:$KYLIN_HOME/bin
---
source /etc/profile
2.2:kylin的启动验证
cd /usr/local/kylin/
./check-env.sh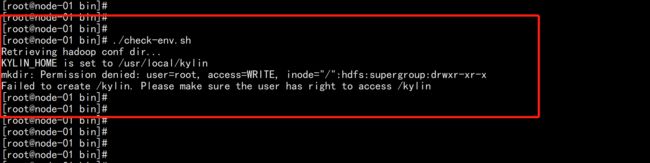
su - hdfs
hdfs dfs -chmod -R 777 /
从新检测处理
cd /usr/local/kylin/
./check-env.sh
启动kylin
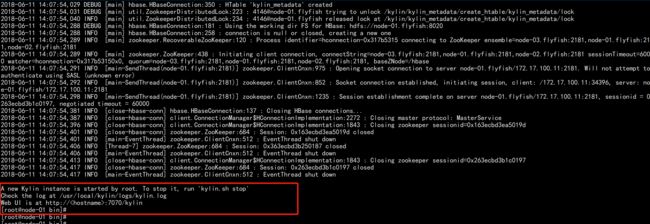
./kylin.sh start 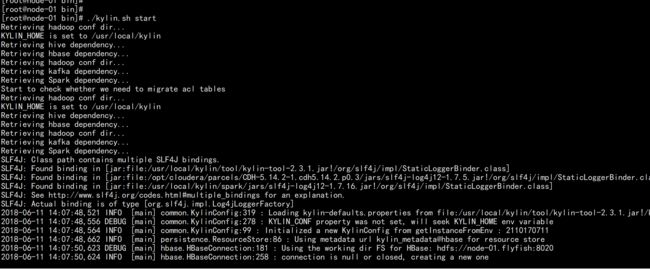
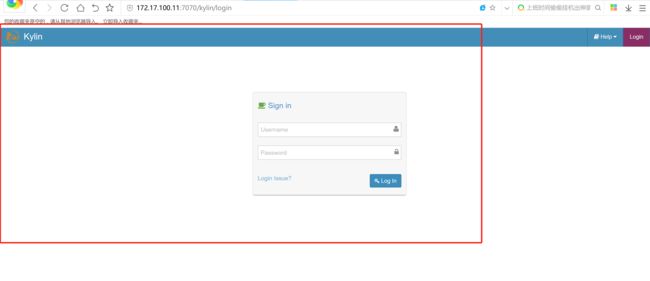
默认用户名:ADMIN
密码:KYLIN
三:kylin 运行实例使用测试
cd /usr/local/kylin/bin
./sample.sh
从启kylin
cd /usr/local/kylin/bin
./kylin.sh stop
./kylin.sh start

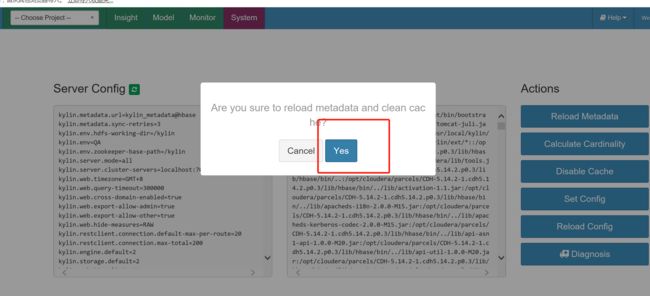
