AthenaX是一个流式分析平台,它可以让用户运行SQL来进行大规模可扩展的流式分析。由Uber开源,具备扩展到上百台节点处理日均千亿级别的实时事件。
架构图如下:
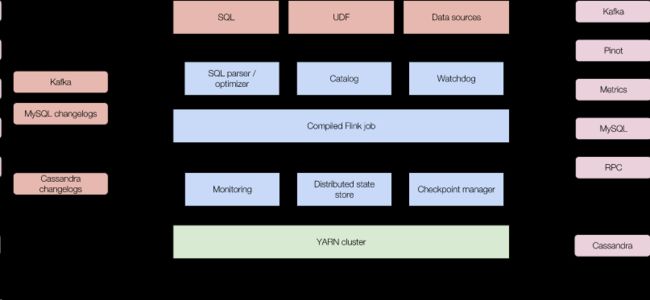
技术说明
构建在Apache Calcite以及Apache Flink之上;
采用YARN集群来管理Job
LevelDB作为持久化存储
Features
Streaming SQL
Filtering, projecting and combining streams
Aggregation on group windows over both processing and event time
User-defined functions (UDF), User-defined aggregation function (UDAF), and User-defined table functions (UDTF) (coming soon)
Efficient executions through optimizations and code generations
Mechanisms to automatically fail over across multiple data centers
Auto scaling for AthenaX jobs
核心技术点
athenax-backend
项目的后端服务实现,提供了一个运行时实例。其主要启动步骤分为两步:
启动一个web server,用来接收restful的各种服务请求;
这里的web server,事实上一个Glashfish(Java EE应用服务器的实现)中的grizzly(基于Java NIO实现的服务器)所提供的一个轻量级的http server,它也具备处理动态请求(web container,Servlet)的能力。
web server接收用户的RESTful API请求,这些API可以分成三类:
(1)Cluster: 集群相关的信息;
(2)Instance: Job运行时相关的信息;
(3)Job: 作业本身的信息;
RESTful API这块,AthenaX使用了当前比较流行的swagger这一API开发框架来提供部分代码(实体类/服务接口类)的生成。
启动了一个Server的Context(上下文),它封装了一些核心对象,是服务的具体提供者:
job store:一个机遇LevelDB的job元数据存储机制;
job manager:注意这与Flink的JobManager没有关系,这是AthenaX封装出来的一个对象,用于对SQL Job进行管理;
instance manager:一个instance manager管理着部署在YARN集群上所有正在被执行的job;
watch dog:提供了对job的状态、心跳的检测,以适时进行failover;
athenax-vm-compiler
三个component:
planer:计划器,该模块的入口,它会顺序调用parser、validator、executor,最终得到一个称之为作业编译结果的JobCompilationResult对象;
parser:编译器,这里主要是针对其对SQL的扩展提供相应的解析实现,主要是对Calcite api的实现,最终得到SqlNode集合SqlNodeList;
executor:真正完成所谓的”编译“工作,这里编译之所以加引号,其实只是借助于Flink的API得到对应的JobGraph;
这里,值得一提的是其”编译“的实现机制。AthenaX最终是要将其SQL Job提交给Flink运行时去执行,而对Flink而言JobGraph是其唯一识别的Job描述的对象,所以它最关键的一点就是需要得到其job的JobGraph。那么它是如何做到这一点的?
JobGraph的生成
它(JobCompiler)通过mock出一个利用Flink的Table&SQL API编写的Table&SQL 程序模板 :
StreamExecutionEnvironment execEnv = StreamExecutionEnvironment.createLocalEnvironment();
StreamTableEnvironment env = StreamTableEnvironment.getTableEnvironment(execEnv);
execEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
CompilationResult res = new CompilationResult();
try {
JobDescriptor job = getJobConf(System.in);
res.jobGraph(new JobCompiler(env, job).getJobGraph());
} catch (Throwable e) {
res.remoteThrowable(e);
}
核心在于上面的getJobGraph方法
JobDescriptor是其Job业务相关的信息,然后为其 动态设置 非固定部分:
input catalog:table source
udf: user defined table/scalar/agg function
sql: business sql
output catalog: sink
JobGraph getJobGraph() throws IOException {
StreamExecutionEnvironment exeEnv = env.execEnv();
exeEnv.setParallelism(job.parallelism());
this
.registerUdfs()
.registerInputCatalogs();
Table table = env.sql(job.sql());
for (String t : job.outputs().listTables()) {
table.writeToSink(getOutputTable(job.outputs().getTable(t)));
}
StreamGraph streamGraph = exeEnv.getStreamGraph();
return streamGraph.getJobGraph();
}
其中调用env.sql()这个方法说明它本质没能真正脱离Flink Table&SQL
设置完成之后,通过调用StreamExecutionEnvironment#getStreamGraph就可以自动获得JobGraph对象,因此JobGraph的生成还是由Flink 自己提供的,而AthenaX只需要拼凑并触发该对象的生成。
生成后会通过flink的yarn client实现,将JobGraph提交给YARN集群,并启动Flink运行时执行Job。
而具体的触发机制,这里AthenX采用了运行时执行构造命令行执行JobCompiler的方法,然后利用套接字+标准输出重定向的方式,来模拟UNIX PIPELINE,事实上个人认为没必要这么绕弯路,直接调用就行了。
解析器的代码生成
值得一提的是,parser涉及到具体的语法,这一块为了体现灵活性。AthenaX将解析器的实现类跟SQL语法绑定在一起通过fmpp(文本模板预处理器)的形式进行代码生成。
fmpp是一个支持freemark语法的文本预处理器。
athenax-vm-api
这个模块就是Athenax提供给用户的去实现的一些API接口,它们是:
function:各种函数的rich化(open/close方法对)扩展;
catalog:table / source、sink的映射;
sink provider:sink的扩展接口;
athennax-vm-connectors
开放给用户去扩展的连接器,目前只提供了kafka这一个连接器的实现。
总结
AthenaX代码量不大且不复杂,但是它提供了一个对Flink进行扩展以利用其运行时的一种机制。
---------------------
作者:vinoYang
来源:CSDN
原文:https://blog.csdn.net/yanghua_kobe/article/details/78573578
版权声明:本文为博主原创文章,转载请附上博文链接!