一、 安装环境介绍
这个实例要介绍的是web+mysql集群的构建,整个RHCS集群共有四台服务器组成,分别由两台主机搭建web集群,两台主机搭建mysql集群,在这种集群构架下,任何一台web服务器故障,都有另一台web服务器进行服务接管,同时,任何一台mysql服务器故障,也有另一台mysql服务器去接管服务,保证了整个应用系统服务的不间断运行。如下图所示:
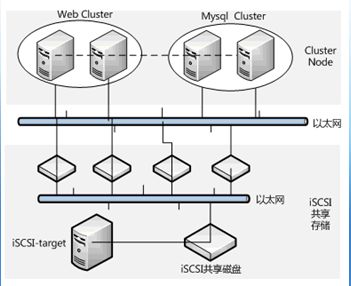
二、 安装前准备工作
Centos是RHEL的克隆版本,并且RHCS所有功能组件都免费提供,因此下面的讲述以Centos为准。
操作系统:统一采用Centos5.3版本。为了方便安装RHCS套件,在安装操作系统时,建议选择如下这些安装包:
桌面环境:xwindows system、GNOME desktop environment。
开发工具:development tools、x software development、gnome software development、kde software development。
地址规划如下:
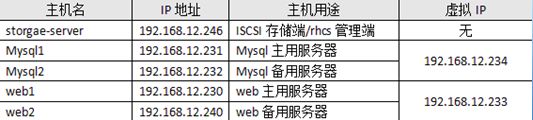
iSCSI-target的安装与使用已经在前面文章中做过介绍,不再讲述,这里假定共享的磁盘是/dev/sdb。
三、 安装Luci
Luci是RHCS基于web的集群配置管理工具,可以从系统光盘找到对应的Luci安装包,安装如下:
[root@storgae-server ~]#rpm -ivh luci-0.12.2-12.el5.centos.1.i386.rpm
安装完成,执行luci初始化操作:
[root@storgae-server ~]#luci_admin init
Initializing the Luci server
Creating the 'admin' user
Enter password:
Confirm password:
Please wait...
The admin password has been successfully set.
Generating SSL certificates...
Luci server has been successfully initialized
输入两次密码后,就创建了一个默认登录luci的用户admin。
最后,启动luci服务即可:
[root@storgae-server ~]# /etc/init.d/luci start
服务成功启动后,就可以通过https://ip:8084访问luci了。
为了能让luci访问集群其它节点,还需要在/etc/hosts增加如下内容:
192.168.12.231 Mysql1
192.168.12.232 Mysql2
192.168.12.230 web1
192.168.12.240 web2
到这里为止,在storgae-server主机上的设置完成。
四、在集群节点安装RHCS软件包
为了保证集群每个节点间可以互相通信,需要将每个节点的主机名信息加入/etc/hosts文件中,修改完成的/etc/hosts文件内容如下:
127.0.0.1 localhost
192.168.12.230 web1
192.168.12.240 web2
192.168.12.231 Mysql1
192.168.12.232 Mysql2
将此文件依次复制到集群每个节点的/etc/hosts文件中。
RHCS软件包的安装有两种方式,可以通过luci管理界面,在创建Cluster时,通过在线下载方式自动安装,也可以直接从操作系统光盘找到所需软件包进行手动安装,由于在线安装方式受网络和速度的影响,不建议采用,这里通过手动方式来安装RHCS软件包。
安装RHCS,主要安装的组件包有cman、gfs2和rgmanager,当然在安装这些软件包时可能需要其它依赖的系统包,只需按照提示进行安装即可 ,下面是一个安装清单,在集群的四个节点分别执行 :
