Clustering
Clustering中文译“聚类”,目的是将相似的东西分到一类。因为不需要带标签的数据进行训练学习,因而是一种无监督学习过程,需要和Classification(分类)区别开来。

Day 5 | K-Means - 1.19
K-means是最基本的聚类算法(baseline般的存在),以欧氏距离为特征把m维的数据点映射到欧氏空间中进行聚类。
算法的核心思想是根据数据初始化K个中心点(center),然后按样本点和中心点的距离将样本点划分到不同的类中。使得每个样本点到所在聚类中心的距离尽可能地小于到其他类中心的距离。而剩下的误差就是问题的不可分性以及算法的固有缺陷了。基于上述要求可以写出目标函数。优化时,令有---①。
由此可得K-means的伪代码:
1、随机选取k个中心点;
2、将每个数据点归类到离它最近中心点的类中;(固定更新)
3、固定,由①式更新;
4、重复2、3步优化J直到迭代至最大步数或者J收敛为止。
最后,总结一下K-means算法的一些特点:首先算法有简单,运算时间短的优点。但因为初始中心点的随机性只能收敛到局部最优,这是其最大的缺陷。所以K-means算法都需要重复多次试验再选取最优的结果。
K-means实现
Day 6 | K-Medoids & Hungarian algorithm - 1.21
K-means 与 K-medoids不同的地方在于中心点的选取。K-means算法的中心点相当于直接取同类数据的”均值“,这样对非数值类型的特征是不友好的。比如狗的品种(萨摩、柯基),距离是无法度量的。
而K-medoids的中心点相当于取样本的“中值”,其中心点将会从原样本点中产生,只要将K-means的欧式距离度量改为相似度度量,得目标函数--V为和的dissimilarity度量函数,可以用相似矩阵来实现,有点相对距离的意味。
总结:除了应用范围更广外,K-medoids还比K-means更好地消除outlier的影响。不过初始化中心点的方法同样决定其结果只能是局部最优。
Day 7 | GMM - 1.22
混合高斯模型是一种基于数据学习出概率密度函数的参数,是一种soft assignment。其好处是同时获得每个样本的cluster和assign到每个cluster的概率。所以除了用在clustering外,还能用于density estimation。对于风险较大的任务,算法能根据概率判断是否对决策有把握,在把握比较低的时候能拒绝参与决策。
介绍完背景,接着切入算法的原理。首先,m维向量的正态概率密度是长这样的,高斯混合分布为。贝叶斯分类器的最佳划分为--①。
优化上式其实相当于求出每个k类分布下最有可能的高斯分布参数(最大化似然)以及在每个混合高斯模型下可能性最大的K类(K的后验概率分布)。是应用EM算法解最大似然估计的一个具体例子,在原数据x不完整的情况下,引入隐变量k能“补全”缺少的信息解出似然函数。EM算法就是分别处理隐变量k(E步)以及模型参数(M步)的一个过程。即:
1、根据当前参数求①式样本关于k的后验概率(E步);
2、对似然函数分别求导更新(M步)
Day 8 | EM(Expectation Maximization)算法 - 1.24
EM算法是一种解决特殊最大似然问题的迭代方法。这类问题通常引入合适的隐变量来获得最大似然解,当估计中的很困难,而优化却容易得多时,此时EM算法就适用了。
推导过程
对数似然函数引入一个关于隐变量的分布q(Z)作分解:▲
是散度(非负的),所以肯定有,即是的下界。
E步
是固定的,易知与无关,为一个定值。这时可以令使得KL散度为0。▲
这时对数似然函数已经得到了很大的化简,是包含样本变量和隐变量的似然函数关于后验概率的期望。
M步
是固定的,对求导更新相当于对求导。更新时,若KL散度仍是0,则说明达到某一个局部最优解了,迭代可以停止了;一般KL散度变为非0,更新会提升对数似然的上界。
有时M步除了做最大似然之外,也可以引入先验概率做Maximum a Posterior(MAP)来做。而当似然函数求不出最大值时,还可以做Generalized EM(GEM),只需要能得到比旧值更好的结果就行。
Day 9 | 向量量化(Vector Quantization) - 1.26
VQ可以理解为:将一个向量空间中的点用其中的一个有限向量子集来进行编码(聚类后的索引总能起到压缩效果的)。
Day 1 | 谱聚类(Spectral Clustering)- 11.15
比起传统K-Means,谱聚类对数据分布的适应性更强,聚类效果优秀,计算量小同时实现起来也不复杂。
主要思想是把数据看作空间中的点,通过图论的无向图描述数据关系并通过矩阵分析进行“切图”聚类。
⚪无向权重图
主要由对称的邻接矩阵W和对角矩阵D描述。