重新刷新kylin的元数据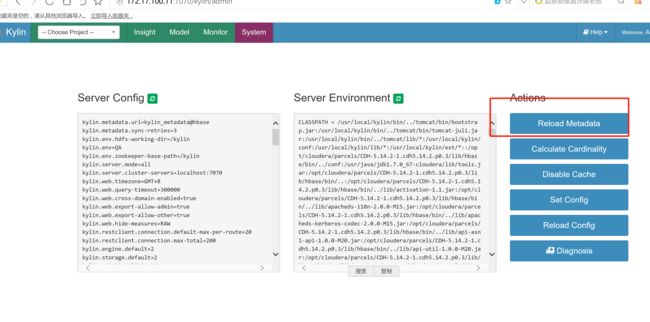
impala的加载表:
impala-shell -i "INVALIDATE METADATA"
单独刷新一张表:
refrash + 表名
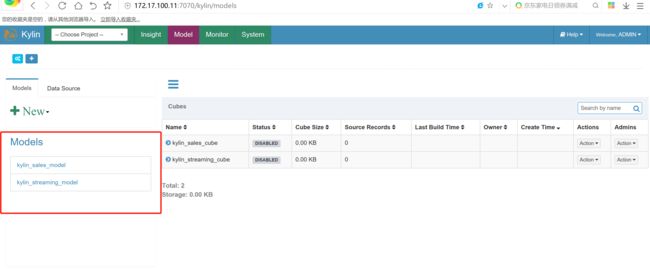
hive 的default库 当中多了几张kylin的表
构建cube 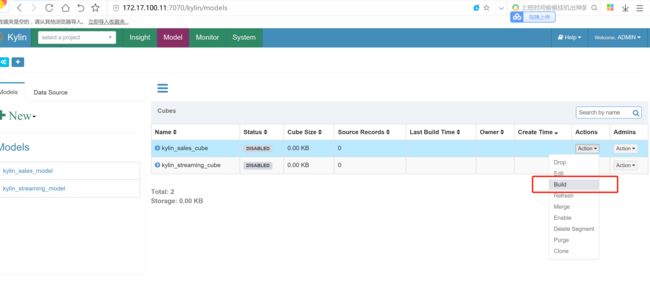

这个地方如果机器配置不够的话,尽量日期间隔选小一点。
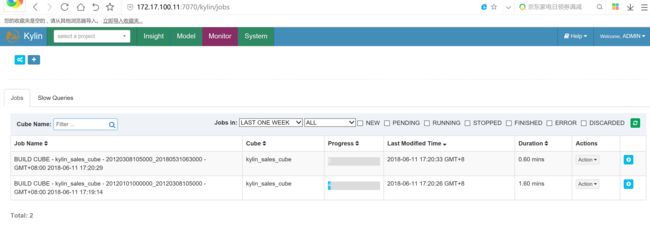
这一步会比较耗时,因为这步会进行预计算,默认是MapReduce作业。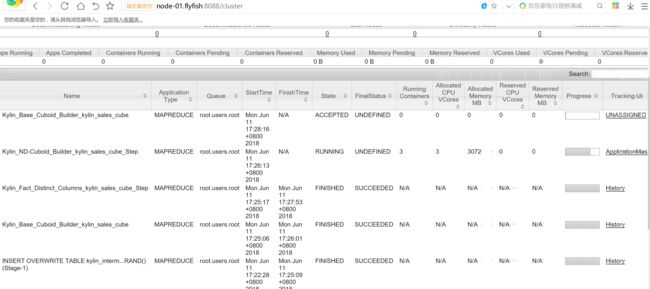
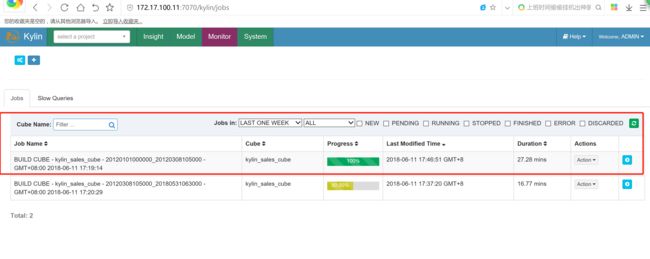
kylin的数据查询
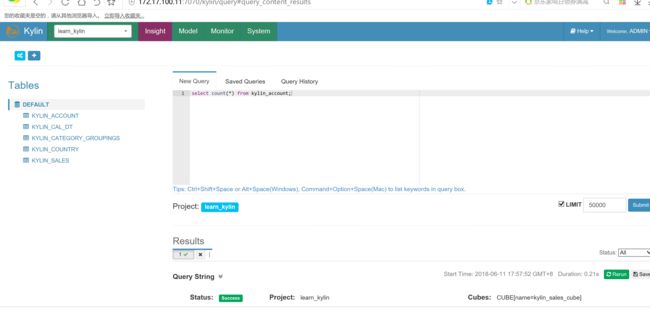
查询构建完成的cube
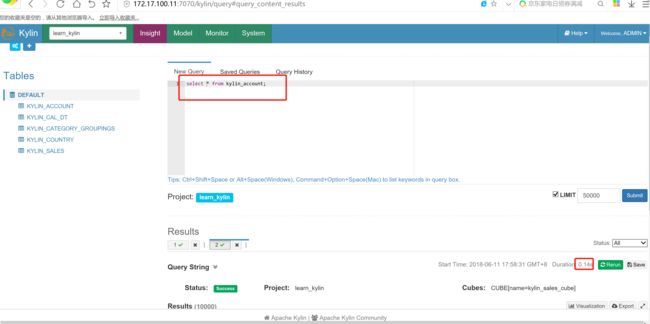
先运行简单的count,可以看到耗时4.12s,再次执行基本在0.5s级,基本是毫秒级别