#install cman
rpm -ivh perl-XML-NamespaceSupport-1.09-1.2.1.noarch.rpm
rpm -ivh perl-XML-SAX-0.14-8.noarch.rpm
rpm -ivh perl-XML-LibXML-Common-0.13-8.2.2.i386.rpm
rpm -ivh perl-XML-LibXML-1.58-6.i386.rpm
rpm -ivh perl-Net-Telnet-3.03-5.noarch.rpm
rpm -ivh pexpect-2.3-3.el5.noarch.rpm
rpm -ivh openais-0.80.6-16.el5_5.2.i386.rpm
rpm -ivh cman-2.0.115-34.el5.i386.rpm
#install ricci
rpm -ivh modcluster-0.12.1-2.el5.centos.i386.rpm
rpm -ivh ricci-0.12.2-12.el5.centos.1.i386.rpm
#install gfs2
rpm -ivh gfs2-utils-0.1.62-20.el5.i386.rpm
#install rgmanager
rpm -ivh rgmanager-2.0.52-6.el5.centos.i386.rpm
五、在集群节点安装配置iSCSI客户端
安装iSCSI客户端是为了和iSCSI-target服务端进行通信,进而将共享磁盘导入到各个集群节点,这里以集群节点web1为例,介绍如何安装和配置iSCSI,剩余其它节点的安装和配置方式与web1节点完全相同 。
iSCSI客户端的安装和配置非常简单,只需如下几个步骤即可完成:
[root@web1 rhcs]# rpm -ivh iscsi-initiator-utils-6.2.0.871-0.16.el5.i386.rpm
[root@web1 rhcs]# /etc/init.d/iscsi restart
[root@web1 rhcs]# iscsiadm -m discovery -t sendtargets -p 192.168.12.246
[root@web1 rhcs]# /etc/init.d/iscsi restart
[root@web1 rhcs]# fdisk -l
Disk /dev/sdb: 10.7 GB, 10737418240 bytes
64 heads, 32 sectors/track, 10240 cylinders
Units = cylinders of 2048 * 512 = 1048576 bytes
Disk /dev/sdb doesn't contain a valid partition table
通过fdisk的输出可知,/dev/sdb就是从iSCSI-target共享过来的磁盘分区。
至此,安装工作全部结束。
六、配置RHCS高可用集群
配置RHCS,其核心就是配置/etc/cluster/cluster.conf文件,下面通过web管理界面介绍如何构造一个cluster.conf文件。
在storgae-server主机上启动luci服务,然后通过浏览器访问https://192.168.12.246:8084/,就可以打开luci登录界面,如图1所示:

图1
成功登录后,luci有三个配置选项,分别是homebase、cluster和storage,其中,cluster主要用于创建和配置集群系统,storage用于创建和管理共享存储,而homebase主要用于添加、更新、删除cluster系统和storage设置,同时也可以创建和删除luci登录用户。如图2所示:
图2
1、创建一个cluster
登录luci后,切换到cluster选项,然后点击左边的clusters选框中的“Create a new cluster”,增加一个cluster,如图3所示:
