Ceph 存储的体系结构
Ceph 存储由几个不同的守护进程组成,这些守护进程彼此之间是相互独立的,每一个组件提供特定的功能。
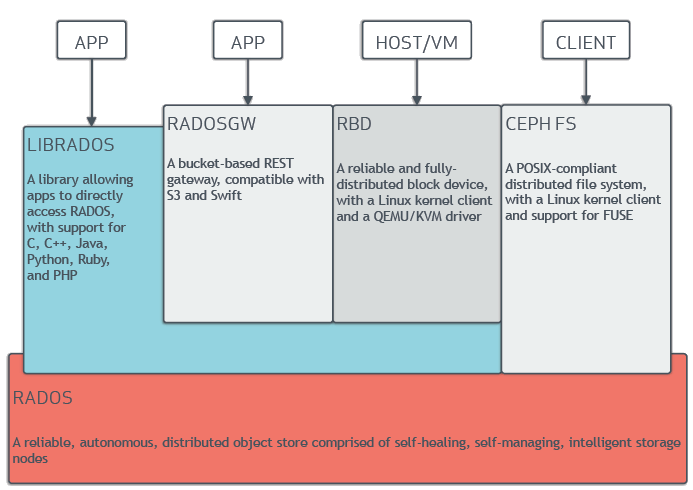
Ceph核心组件
-
RADOS(Reliable Autonomic Distributed Object Store 可靠、自动,分布式对象存储) 是ceph存储组件的基础。ceph 将一切都以对象的方式存储,RADOS就负责存储这些对象,而不考虑他们的数据类型。RADOS层组件确保数据的一致性,和可靠性。包括数据的复制,故障检测和恢复,数据在节点之间的迁移和再平衡。RADOS由大量的存储设备和节点集群组成。RADOS采用C++开发。
- LIBRADOS(基础库,又叫做RADOS库) 主要功能是对RADOS进行抽象和封装,并向上提供API,以便直接基于RADOS进行应用开发。RADOS是一个对象存储系统,LIBRADOS实现的是API是针对对象存储的功能。支持C,C++, Java, Python, Ruby 和PHP。同时,LIBRADOS还是RBD,RGW等服务的基础。
- RADOSGW(CEPH对象网关,也叫做RADOS网关RGW) 它提供了S3和Swift兼容的RESTful API的网关,支持多租户和openstack的身份验证。相对于LIBRADOS它提供的API抽象层次更高,能在使用类S3和Swift场景下进行更加便捷的管理。
-
RDB(Reliable Block Device) 提供了一个标准的块设备接口,对外提供块存储,它可以被映射,格式化,像其他磁盘一样挂载到服务器。常用于虚拟化场景下创建volume,云硬盘等。目前red Hat已经将RBD的驱动集成到KVM/QEMU中。
- CephFS (Ceph 文件系统) 是一个兼容POSIX的分布式文件系统。它使用MDS作为守护进程。libcephfs拥有本地Linux内核驱动程序支持,可以使用mount命令进行挂载操作。能与支持CIFS和SMB协议。
Ceph RADOS
RADOS是ceph 存储系统的核心,也称为ceph存储集群。ceph的所有优秀的特性都是由RADOS提供的,包括分布式对象存储,高可用性,自我修复和自我管理等。
RADOS 组件架构图:
RADOS 包含两个核心组件:Ceph Monitor 和Ceph OSD。
Ceph Monitor
Ceph Monitor 是负责监视整个集群的运行状态的, 为了实现高可用性,通常配置为一个小型的集群(一般是3个节点,集群通常是有一个leader和两个slave,当leader故障后集群通过选举产生新的leader,来保障系统的高可用性。)。
Monitor中的信息都是集群成员中的守护程序来提供的,包含了各个节点之间的状态,集群的配置信息。主要用于管理Cluster Map,Cluster Map是整个RADOS系统的关键数据结构,类似元数据信息。Mon中的Cluster Map 包含 Mon Map、OSD Map、PG Map、MDS Map和CRUSH等。
- mon Map: 记录了mon集群的信息和集群的ID. 命令
ceph mon dump - OSD Map: 记录了osd集群的信息和集群的ID. 命令
ceph osd dump - PG Map: pg的全称是placement group,中文译为放置组,是用于存放object的一个载体,pg的创建是在创建ceph存储池的时候指定的,同时跟指定的副本数也有关系,比如是3副本的则会有3个相同的pg存在于3个不同的osd上,pg其实在osd的存在形式就是一个目录,pg作为存储单元,pg的使用情况也反应了当前集群的存储状态。在集群中,PG有多种状态,不同的状态反应了集群当前的健康状态。 命令