就可以查询出来,这是因为kylin 支持缓存的功能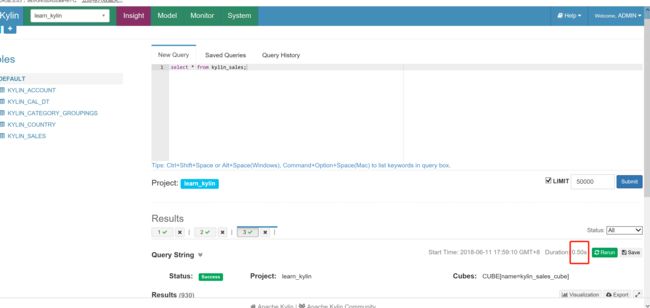
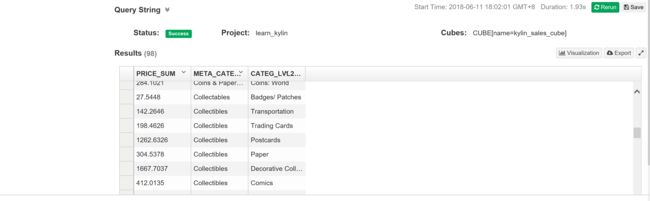
复杂的查询:
select sum(KYLIN_SALES.PRICE)
as price_sum,KYLIN_CATEGORY_GROUPINGS.META_CATEG_NAME,KYLIN_CATEGORY_GROUPINGS.CATEG_LVL2_NAME
from KYLIN_SALES inner join KYLIN_CATEGORY_GROUPINGS
on KYLIN_SALES.LEAF_CATEG_ID = KYLIN_CATEGORY_GROUPINGS.LEAF_CATEG_ID and
KYLIN_SALES.LSTG_SITE_ID = KYLIN_CATEGORY_GROUPINGS.SITE_ID
group by KYLIN_CATEGORY_GROUPINGS.META_CATEG_NAME,KYLIN_CATEGORY_GROUPINGS.CATEG_LVL2_NAME