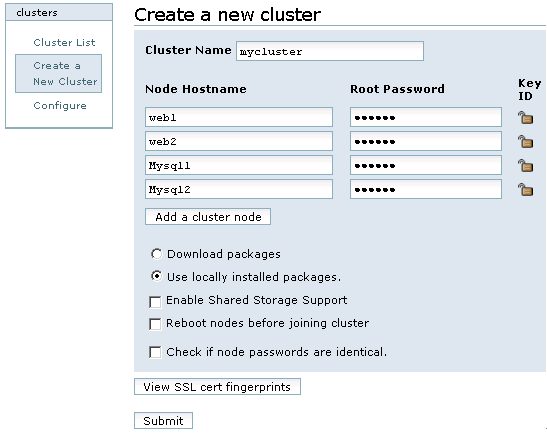
图3
在图3中,创建的cluster名称为mycluster,“Node Hostname”表示每个节点的主机名称,“Root Password”表示每个节点的root用户密码。每个节点的root密码可以相同,也可以不同。
在下面的五个选项中,“Download packages”表示在线下载并自动安装RHCS软件包,而“Use locally installed packages”表示用本地安装包进行安装,由于RHCS组件包在上面的介绍中已经手动安装完成,所以这里选择本地安装即可。剩下的三个复选框分别是启用共享存储支持(Enable Shared Storage Support)、节点加入集群时重启系统(Reboot nodes before joining cluster)和检查节点密码的一致性(Check if node passwords are identical),这些创建cluster的设置,可选可不选,这里不做任何选择。
“View SSL cert fingerprints”用于验证集群各个节点与luci通信是否正常,并检测每个节点的配置是否可以创建集群,如果检测失败,会给出相应的错误提示信息。如果验证成功,会输出成功信息。
所有选项填写完成,点击“Submit”进行提交,接下来luci开始创建cluster,如图4所示:
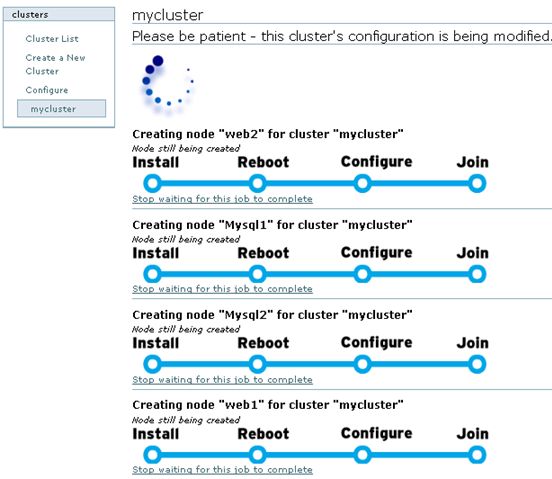
图4
在经过Install----Reboot----Configure----Join四个过程后,如果没有报错,“mycluster”就创建完成了,其实创建cluster的过程,就是luci将设定的集群信息写入到每个集群节点配置文件的过程。Cluster创建成功后,默认显示“mycluster”的集群全局属性列表,点击cluster-->Cluster list来查看创建的mycluster的状态,如图5所示:
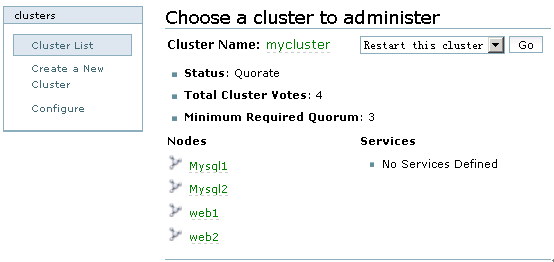
图5
从图5可知,mycluster集群下有四个节点,正常状态下,节点Nodes名称和Cluster Name均显示为绿色,如果出现异常,将显示为红色。
点击Nodes下面的任意一个节点名称,可以查看此节点的运行状态,如图6所示:
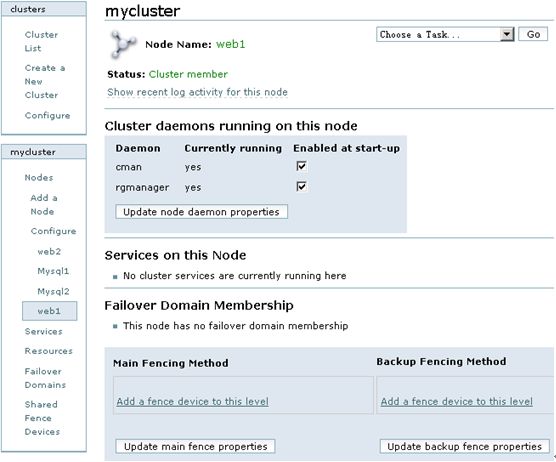
图6
从图6可以看出,cman和rgmanager服务运行在每个节点上,并且这两个服务需要开机自动启动,它们是RHCS的核心守护进程,如果这两个服务在某个节点没有启动,可以通过命令行方式手工启动,命令如下:
/etc/init.d/cman start
/etc/init.d/rgmanager start
服务启动成功后,在图6中点击“Update node daemon properties”按钮,更新节点的状态。
通过上面的操作,一个简单的cluster就创建完成了,但是这个cluster目前还是不能工作的,还需要为这个cluster创建Failover Domain、Resources、Service、Shared Fence Device等,下面依次进行介绍。
2、创建Failover Domain
Failover Domain是配置集群的失败转移域,通过失败转移域可以将服务和资源的切换限制在指定的节点间,下面的操作将创建两个失败转移域,分别是webserver-failover和mysql-failover。
点击cluster,然后在Cluster list中点击“mycluster”,接着,在左下端的mycluster栏中点击Failover Domains-->Add a Failover Domain,增加一个Failover Domain,如图7所示:
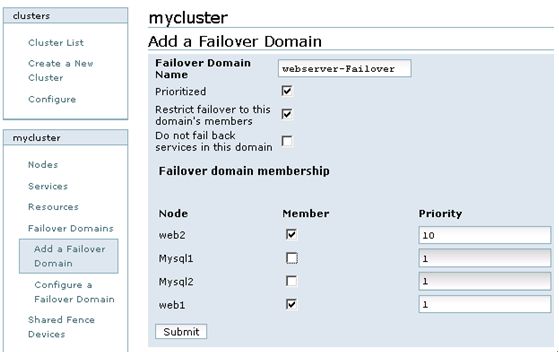
图7
在图7中,各个参数的含义如下:
Failover domain name:创建的失败转移域名称,起一个易记的名字即可。