ceph pg dump - CRUSH Map: 包含集群存储设备的信息,故障层次结构和存储数据是定义失败域规则信息。 命令
ceph osd crush dump - MDS map: 只有在使用Ceph FS时才会使用MDS,MDS是Ceph FS的元数据服务。集群中至少需要一个MDS的服务。
Ceph Monitor集群维护着各类Map数据,它本身并不提供客户端数据的存储服务,客户端和其他集群节点会定期的检查并更新Monintor维护的Map,在客户端进行读写数据时,都会请求Monitor提供Map数据,之后直接与OSD进行数据操作。
Ceph Monitor是一个轻量级的守护进程,通常情况下不需要消耗大量资源,通常会需要几个GB的磁盘空间来存放日志。
Ceph OSD
OSD是Ceph 存储的重要组件。OSD将数据以对象的方式存储到集群中各个节点的磁盘上,完成数据存储的绝大部分工作是由OSD 守护进程来实现的。
Ceph 集群中通常包含有多个OSD,对于任何读写操作,客户端从Ceph Monitor获取Cluster Map之后,客户端将直接与OSD进行I/O操作,而不再需要Monitor干预。这使得数据读写过程更加迅速,不需要其他额外层级的数据处理来增加开销。
OSD通常有多个相同的副本,每个数据对象都有一个主副本和若干个从副本,这些副本默认情况下分布在不同的节点上,当主副本出现故障时(磁盘故障或者节点故障),Ceph OSD Deamon 会选取一个从副本提升为主副本,同时,会产生以一个新的副本,这样就保证了数据的可靠性。
Ceph OSD 操作必须 在一个有效的Linux 分区上,文件系统可以是BTRFS,XFS或EXT4,推荐选择XFS。
journal 缓冲区
Ceph 在写入数据时,会先将数据写入一个单独的换成存储区域,再写到备用存储。该缓冲区域被称为journal,这个缓冲区可以在相同或单独磁盘作为OSD,或者不同的SSD磁盘上。默认情况下每隔5秒日志会向备用存储刷新数据,常见的日志大小是10G,但是分区越大越好。
当为journal提供一个高速缓存的SSD磁盘时,会显著提高CEPH 写入数据的性能。每个SSD磁盘最多给4个到5个OSD做日志,一旦超过这个限制将会出现性能瓶颈。
Ceph CRUSH 算法
CRUSH算法是Ceph 读写文件的核心,下图展示了使用CRUSH算法实现的数据读写和再平衡的流程:
Ceph 存储数据的流程
- 客户端通过调用API(librados,RGW,RBD,或者libcephfs)向Monitor 获取集群Map副本.
- 客户端通过集群Map得到Ceph集群的状态和配置信息,然后将客户端数据按照固定大小进行切割编号,形成多个对象。
- 通过一些列算法,对象会被确定写入哪个PG,以及对应的存储池pool,一个pool中含有多个PG,然后通过CRUSH规则获取所需的主OSD的位置。
- 一旦确定OSD的位置,客户端直接将数据写入主OSD.
- 数据被写入主OSD后,将执行数据复制,会在副本OSD中同步PG数据。
Pool是一个逻辑分区,包含了多个PG,同时,每一个Pool都是交叉分布在多个主机节点上的。
存储池的操作
存储池(POOL)是管理PG的逻辑分区,pool可以通过创建需要的副本数来保障数据的高可用性,在新的版本中,默认的副本数是3.