order by KYLIN_CATEGORY_GROUPINGS.META_CATEG_NAME asc,KYLIN_CATEGORY_GROUPINGS.CATEG_LVL2_NAME desc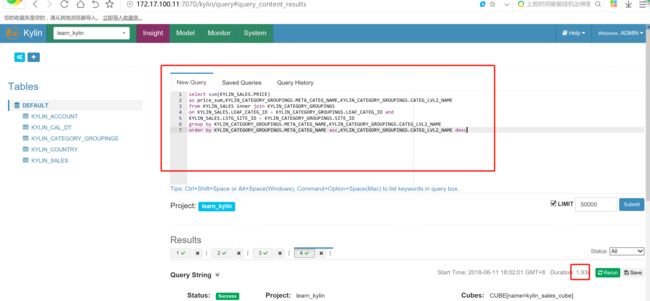
四:kylin 运行实例二
4.1 数据文件准备
create_table.sql department.csv employee.csv
4.2 在hdfs 上面创建文件上传
在hdfs 上面创建上传目录
hdfs dfs -mkdir /kylin-test
hdfs dfs -put department.csv employee.csv /kylin-test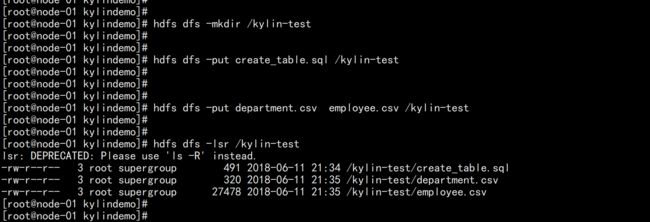
4.3 在hive 上面执行sql 脚本加载数据与验证
执行create_table.sql
create_table 内容如下
---
DROP TABLE IF EXISTS employee;
CREATE TABLE employee(
id int,
name string,
deptId int,
age int,
salary float