Prioritized:是否在Failover domain 中启用域成员优先级设置,这里选择启用。
Restrict Failover to this domain’s member:表示是否在失败转移域成员中启用服务故障切换限制。这里选择启用。
Do not fail back services in this domain:表示在这个域中使用故障切回功能,也就是说,主节点故障时,备用节点会自动接管主节点服务和资源,当主节点恢复正常时,集群的服务和资源会从备用节点自动切换到主节点。
然后,在Failover domain membership的Member复选框中,选择加入此域的节点,这里选择的是web1和web2节点,然后,在“priority”处将web1的优先级设置为1,web2的优先级设置为10。需要说明的是“priority”设置为1的节点,优先级是最高的,随着数值的降低,节点优先级也依次降低。
所有设置完成,点击Submit按钮,开始创建Failover domain。
按照上面的介绍,继续添加第二个失败转移域mysql-failover,在Failover domain membership的Member复选框中,选择加入此域的节点,这里选择Mysql1和Mysql2节点,然后,在“priority”处将Mysql1的优先级设置为2,Mysql2的优先级设置为8。
3、创建Resources
Resources是集群的核心,主要包含服务脚本、IP地址、文件系统等,RHCS提供的资源如图8所示:
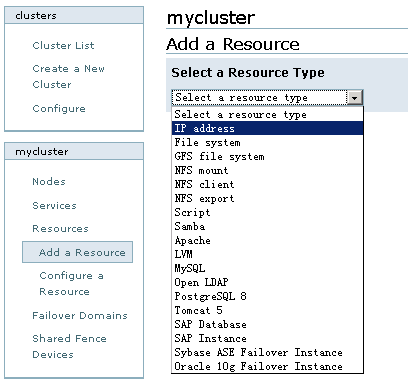
图8
依次添加IP资源、http服务资源、Mysql管理脚本资源、ext3文件系统,如图9所示:
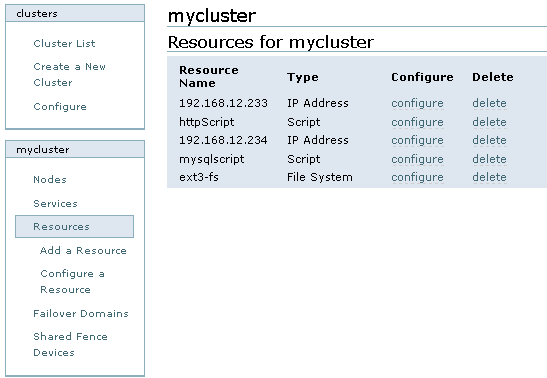
图9
4、创建Service
点击cluster,然后在Cluster list中点击“mycluster”,接着,在左下端的mycluster栏中点击Services-->Add a Service,在集群中添加一个服务,如图10所示:

图10
所有服务添加完成后,如果应用程序设置正确,服务将自动启动,点击cluster,然后在Cluster list中可以看到两个服务的启动状态,正常情况下,均显示为绿色。如图11所示:
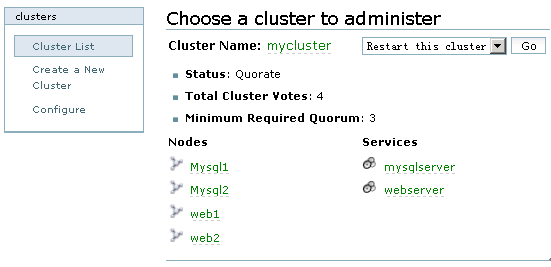
图11
七、配置存储集群GFS
在上面章节中,我们已经通过storgae-server主机将一个磁盘分区共享给了集群系统的四个节点,接下来将进行磁盘分区、格式化、创建文件系统等操作。
(1) 对磁盘进行分区
可以在集群系统任意节点对共享磁盘分区进行磁盘的分区和格式化,这里选择在节点web1上进行,首先对共享磁盘进行分区,操作如下:
[root@web1 ~]# fdisk /dev/sdb
这里将共享磁盘分为三个有效分区,分别将/dev/sdb5用于GFS文件系统,将/dev/sdb6用于ext3文件系统,而将/dev/sdb7用于表决磁盘,关于表决磁盘,下面马上会进行讲述。
(2) 格式化磁盘
接下来,在web1节点将磁盘分区分别格式化为ext3和gfs2文件系统,操作如下:
[root@web1 ~]# mkfs.ext3 /dev/sdb6
[root@web1 ~]# mkfs.gfs2 -p lock_dlm -t mycluster:my-gfs2 -j 4 /dev/sdb5
其中:
-p lock_dlm
定义为DLM锁方式,如果不加此参数,当在两个系统中同时挂载此分区时就会像EXT3格式一样,两个系统的信息不能同步。
-t mycluster:my-gfs2
指定DLM锁所在的表名称,mycluster就是RHCS集群的名称,必须与cluster.conf文件中Cluster标签的name值相同。
-j 4
设定GFS2文件系统最多支持多少个节点同时挂载,这个值可以通gfs2_jadd命令在使用中动态调整。
