单一职责
功能单一
功能单一是SRP最基本要求,也就是你一个类的功能职责要单一,这样内聚性才高。
比如,下面这个参数类,是用来查询网站Buyer信息的,按照SRP,里面就应该放置查询相关的Field就好了。
@Data
public class BuyerInfoParam {
// Required Param
private Long buyerCompanyId;
private Long buyerAccountId;
private Long callerCompanyId;
private Long callerAccountId;
private String tenantId;
private String bizCode;
private String channel; //这个Channel在查询中不起任何作用,不应该放在这里
}可是呢? 事实并不是这样,下面的三个参数其实查询时根本用不到,而是在组装查询结果的时候用到,这给我阅读代码带来了很大的困惑,因为我一直以为这个channel(客户来源渠道)是一个查询需要的一个重要信息。
那么如果和查询无关,为什么要把它放到查询param里面呢,问了才知道,只是为了组装查询结果时拿到数据而已。
所以我重构的时候,果断把查询没用到的参数从BuyerInfoParam中移除了,这样就消除了理解上的歧义。
Tips:不要为了图方便,而破坏SOLID原则,方便的后果就是代码腐化,看不懂,往后要付出的代价更高。
功能内聚
在类的职责单一基础之上,我们还要识别出是不是有功能相似的类或者组件,如果有,是不是要整合起来,而不要让功能类似的代码散落在多处。
比如,代码中我们有一个TenantContext,而build这个Context统一是在ContextPreInterceptor中做的,其中Operator的值一开始只有crmId,但是随着业务的变化operator的值在不同的场景值会不一样,可能是aliId,也可能是accountId。
这样就需要其它id要转换成crmId的工作,重构前这个转换工作是分散在多个地方,不满足SRP。
//在BaseMtopServiceImpl中有crmId转换的逻辑
public String getCrmUserId(Long userId){
AccountInfoDO accountInfoDO = accountQueryTunnel.getAccountDetailByAccountId(userId.toString(), AccountTypeEnum.INTL.getType(), false);
if(accountInfoDO != null){
return accountInfoDO.getCrmUserId();
}
return StringUtils.EMPTY;
}
//在ContextUtilServiceImpl中有crmId转换的逻辑
public String getCrmUserIdByMemberSeq(String memberSeq) {
if(StringUtil.isBlank(memberSeq)){
return null;
}
MemberMappingDO mappingDO = memberMappingQueryTunnel.getMappingByAccountId(Long.valueOf(memberSeq));
if(mappingDO == null || mappingDO.getAliId() == null){
return null;
}
}重构的做法是将build context的逻辑,包括前序的crmId的转换逻辑,全部收拢到ContextPreInterceptor,因为它的职责就是build context,这样代码的内聚性,可复用性和可读性都会好很多。
@Override
public void preIntercept(Command command) {
...
String crmUserId = getCrmUserId(command);
if(StringUtil.isBlank(crmUserId)){
throw new BizException(ErrorCode.BIZ_ERROR_USER_ID_NULL, "can not find crmUserId with "+command.getOperater());
}
...
}
//将crmId的转换逻辑收拢至此
private String getCrmUserId(Command command) {
if(command.getOperatorIdType() == OperatorIdType.CRM_ID){
return command.getOperater();
}
else if(command.getOperatorIdType() == OperatorIdType.ACCOUNT_ID){
MemberMappingDO mappingDO = memberMappingQueryTunnel.getMappingByAccountId(Long.valueOf(command.getOperater()));
if(mappingDO == null || mappingDO.getAliId() == null){
return null;
}
return fetchByAliId(mappingDO.getAliId().toString());
}
else if(command.getOperatorIdType() == OperatorIdType.ALI_ID){
return fetchByAliId(command.getOperater());
}
return null;
}开闭原则
OCP是OO非常重要的原则,遵循OCP可以极大的提升我们代码的扩展性,要想写出好的OCP代码,前提是要熟练掌握常用的设计模式,常用的有助于OCP的设计模式有Abstract Factory,Template,Strategy,Chain of Responsibility, Obeserver, Decorator等
关于OCP的重构需要注意两点:
- 不要滥用设计模式:不要有了锤子就到处乱锤,不恰当的使用不解决问题不说,还会增加复杂度。
- 要敢于重构:很多的功能点一开始都不需要扩展的,但是随着业务的发展,会变得需要扩展,此时就需要果敢一点,该重构重构,该上设计模式,上,不能等,不能将就!