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
DROP TABLE IF EXISTS department;
CREATE TABLE department(
id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
LOAD DATA INPATH '/kylin-test/employee.csv' OVERWRITE INTO TABLE employee;
LOAD DATA INPATH '/kylin-test/department.csv' OVERWRITE INTO TABLE department;
---在hive 中执行create_table.sql
hive -f create_table.sql 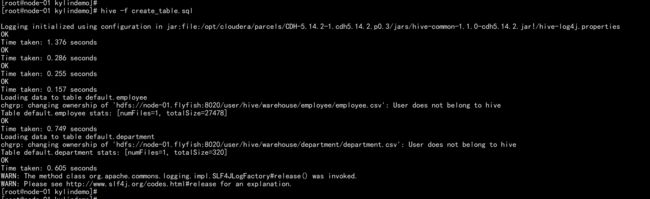
hive -e "use default;select * from employee"
hive -e "use default;select * from department" 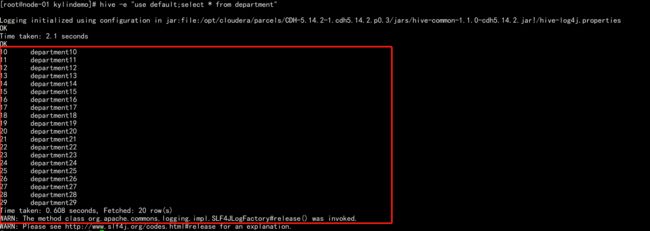
4.4 在kylin 上面创建project