/dev/sdb5
指定要格式化的分区设备标识。
所有操作完成后,重启集群所有节点,保证划分的磁盘分区能够被所有节点识别。
(3)挂载磁盘
所有节点重新启动后,就可以挂载文件系统了,依次在集群的每个节点执行如下操作,将共享文件系统挂载到/gfs2目录下:
[root@web1 ~]#mount -t gfs2 /dev/sdb5 /gfs2 –v
/sbin/mount.gfs2: mount /dev/sdb5 /gfs2
/sbin/mount.gfs2: parse_opts: opts = "rw"
/sbin/mount.gfs2: clear flag 1 for "rw", flags = 0
/sbin/mount.gfs2: parse_opts: flags = 0
/sbin/mount.gfs2: write "join /gfs2 gfs2 lock_dlm mycluster:my-gfs2 rw /dev/sdb5"
//sbin/mount.gfs2: mount(2) ok
/sbin/mount.gfs2: lock_dlm_mount_result: write "mount_result /gfs2 gfs2 0"
/sbin/mount.gfs2: read_proc_mounts: device = "/dev/sdb5"
/sbin/mount.gfs2: read_proc_mounts: opts = "rw,hostdata=jid=3:id=65540:first=0“
通过“-v”参数可以输出挂载gfs2文件系统的过程,有助于理解gfs2文件系统和问题排查。
为了能让共享文件系统开机自动挂载磁盘,将下面内容添加到每个集群节点的/etc/fstab文件中。
#GFS MOUNT POINTS
/dev/sdb5 /gfs2 gfs2 defaults 1 1
八、配置表决磁盘
(1)使用表决磁盘的必要性
在一个多节点的RHCS集群系统中,一个节点失败后,集群的服务和资源可以自动转移到其它节点上,但是这种转移是有条件的,例如,在一个四节点的集群中,一旦有两个节点发生故障,整个集群系统将会挂起,集群服务也随即停止,而如果配置了存储集群GFS文件系统,那么只要有一个节点发生故障,所有节点挂载的GFS文件系统将hung住。此时共享存储将无法使用,这种情况的出现,对于高可用的集群系统来说是绝对不允许的,解决这种问题就要通过表决磁盘来实现了。
(2)表决磁盘运行机制
表决磁盘,即Quorum Disk,在RHCS里简称qdisk,是基于磁盘的Cluster仲裁服务程序,为了解决小规模集群中投票问题,RHCS引入了Quorum机制机制,Quorum表示集群法定的节点数,和Quorum对应的是Quorate,Quorate是一种状态,表示达到法定节点数。在正常状态下,Quorum的值是每个节点投票值再加上 QDisk分区的投票值之和。
QDisk是一个小于10MB的共享磁盘分区,Qdiskd进程运行在集群的所有节点上,通过Qdiskd进程,集群节点定期评估自身的健康情况,并且把自身的状态信息写到指定的共享磁盘分区中,同时Qdiskd还可以查看其它节点的状态信息,并传递信息给其它节点。
(3)RHCS中表决磁盘的概念
和qdisk相关的几个工具有mkdisk、Heuristics。
mkdisk是一个集群仲裁磁盘工具集,可以用来创建一个qdisk共享磁盘也可以查看共享磁盘的状态信息。mkqdisk操作只能创建16个节点的投票空间,因此目前qdisk最多可以支持16个节点的RHCS高可用集群。
有时候仅靠检测Qdisk分区来判断节点状态还是不够的,还可以通过应用程序来扩展对节点状态检测的精度,Heuristics就是这么一个扩充选项,它允许通过第三方应用程序来辅助定位节点状态,常用的有ping网关或路由,或者通过脚本程序等,如果试探失败,qdiskd会认为此节点失败,进而试图重启此节点,以使节点进入正常状态。
(4)创建一个表决磁盘