这里主要以Template和Chain of Responsibility为例,来介绍关于OCP的重构。
模板方法
比如,在处理Leads的时候,针对不同的Leads来源,其处理可能稍有不同,所以我重构的时候,觉得模板方法是比较好的选项。
因为对于不同的Leads来源,只有在线索已存在,但没创建过客户的情况下,处理逻辑不同,其它逻辑都可以共用,那么把processRepeatedLeadsWithNoCustomer设置为abstract就好了。
Tips:在使用设计模式的时候,最好能在类的命名上体现这个设计模式,这样看代码的人会更容易理解。
public abstract class AbstractLeadsProcessTemplate implements LeadsProcessServiceI {
...
@Override
public void processLeads(IcbuLeadsE icbuLeadsE) {
IcbuLeadsE existingLeads = icbuLeadsE.checkRepeat();
//1.新线索
if(existingLeads == null){
processBrandNewLeads(icbuLeadsE);
}
// 2\. 线索已经存在,但是没有创建过客户
else if(existingLeads.isCustomerNotCreated()){
processRepeatedLeadsWithNoCustomer(existingLeads, icbuLeadsE);
}
//3\. 线索已经存在,且创建过客户,尝试捡回私海
else{
processRepeatedLeadsAndCustomer(existingLeads, icbuLeadsE);
}
}
/**
* 处理线索已存在,客户未创建
* @param existingLeads 系统中已存在的Leads
* @param comingLeads 新来的Leads
*/
public abstract void processRepeatedLeadsWithNoCustomer(IcbuLeadsE existingLeads, IcbuLeadsE comingLeads);
责任链
在我们的营销系统中,有一个EDM(Email Direct Marketing)的功能,在发送邮件之前,我们要根据规则过滤掉一些客户,比如没有邮箱地址,没有订阅关系,3天内重复发送等等,而且这个规则随着业务的变化,很可能会增加或减少。
这里用if-else当然也能解决问题,但很明显不满足OCP,如果用一个Pipeline的模式,其扩展性就会好很多,类似于Servlet API中的FilterChain,增加、删除Filter都很灵活。
FilterChain filterChain = FilterChainFactory.buildFilterChain(
NoEmailAddressFilter.class,
EmailUnsubscribeFilter.class,
EmailThreeDayNotRepeatFilter.class);
//具体的Filter
public class NoEmailAddressFilter implements Filter {
@Override
public void doFilter(Object context, FilterInvoker nextFilter) {
Map contextMap = (Map)context;
String email = ConvertUtils.convertParamType(contextMap.get("email"), String.class);