⚪邻接矩阵
邻接矩阵常用KNN(K近邻)方法获取,为了保持对称性,一般加条件:

或者通过加核的方法处理点的邻接度,常用高斯核函数RBF

⚪拉普拉斯矩阵
拉普拉斯矩阵L=D-W,有良好的性质:对称,特征数都是实数,矩阵半正定以及以下关系:

▲另一个常用的形式是
⚪无向图切图


被切断的边的权值之和就是cut值。让子图内的点权重和大,子图间的点权重和小。最小化cut(A1,A2,..Ak)可实现,但会存在只切小权重边缘点的问题。

⚪RatioCut切图
为了解决上面的问题,RatioCut不仅最小化切图损失权重,还考虑最大化每个子图的个数(类似于平均权重)

引入指示向量(特征向量)hij(表示样本i属于j类)有
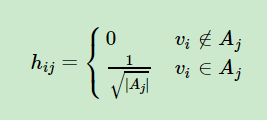


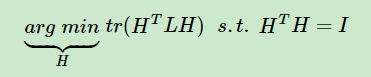
⚪Ncut切图
子图样本个数多并不意味子图的权重大(子图类内相似性大),所以Ncut采用子图的权重和vol(Ai)进行正规化:

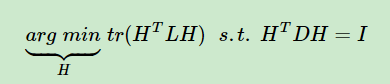
解的过程与RatioCut相近,不同的是。将D拆开有另一个表示形式:

*这里的指示向量相当于
是标准化拉普拉斯矩阵,即
最后,谱聚类还是有点缺点的:(1)若谱聚类的最终的维度非常高,聚类的效果以及运算时间也不友好;(2)谱聚类比较依赖相似矩阵,所取的相似矩阵不同会影响到聚类效果。
频谱切图
Optimize
目标函数有了,怎么解出结构矩阵H却是个NP hard。引入瑞利商-Rayleigh Quotient后可以巧妙地解目标函数,以Radio Cut为例:
相当于分别对每个向量求
⚪而Rayleigh quotient指出,的最大值和最小值分别在的最大特征值以及最小特征值取得,并且极值也在对应的其他特征值取得。由于,所以
分别求出的k个最小特征值对应的特征向量,就有的轮廓了。最后给这k个特征向量做Kmeans就能得到样本的聚类结果了。
Day 14 | Hierarchical Clustering - 2.1
Day 2 | 马尔可夫链(Markov Chains)- 11.23
Day 3 | 评估准则 - 12.8
转自维基百科

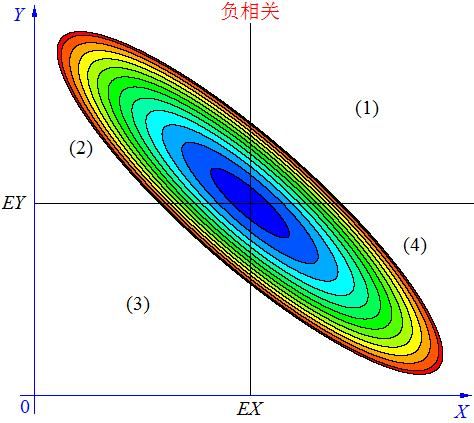
Day 4 | 协方差的意义 - 1.18
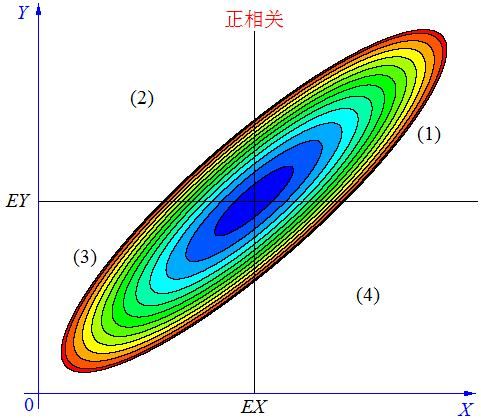
协方差Cov(X,Y)描述两个随机变量X和Y之间的相互关系,具体可以分为如下三种情况:
在图中的区域(1)中,有 X>EX ,Y-EY>0 ,所以(X-EX)(Y-EY)>0;
在图中的区域(2)中,有X
在图中的区域(3)中,有X
在图中的区域(4)中,有X>EX ,Y-EY<0 ,所以(X-EX)(Y-EY)<0。
平均来说,就是正相关的面积大部分分布在(1)(3),负相关的面积大部分分布在(2)(4)。
协方差的意义如同(1)(3)的面积减去(2)(4)的面积,说明X,Y的相关关系。
由此可看出方差是失去方向信息的协方差,只指示数据分布离平均值的离散程度。