在上面章节中,已经划分了多个共享磁盘分区,这里将共享磁盘分区/dev/sdb7作为qdisk分区,下面是创建一个qdisk分区:
[root@web1 ~]# mkqdisk -c /dev/sdb7 -l myqdisk
[root@web1 ~]# mkqdisk –L #查看表决磁盘信息
(5)配置Qdisk
这里通过Conga的web界面来配置Qdisk,首先登录luci,然后点击cluster,在Cluster list中点击“mycluster”,然后选择“Quorum Partition”一项,如图12所示:
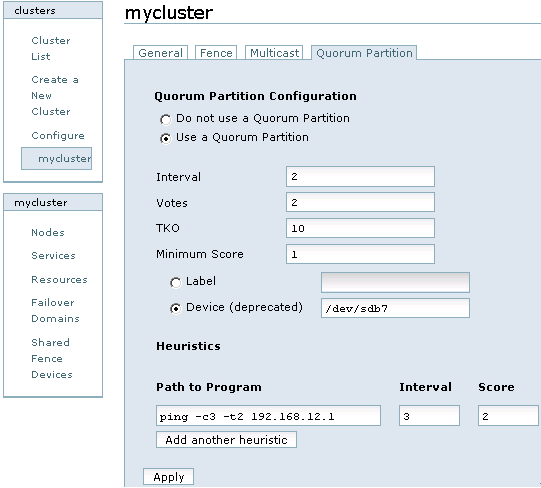
图12
对图12中每个选项的含义解释如下:
Interval:表示间隔多长时间执行一次检查评估,单位是秒。
Votes:指定qdisk分区投票值是多少。
TKO:表示允许检查失败的次数。一个节点在TKO*Interval时间内如果还连接不上qdisk分区,那么就认为此节点失败,会从集群中隔离。
Minimum Score:指定最小投票值是多少。
Label:Qdisk分区对应的卷标名,也就是在创建qdisk时指定的“myqdisk”,这里建议用卷标名,因为设备名有可能会在系统重启后发生变化,但卷标名称是不会发生改变的。
Device:指定共享存储在节点中的设备名是什么。
Path to program: 配置第三方应用程序来扩展对节点状态检测的精度,这里配置的是ping命令
Score:设定ping命令的投票值。
interval:设定多长时间执行ping命令一次。
(6)启动Qdisk服务
在集群每个节点执行如下命令,启动qdiskd服务:
[root@web1 ~]# /etc/init.d/qdiskd start
qdiskd启动后,如果配置正确,qdisk磁盘将自动进入online状态:
[root@web1 ~]# clustat -l
Cluster Status for mycluster @ Sat Aug 21 01:25:40 2010
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
Web 1 Online, rgmanager
Mysql1 2 Online, rgmanager
Mysql2 3 Online, rgmanager
web1 4 Online, Local, rgmanager
/dev/sdb7 0 Online, Quorum Disk
至此,Qdisk已经运行起来了。
九、配置Fence设备
配置Fence设备 是RHCS集群系统中必不可少的一个环节,通过Fence设备可以防止集群资源(例如文件系统)同时被多个节点占有,保护了共享数据的安全性和一致性节,同时也可以防止节点间脑裂的发生。
GFS是基于集群底层架构来传递锁信息的,或者说是基于RHCS的一种集群文件系统,因此使用GFS文件系统也必须要有fence设备。
RHCS提供的fence device有两种,一种是内部fence设备。常见的有:
IBM服务器提供的RSAII卡
HP服务器提供的iLO卡
DELL服务器提供的DRAC卡
智能平台管理接口IPMI
常见的外部fence设备有:UPS、SAN SWITCH、NETWORK SWITCH,另外如果共享存储是通过GNBD Server实现的,那么还可以使用GNBD的fence功能。
点击cluster,然后点击“cluster list”中的“mycluster”,在左下角的mycluster栏目中选择Shared Fence Devices-->Add a Sharable Fence Device,在这里选择的Fence Device为“WTI Power Switch”,Fence的名称为“WTI-Fence”,然后依次输入IP Address和Password,如图13所示:
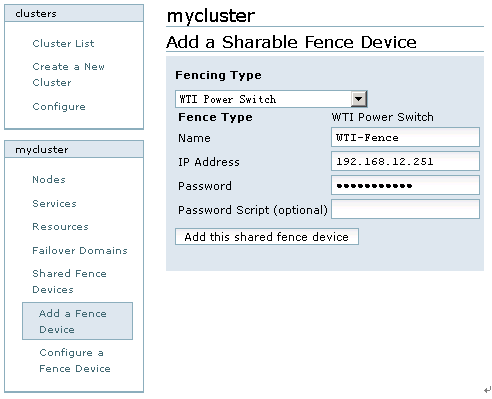
图13
至此,基于web界面的RHCS配置完成。
(待续)