if(StringUtils.isBlank(email)){
contextMap.put("success", false);
return;
}
nextFilter.invoke(context);
}
} SOFA框架
这次代码重构中发现,对于框架概念的误用,也是造成代码混乱的原因之一,在SOFA框架中我们明确定义了module,package和class的scope和功能,但是在实施过程中,还是出现了在层次归属,命名和使用上的一些混乱,特别是Convertor,Assembler和扩展点。
Convertor
在SOFA中有三类主要的对象:
- ClientObject: 也就是二方库中的数据对象,主要承担DTO的职责。
- Entity/ValueObject: 也就是既有属性又有行为的领域实体。
- DataObeject:是用来获取数据用的,主要是DAO使用。
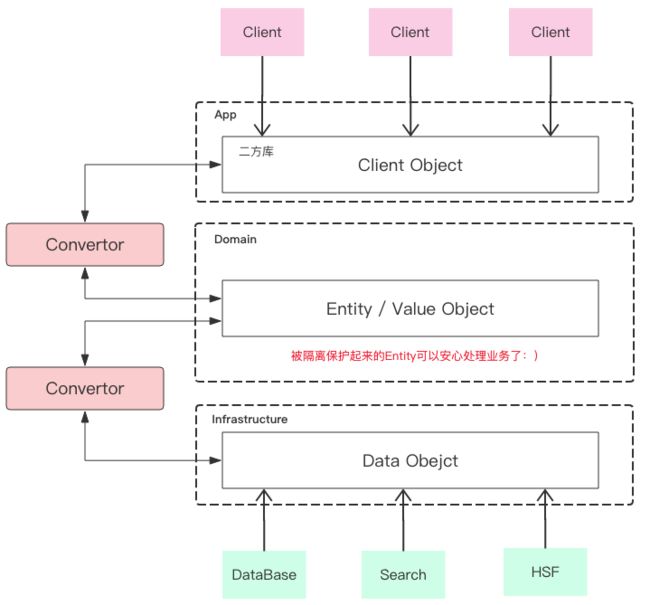
而Convertor在上面三个对象之间的转换起到了至关重要的作用,然而Convertor里面的逻辑应该是简单的,大部分都是setter/getter, 如果属性重复度很高的话,也可以使用BeanUtils.copyProperties让代码变得更简洁。
但事实情况是,现在系统中很多的Convertor逻辑并没有在Convertor里面。
比如将询盘数据convert成LeadsE,处理类是LeadsBuildStrategy,这个命名是不合适的。
所以我将这段逻辑重构到ICBULeadsConvertor也等于是在清晰的告诉看代码的人,这里是做了一个Client数据到LeadsEntity的转换,仅此而已。
Assembler
Assembler在SOFA框架中的定义是组装参数使用的,所以看到Assembler我就很清楚这个类是用来组装参数的。
例如,组装OpenSearch的查询条件,原来用的是扩展点CustomerRepeatRuleExtPt
但是RuleExt这个概念,只有在不同业务场景下的业务扩展才需要用到,所以这种命名和使用是不恰当的,组装参数直接用RepeatCheckConditionAssembler就好了。
重构前:
List repeatConditions =
ruleExecutor.execute(CustomerRepeatRuleExtPt.class,
repeatExt -> repeatExt.getRepeatCondition(queryField)); 重构后:
RepeatConditionDO repeatConditionDO =
repeatCheckConditionAssembler.assembleCustomerRepeatCheckCondition(repeatCheckParam);
扩展点
扩展点是我SOFA框架中针对不同业务或租户的一种扩展机制,现在代码中有一些使用,但是因为我们目前只有ICBU的场景,所以基本上所有的扩展点只有一个扩展实现。
如果这样的话,我建议先不要提前抽出来扩展点,等有多业务场景的时候,再去重构。
例如OppotunityDistributeRuleExtPt、OpportunityOrgChangeRuleExtPt、LeadsCreateCustomerRuleExtPt、CustomerNoteAppendRuleExtPt等等,这样的case有很多。
如果是业务内的扩展,使用Strategy Pattern就好了。
Tips:简单一点,敏捷一点,不要太多的“提前设计和规划”,等变化来了再重构,Keep it Simple!