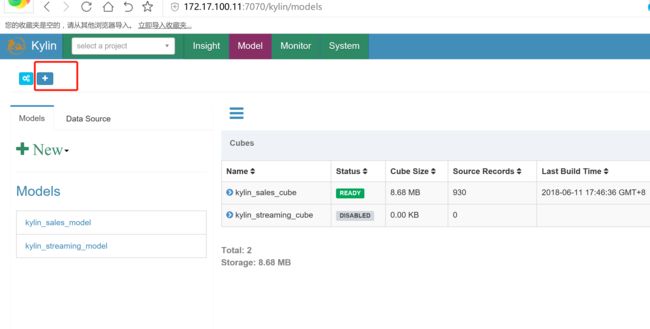
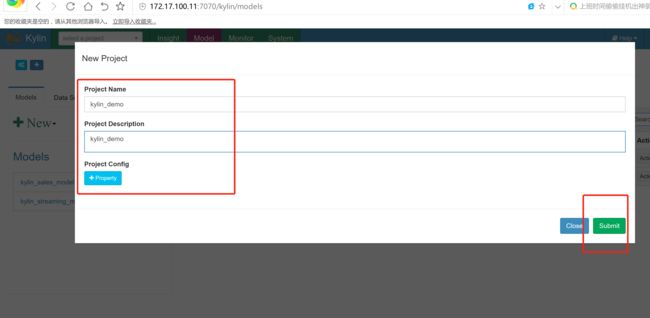

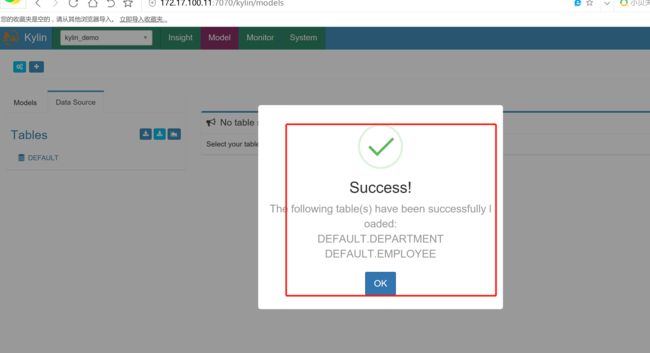
加载hive数据到kylin当中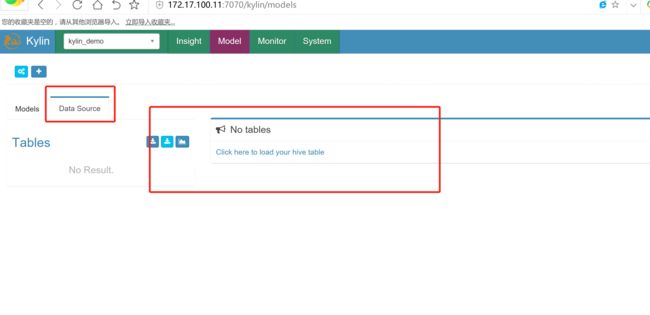


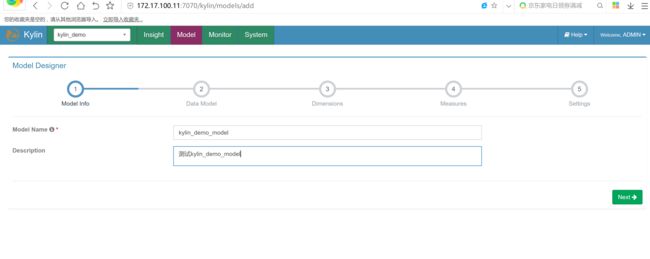
创建model,入project的名称和描述:
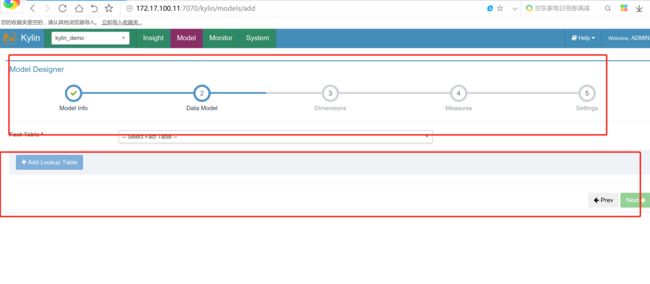


选择事实表,并点击add Lookup Table查询表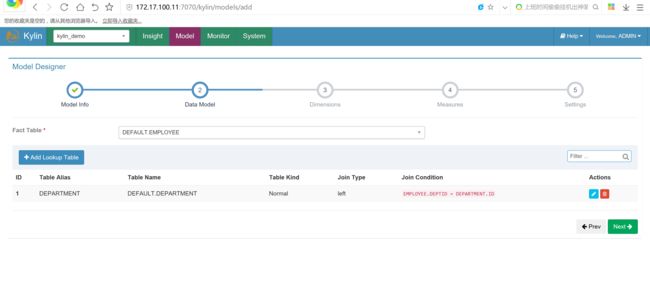
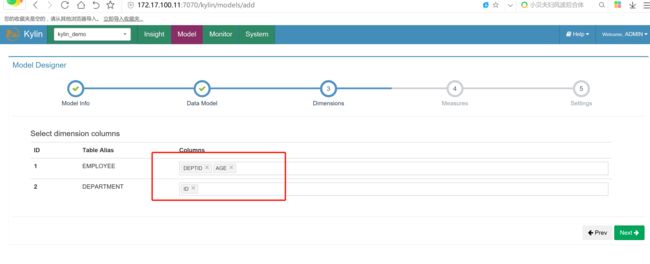
选择维度字段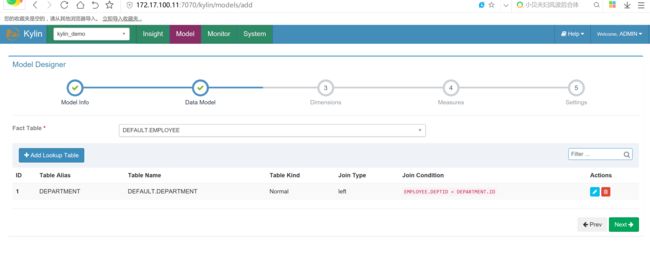
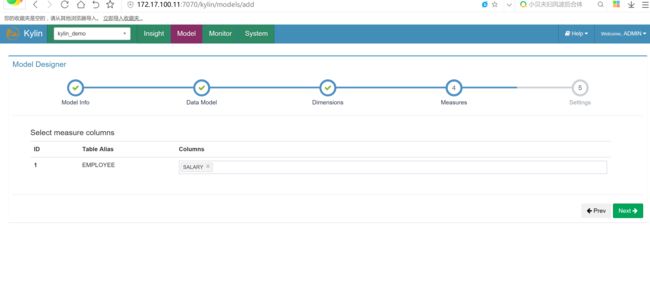
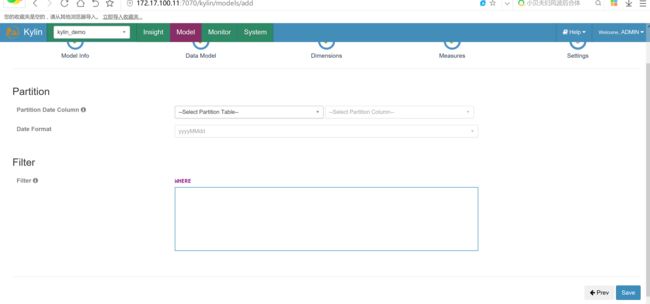
