参考
老钱 服务发现的基本原理
服务发现
聊聊 Node.js RPC(二)— 服务发现
在传统的系统部署中,服务运行在一个固定的已知的 IP 和端口上,如果一个服务需要调用另外一个服务,可以通过地址直接调用,但是,在虚拟化或容器话的环境中,服务实例的启动和销毁是很频繁的,服务地址在动态的变化。服务发现的主要优点是可以无需了解架构的部署拓扑环境,只通过服务的名字就能够使用服务,提供了一种服务发布与查找的协调机制。服务发现除了提供服务注册、目录和查找三大关键特性,还需要能够提供健康监控、多种查询、实时更新和高可用性等。
一、什么是服务发现?
服务发现并没有怎样的高深莫测,它的原理再简单不过。只是市面上太多文章将服务发现的难度妖魔化,读者被绕的云里雾里,顿觉自己智商低下不敢高攀。
- 服务提供者是什么,简单点说就是一个HTTP服务器,提供了API服务,有一个IP端口作为服务地址。
- 服务消费者是什么,它就是一个简单的进程,想要访问服务提供者提供的服务来干一些事情。一个HTTP服务器既可以是服务提供者对外提供服务,也可以是消费者需要别的服务提供者提供的服务,这就是服务依赖,没有你我就不是我自己。复杂的服务甚至有多个服务依赖。
- 服务发现有三个角色,服务提供者、服务消费者和服务中介。服务中介是联系服务提供者和服务消费者的桥梁。服务提供者将自己提供的服务地址注册到服务中介,服务消费者从服务中介那里查找自己想要的服务的地址,然后享受这个服务。服务中介提供多个服务,每个服务对应多个服务提供者。
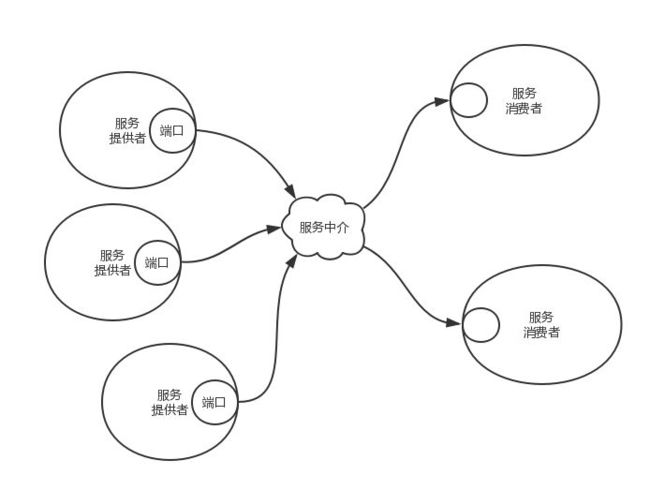
服务中介就是一个字典,字典里有很多key/value键值对,key是服务名称,value是服务提供者的地址列表。服务注册就是调用字典的Put方法塞东西,服务查找就是调用字典的Get方法拿东西。
当服务提供者节点挂掉时,要求服务能够及时取消注册,比便及时通知消费者重新获取服务地址。
当服务提供者新加入时,要求服务中介能及时告知服务消费者,你要不要尝试一下新的服务。
二、Redis作为服务中介
Redis里面有丰富的数据结构,拿来存储服务字典再合适不过了。对每一个服务名称,我们用一个set结构存储服务的IP:Port字符串。如果服务提供者加入,调用sadd命令加入服务地址,如果服务挂掉,调用srem命令移除服务地址。对服务消费者使用smembers指令获取所有服务地址然后在消费进程里随机挑一个,或者使用srandmemember指令直接获取随机服务地址。
这个时候你也许会表示怀疑,服务发现真这么简单么?答案是还差一点,关于上面的这个解决方案有几个问题。
1.第一个问题是服务提供者进程如果被kill -9暴力杀死,不能主动调用srem命令怎么办?
这个时候服务列表中多了一个黑地址指向了不存在的服务而消费者完全不知道,这个时候服务中介就成了黑中介了。那该怎么办呢?