领域建模
领域建模的核心,是在深入理解业务的基础上,进行合理的领域抽象,将重要的业务知识、领域概念用通用语言(Ubiquitous Langua)的方式,统一的在PRD,模型和代码中进行显性化的表达,从而提升代码的可读性和可维护性。
所以能否合理的抽象出Value Object,Domain Entity,领域行为和领域服务,将成为DDD运用是否得当的关键。
Tips:错误的抽象,随心而欲的乱抽象,还不如不要抽象。
领域对象
领域对象主要包括ValueObject和Entity,二者都是在表达一个重要的领域概念,其区别在于ValueObject是immutable的,而Entity不是,它需要有唯一的id做标识。
在进行领域对象抽取的时候,要注意以下两点:
1、不要把重要的领域概念遗弃在Domain外面:
比如这次重构的主要业务——Leads引入,原来的Leads Entity形同虚设,业务逻辑都散落在外面,像Leads判重,Leads生成客户等业务知识都没有在Entity上体现出来,所以这种建模就是不合理的,也违背了DDD的初衷。
2、不要把非领域概念的对象强加到Domain中:
比如RepeatQueryFieldV只是一个Search的查询参数,不应该是一个ValueObject,更合适的做法是定义成一个RepeatCheckParam放到Infrastructure层去,这样理解起来更方便。
分析领域
客户通的Leads来源很大部分来自于网站的询盘(inquiry)联系人,所以对于新的询盘,我们当成新的Leads来处理。但是网站那边的询盘联系人修改呢,这个很明显是Contact域的事情,如果你和Leads揉在一起,会导致混乱。
public static LeadsEntryEvent ofAction(String action, LeadsE leads) {
LeadsEntryEvent event = null;
LeadsEntryAction entryAction = LeadsEntryAction.of(action);
if (null != entryAction) {
switch (entryAction) {
case ADD:
event = new LeadsAddEvent(leads);
break;
case UPDATE://TODO: This is not Leads, 是联系人,不要放在Leads里处理
event = new LeadsUpdateEvent(leads);
break;
case DELETE://TODO: This is not Leads, 是联系人,不要放在Leads里处理
event = new LeadsDeleteEvent(leads);
break;
case ASSIGN://TODO: This is not Leads, 不要放在Leads里处理
event = new LeadsAssignEvent(leads);
break;
case SYNC://TODO: to delete
event = new LeadsSyncEvent(leads);
break;
case IM_ADD:
event = new LeadsImChannelAddEvent(leads);
break;
case MC_ADD:
event = new LeadsMcChannelAddEvent(leads);
break;
default:很多的行为,放在多个Domain上都可以做,这个时候就要仔细分析,多动动头脑,想想哪个Domain是最合适的Domain,而不是戴着耳机,瞧着代码,实现业务功能,完事走人,留下满地的卫生纸!
领域行为 vs. 领域服务
区分领域行为和领域服务,可以参考下面的划分:
- 领域行为:是我这个Entity范畴之内的,添加到Entity身上,千万不要不假思索的就抽成一个DomainService,这样Entity很容易被架空。
- 领域服务:不是一个Entity能handle了的行为,可以考虑抽到更上层的DomainService中去。
因此,对于增加新Leads这个动作来说,直觉上应该是属于LeadsEntity的,但是仔细分析一下,我们会发现在增加新Leads的同时,还要创建客户、联系人。如果有分配需要的话,还要将机会分配到业务员的私海。
这么多的逻辑,这么多Entity的交互,如果再放到LeadsEntity就不合适了,所以重构的时候,我抽象出LeadsProcessService这个DomainService,这样在表达上会更加清晰,同事扩展起来也更方便。
@Override
public void processLeads(IcbuLeadsE icbuLeadsE) {
IcbuLeadsE existingLeads = icbuLeadsE.checkRepeat();
//1.新线索
if(existingLeads == null){
processBrandNewLeads(icbuLeadsE);
}
// 2\. 线索已经存在,但是没有创建过客户
else if(existingLeads.isCustomerNotCreated()){
processRepeatedLeadsWithNoCustomer(existingLeads, icbuLeadsE);
}
//3\. 线索已经存在,且创建过客户,尝试捡回私海
else{
processRepeatedLeadsAndCustomer(existingLeads, icbuLeadsE);
}
}统一语言
PRD中的语言,我们平时沟通的语言,模型中的语言和我们的代码中的语言要保持一致,如果不一致,或者缺失都会极大的增加我们的代码理解成本,使得代码维护变得困难。
比如客户判重,联系人判重都是非常重要的领域概念,但是在我们领域模型上并没有被体现,应该将其凸显出来:
/**
* 客户判重
*
* @return 如果有重复的客户,返回其customerId, 否则返回null
*/
public String checkRepeat() {
RepeatCheckParam repeatCheckParam = RepeatCheckParam.ofCompanyName(companyName);
...
}
/**
* 联系人判重,主要通过email来判重
* @return 如果有重复的联系人,返回其contactId, 否则返回null
*/
public String checkRepeat(){
if(email == null || email.size() == 0){
return null;
}
//只检查第一个email,因为icbu业务线中一个联系人只有一个email
RepeatCheckParam repeatCheckParam = RepeatCheckParam.ofContactEmail(email.iterator().next());
...