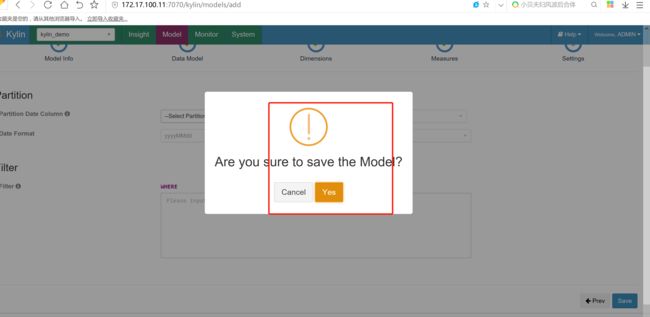
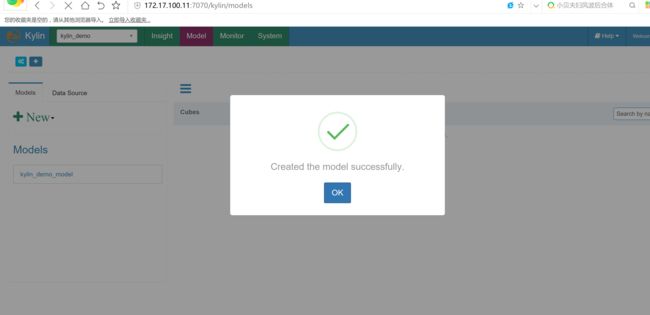
创建cube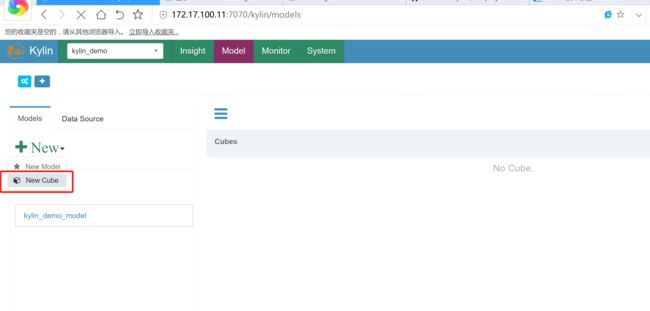
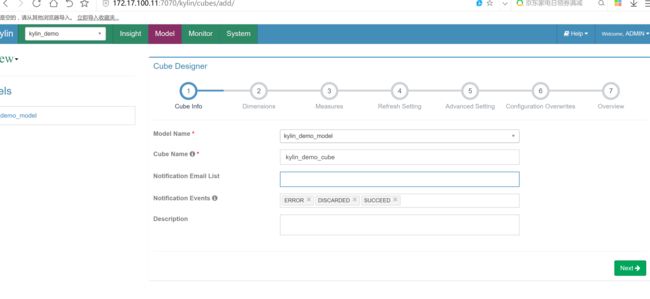
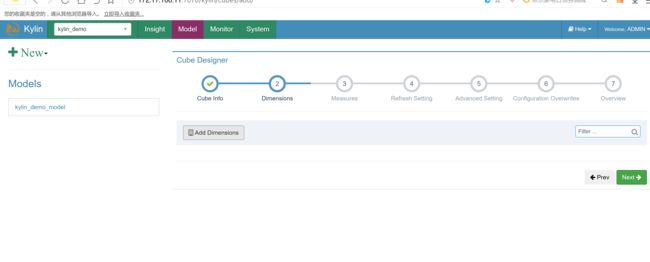
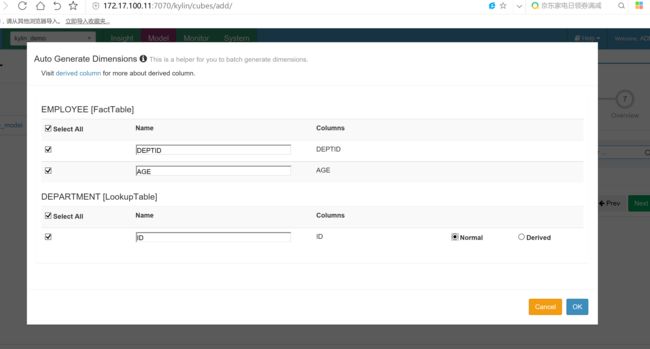
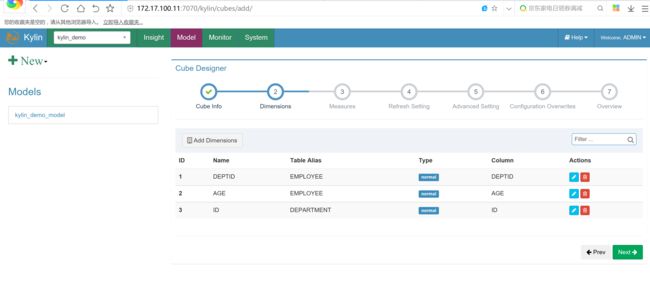

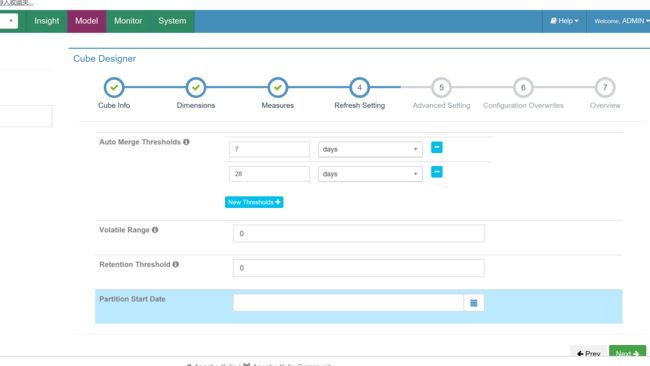
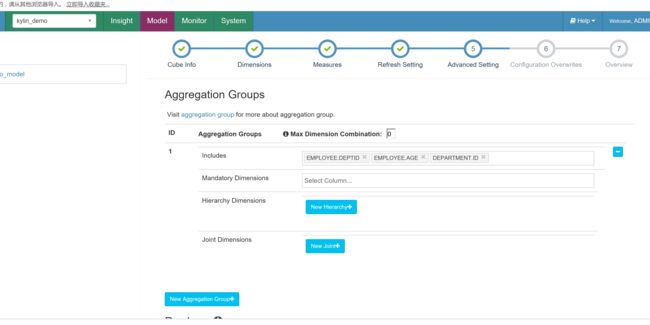
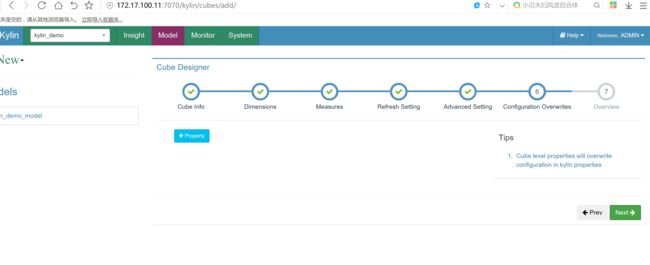
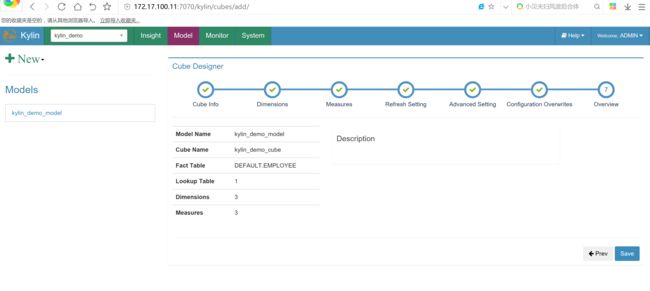
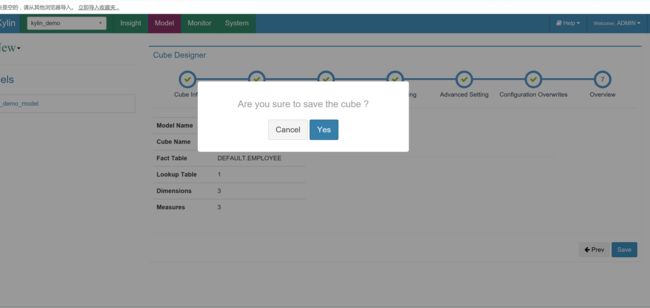

cube创建完成
构建cube


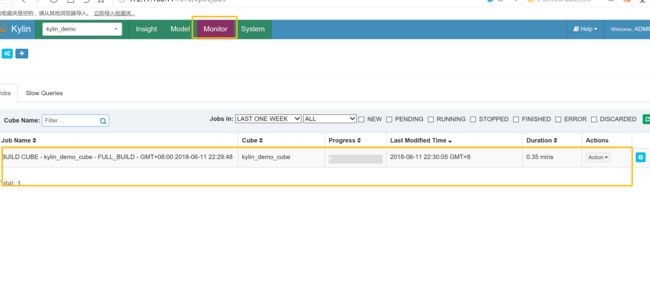