我们引入服务保活和检查机制,并更换数据结构。服务提供者需要每隔5秒左右向服务中介汇报存活,服务中介将服务地址和汇报时间记录在zset数据结构的value和score中。服务中介需要每隔10秒左右检查zset数据结构,踢掉汇报时间严重落后的服务地址项。这样就可以准实时地保证服务列表中服务地址的有效性。
2.第二个问题是服务列表变动时如何通知消费者。有两种解决方案。
第一种是轮询,消费者需要每隔几秒查询服务列表是否有改变。如果服务很多,服务列表很大,消费者很多,redis会有一定压力。所以这时候可以引入服务列表的版本号机制,给每个服务提供一个key/value设置服务的版本号,就是在服务列表发生变动时,递增这个版本号。消费者只需要轮询这个版本号的变动即可知道服务列表是否发生了变化。因为服务列表比较稳定,仅在网络严重抖动的情况下才会频繁发生变动,所以redis几乎没有压力。
第二种是采用pubsub。这种方式及时性要明显好于轮询。缺点是每个pubsub都会占用消费者一个线程和一个额外的redis连接。为了减少对线程和连接的浪费,我们使用单个pubsub广播全局版本号的变动。所谓全局版本号就是任意服务列表发生了变动,这个版本号都会递增。接收到版本变动的消费者再去检查各自的依赖服务列表的版本号是否发生了变动。这种全局版本号也可以用于第一种轮询方案。
3.第三个问题是redis是单点的,如果挂掉了怎么办?
这是个大问题。正是因为这个问题的存在,流行的服务发现系统都是使用分布式数据库zookeeper/etcd/consul等来作为服务中介,它们是分布式的多节点的,挂掉了一个节点没关系,系统仍然可以正常工作。
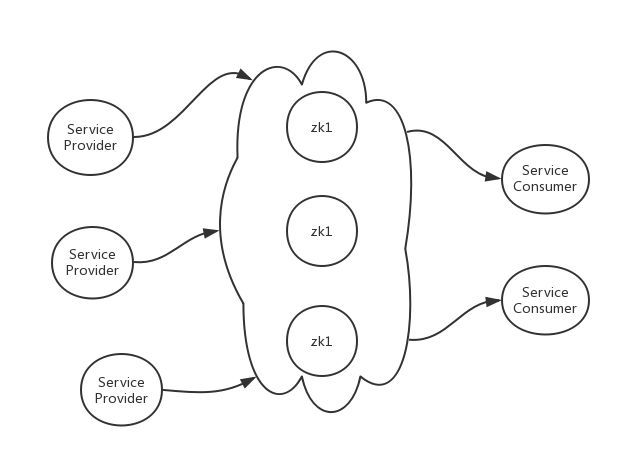
那如果整个zk集群挂掉会怎样呢?其实每个服务消费者在本地内存里都会存一份当前的服务列表,即使服务中介集群挂掉,也是可以使用当前的服务列表正常工作的。
那redis作为服务中介就真的不靠谱了么?其实还有个redis-sentinel可以消除redis的单点问题,redis-sentinel可以在主节点挂掉的时候,自动升级从节点为主节点。所以拿redis干这件事也是可以的。用redis干服务发现确实非常简单,虽然这种方式非常不流行。
三、服务提供者不只是HTTP服务
上面提到服务提供者简单来说就是HTTP服务器,其实服务多种多样。可以是数据库服务,可以是RPC服务,可以是UDP服务等等。
如果是MySQL数据库,那如何将MySQL服务注册到服务中介呢?原生的MySQL可没有提供这样功能。一般做法是提供一个Agent代理去注册。这个代理除了将服务地址注册到服务中介外,还需要监控MySQL的健康状况,以便当MySQL宕机时能及时切换到新的MySQL服务地址。一般这个Agent为了节省资源而不止监控一个数据库,它可以同时监控多个数据库,甚至是多种数据库。
四、服务配置重加载