}在系统中目前还有checkConflict表示判重,这个需要团队达成一致,如果大家都同意用checkRepeat表示判重,那以后就统一用checkRepeat。
这地方不要纠结翻译的准确性什么的,就像公海这个概念我们用的是PublicSea,这是一个很明显的chinglish,但是大家读起来顺口,也容易理解,我觉得对于中国程序员来说就比SharedTerritory要好。
业务语义显性化
还是那句话,代码是写给人读的,机器能执行的代码谁都可以写,写出人能读懂的代码才是NB。
下面以两个重构案例来说明什么是业务语义显性化,大家自己体会一下差别:
1、判断Leads是否创建过客户,其逻辑是看Leads是否有CustomerId
重构前:
if (StringUtil.isBlank(existLeads.getCustomerId())重构后:
if(existingLeads.isCustomerNotCreated())Tips:虽然只是一行代码,但是却是编程认知的差别。
2、判断Customer是否在自己的私海
重构前:
public boolean checkPrivate(CustomerE customer) {
IcbuCustomerE icbuCustomer = (IcbuCustomerE)customer;
return !PvgContext.getCrmUserId().equals(NIL_VALUE)
&& icbuCustomer.getCustomerGroup() != CustomerGroup.AliCrmCustomerGroup.CANCEL_GROUP;
}重构后:
/**
* 判断是否可以被捡入私海
* @return
*/
public boolean isAvailableForPrivateSea(){
//如果不是业务员操作,不能捡入私海
if(StringUtil.isBlank(PvgContext.getCrmUserId())){
return false;
}
//如果是"删除分组"的客户,不捡入私海,放到公海
if(this.getCustomerGroup() == CustomerGroup.AliCrmCustomerGroup.CANCEL_GROUP){
return false;
}
return true;
}性能优化
B类的服务压力相对没有那么大,性能往往不是瓶颈,但是并不意味着可以随便挥霍。
比如,Leads更新操作中,发现一个更新,只需要更新一个字段,但是使用的是全字段更新(有几十个字段),明显的浪费资源,所以新增了一个单字段更新的SQL。
//重构前用这个
UPDATE crm_leads SET GMT_MODIFIED = now()
, modifier = #{modifier}
, is_deleted = #{isDeleted}
, customer_id = #{customerId}
, reference_user_id = #{referenceUserId}
... 此处省略N多字段
, biz_code = #{bizCode}
where id = #{id} and tenant_id = #{tenantId} and IS_DELETED = 'n'
//重构后用这个
UPDATE crm_leads SET GMT_MODIFIED = now()
, customer_id = #{customerId}
where id = #{id} and tenant_id = #{tenantId} and IS_DELETED = 'n'
Tips:性能优化要扣细节,不要一提到性能,就上ThreadPool。
测试代码
看了大家的测试代码,大部分都写的很乱,没有结构化。
实际上,测试代码很容易结构化的,就是三个步骤:
- Prepare:准备数据,包括准备请求参数和数据清理
- Execute:执行要测试的代码
- Check:校验执行结果
下面是我写的创建Leads,但是客户没有创建过的测试用例:
@Test
public void testLeadsExistWithNoCustomer(){
//1\. Prepare
IcbuLeadsAddCmd cmd = getIcbuIMLeadsAddCmd();
String tenantId = "cn_center_10002404";
LeadsE leadsE = leadsRepository.getLeads(tenantId, cmd.getContactId());
if(leadsE != null) {
leadsE.setCustomerId(null);
leadsRepository.updateCustomerId(leadsE);
}
//2\. Execute
commandBus.send(cmd);
//3\. Check
leadsE = leadsRepository.getLeads(tenantId, cmd.getContactId());
Assert.assertEquals(leadsE.getCustomerId(), "179001");
}测试代码允许有重复,因为这样可以做到更好的隔离,不至于改了一个数据,影响到其他的测试用例。
Tips:PandoraBoot启动很慢,如果不是全mock的话,建议使用我写的TestContainer,这样可以提效很多。
本文作者:ali-frank
阅读原文
本文为云栖社区原创内容,未经允许不得转载。