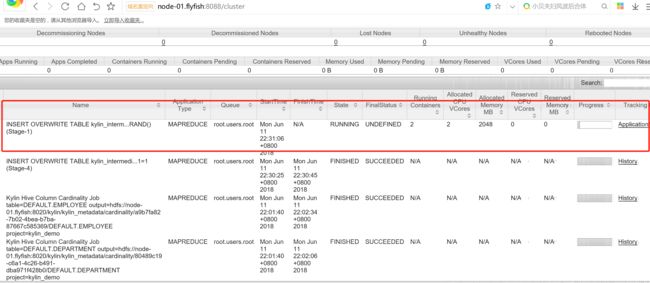
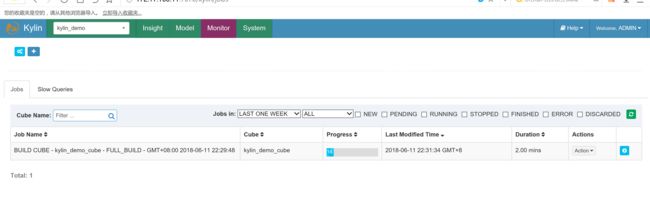
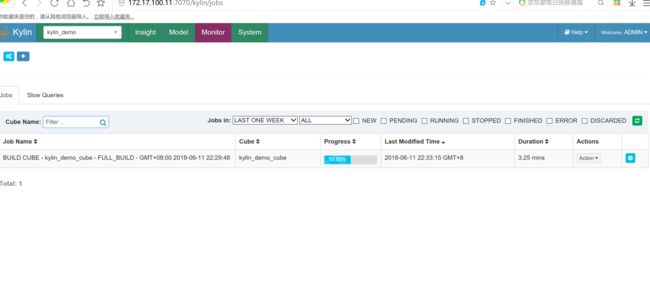
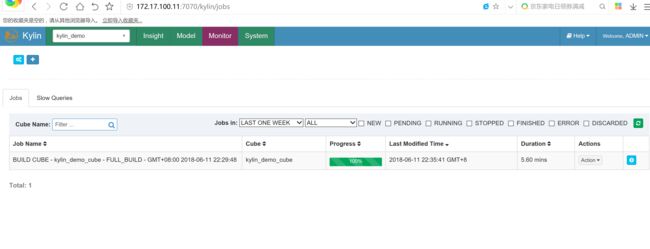
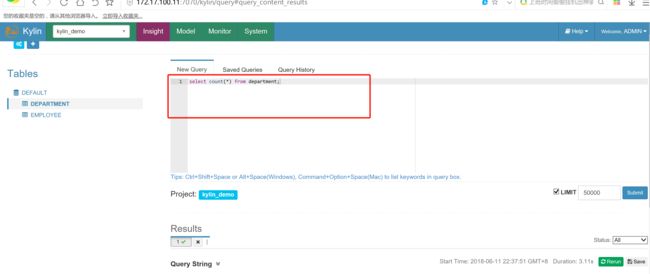
查询测试:
select count(*) from department;
select max(salary) from EMPLOYEE;
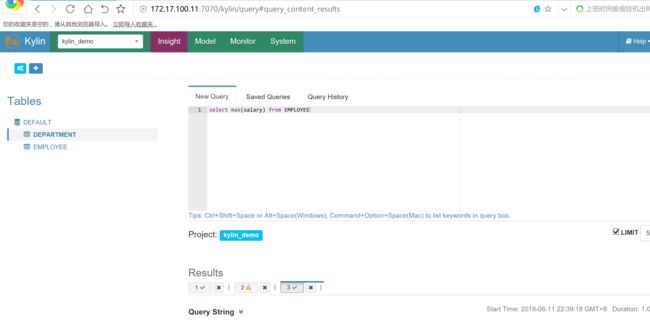
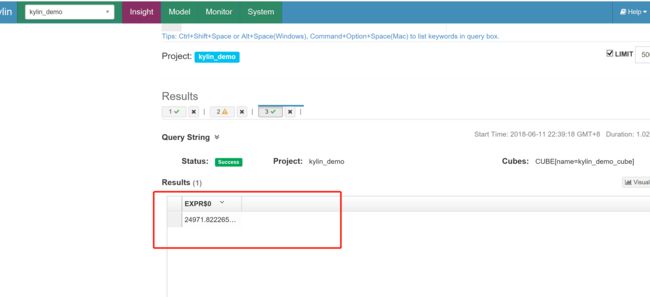
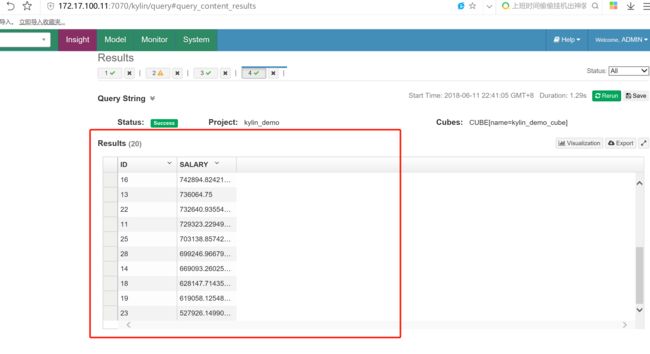
统计各部门员工薪资总和:
select d.ID,sum(e.SALARY) as salary from EMPLOYEE as e left join DEPARTMENT as d on e.DEPTID=d.id group by d.ID order by salary desc