服务发现一般只是用来注册和查找服务列表这样一个比较单纯的功能。不过现代的服务发现系统还会集成服务配置管理功能。这样可以实现服务配置的实时重加载。原理也很简单,就是对于每一个服务项,服务中介还会存储一个单独的key/value用来存储这个服务的配置信息。当这个配置项在后台被修改时,服务中介会实时通知相关服务器变更配置信息。比如数据库地址变动,业务参数修改等。
五、服务管理后台
为了便于服务管理,一般服务发现还会提供一个服务管理后台,用于管理人员查看服务集群的状态。如果服务注册和汇报时提供冗余的配置信息,服务管理后台就可以呈现更为详细的服务信息。服务管理后台还可以将所有的服务依赖组织起来,呈现出一颗漂亮的服务依赖树。
六、两种主要的服务发现方式
1.客户端服务发现
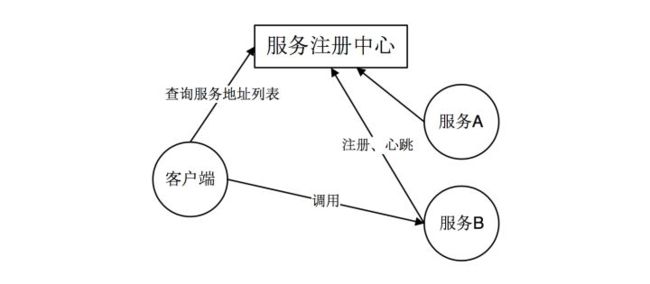
在使用客户端发现方式时,客户端通过查询服务注册中心,获取可用的服务的实际网络地址(IP 和端口)。然后通过负载均衡算法来选择一个可用的服务实例,并将请求发送至该服务。优点:架构简单,扩展灵活,方便实现负载均衡功能,缺点:强耦合,有一定开发成本。
2.服务端服务发现
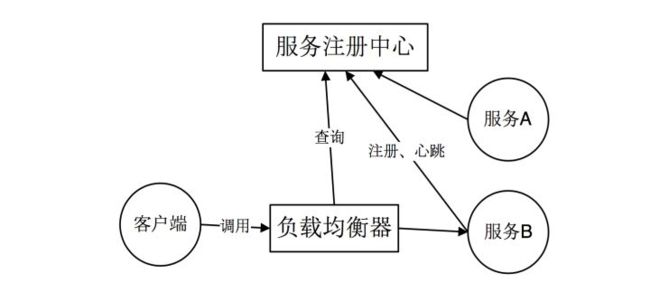
客户端向load balancer 发送请求。load balancer 查询服务注册中心找到可用的服务,然后转发请求到该服务上。和客户端发现一样,服务都要到注册中心进行服务注册和注销。优点:服务的发现逻辑对客户端是透明的。缺点:需要额外部署和维护高可用的负载均衡器。
3.服务发现和负载均衡的关系
最后提到负载均衡这个概念是为后面文章做铺垫,因为它很容易和服务发现混淆,在很多简单的场景我们甚至也不去刻意区分它们。但本质上它们的层次和解决的问题是不一样的,简单说服务发现是负载均衡的前提,负载均衡要解决的是拿到服务列表后将流量合理的分配到各个节点上的问题。
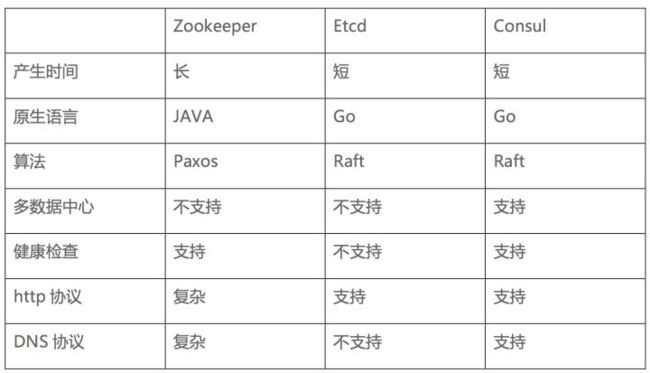
七、常见的服务发现框架
常见服务发现框架 Consul、 ZooKeeper以及Etcd
ZooKeeper 是这种类型的项目中历史最悠久的之一,它起源于 Hadoop。它非常成熟、可靠,被许多大公司(YouTube、eBay、雅虎等)使用。
Etcd是一个采用 HTTP 协议的健/值对存储系统,它是一个分布式和功能层次配置系统,可用于构建服务发现系统。其很容易部署、安装和使用,提供了可靠的数据持久化特性。搭配一些第三方工具,etcd(健/值对存储系统)+ Registrator(服务注册器) + Confd(轻量级的配置管理工具)
Consul 是强一致性的数据存储,使用 Gossip 形成动态集群。它提供分级键/值存储方式,不仅可以存储数据,而且可以用于注册器件事各种任务,从发送数据改变通知到运行健康检查和自定义命令