除此之外,我们可以还可以同使用SSD硬盘来创建faster池,使用pool来进行快照功能,还可以为访问pool的用户分配权限。
- 创建pool
ceph osd pool create {pool-name} {pg-number} {pgp-number} [replicated] [crush-ruleset-name] [expected-num-objects]
ceph osd pool create test-pool 9 # 创建一个名为test-pool的池,包含的gp数量为9- 查看当前的存储池信息
ceph osd lspools
rados lspools
ceph osd dump | grep -i pool # 查看副本以及详细信息- 设置副本数目(在早期版本中副本数目默认是2,在Firefly之后的版本中,副本数默认为3)
ceph osd pool set test-pool size 3 # 设置副本数目为3
ceph osd dump | grep -i pool # 查看副本数目详情- 给pool重命名
ceph osd pool rename test-pool pool-1 # 当前名称 目标名称
ceph osd lspools # 查看命名已经修改
- Ceph 池做数据快照
rados -p pool-1 put obj-1 /etc/hosts # 像池中添加对象obj-1和 文件 /etc/hosts
rados -p pool-1 ls # 查看池中的对象
# 给pool-1 池创建快照,命名为snapshot01
rados mksnap snapshot01 -p pool-1
# 插卡快照信息
rados lssnap -p pool-1
# 删除pool-1存储池中obj-test对象
rados -p pool-1 rm obj-test
# 查看对象的快照信息
# rados -p pool-1 listsnaps obj-test
obj-test:
cloneid snaps size overlap
1 1 5 []
# 恢复快照,指定存储池,对象名称,快照名
rados rollback -p pool-1 obj-test snapshot01
- 获取pool相关参数,size 或其他参数
ceph osd pool get pool-1 size
ceph osd pool get pool-1 {value}- 设置存储池的配置参数
ceph osd pool set pool-1 size 3- 删除池(删除池的时候将会删除快照),删除使用两次确认的方式
ceph osd pool delete pool-1 pool-1 --yes-i-really-really-mean-itCeph 数据管理
这里通过示例,展示ceph 管理数据的方式。
PG 的副本存储
创建一个存储池pool-1:
ceph osd pool create pool-1 8 8 # 创建存储池 pool-1,指定pg 和pgp的数量为 8 查看pool的ID:
[root@local-node-1 ~]# ceph osd lspools
1 .rgw.root
2 default.rgw.control
3 default.rgw.meta
4 default.rgw.log
8 pool-1查看pg分配所属的OSD:
[root@local-node-1 ~]# ceph pg dump|grep ^8|awk '{print $1 "\t" $17}'
dumped all
8.7 [0,2,1]
8.6 [2,1,0]
8.5 [2,1,0]
8.4 [1,2,0]
8.3 [2,0,1]
8.2 [2,0,1]
8.1 [0,2,1]
8.0 [0,1,2]
表明 0-7的pg都存为了3副本,分到不同的副本中。
文件存储
我们将hosts文件加入存储(这里已经添加pool):
[root@local-node-1 ~]# rados -p pool-1 put obj1 /etc/hosts
[root@local-node-1 ~]# rados -p pool-1 ls
obj1查看对象obj1和OSD的映射关系:
[root@local-node-1 ~]# ceph osd map pool-1 obj1
osdmap e72 pool 'pool-1' (8) object 'obj1' -> pg 8.6cf8deff (8.7) -> up ([0,2,1], p0) acting ([0,2,1], p0)
上述输出的含义:
- osdmap e72: OSD map的版本号 72 表示版本
- pool 'pool-1' (8): 池的名字为pool-1, ID 为8
- object 'obj1' : 对象名称
- pg 8.6cf8deff (8.7): pg 的编号,表示obj1 属于PG 8.7
- up ([0,2,1], p0): 表示PG的up 集合,包含osd 0,2,1
- acting ([0,2,1], p0): 表明osd 0,2,1 都在acting集合中,其中osd.0是主副本,OSD.2是第二副本,OSD.1是第三副本。
默认情况下,存放相同PG的副本会分布在不同的物理节点上。
恢复和动态平衡
默认设置下,当集群中有节点出现故障时,Ceph 会将故障节点的OSD标记为down,如果在300s内未恢复,集群就开始进行恢复状态。