Day 9 | t test & p-value - 1.25
Day 10 | Soft Thresholding - 1.29
Soft Thresholding又称软阈值,一般在稀疏规则化的文章中都会出现。
Soft Thresholding 有三种常用表达方式:
1、
2、
3、

Soft Thresholding 可以优化以下问题:
或
上式(第一项)相当于解的最小值,逐一对求导并令导数为0即可得到解为或
Day 11 | Dimesionality Reduction - 1.30
首先,关于特征“feature”有两种重要的处理方法-feature selection 和 dimensionality reduction。前者(选出重要的特征并抛弃不重要的特征)可以看作是后者(把高维向量映射成低维向量)的特例。
降维的通常目标是最大限度地降低数据的维度同时保留目标的重要信息。
PCA、LDA...
Day 12 | (瑞利商)Rayleigh Quotient - 1.31
瑞利商常用于优化拉普拉斯矩阵构成的算子,除了优化谱聚类外,还能优化PCA、Fisher LDA等结构相似的算子
1、普通瑞利商
可以看出对的幅值进行正则化既不影响的取值,也不改变的方向
可以转化为拉格朗日乘子问题
,
所以的极值为的特征值,对应的解为其特征向量。
普通瑞利商能解Ratio Cut和PCA:
2、泛化瑞利商
上式加上正则化约束后的解为
作变形,可得
泛化瑞利商能解Ncut和Fisher LDA(线性判别分析).
Day 13 | AUC & ROC - 3.1
ROC曲线全称为受试者工作特征曲线(Receiver operating characteristic curve)。最早运用实在军事上,雷达兵会难以区分敌机和飞鸟,每个雷达兵的预报标准(谨慎程度)不同,将他们漏报和错报的概率画到二维坐标上(纵轴为敏感性-对应准确预报概率,横轴为特异性-对应错报概率)。汇总后会发现预报性能分布在一条曲线上,对应于不同取阀值区分正负样本的性能。
从列联表中引出不同指标

减小判别正类的阀值,会同时提高准确率和误报率,这说明离左上角最近的点是这个系统的最佳性能。通常我们只关心上报的情况,所以以TPR为纵坐标和以TNR为横坐标即可画出ROC曲线,分别对应与收益和代价。

由于ROC曲线不能直接说明分类器的效果,所以就引入了数值AUC(Area Under Curve)来直观地衡量分类器的效果。AUC即ROC曲线下与坐标轴围成的面积。
用一句话来说明AUC的意义,就是:随机取一个正例和一个负例,分类器给正样本打分高于负样本的概率。
AUC判断分类器的几种情况:
1、AUC=1,是完美分类器,至少存在一个阀值能得出完美预测。
2、AUC=0.5,跟随机预测一样,模型没有预测价值。
3、AUC<0.5,比随机预测还差;但只要反预测,就能优于随机预测。
最后说一下ROC和AUC的一个很好的特性,测试集中的正负样本分布变化时,ROC曲线能保持稳定。如下图所示:

Reference
- zhwhong的文章():机器学习之分类性能度量指标 : ROC曲线、AUC值、正确率、召回率
Day 14 | 绝对中位差(MAD)- 3.15
绝对中位差是对单变量数值型数据样本偏差的鲁棒性测量,表示为
是数据点到中位数绝对偏差的中位数,比标准差的鲁棒性更佳。因为标准差使用距离的平方,偏差大的权重更大,因而异常值对其影响更大。而MAD能消除少量异常值的影响。
Day 15 | 维度灾难 - 3.19
维度灾难:随着维度的增加,样本将会在维度空间里变得越来越稀疏,而要取得足够覆盖范围的数据,就只能增大样本数量(指数级),否则只能陷入过拟合,导致预测性能下降。(比如总数为1000的属性空间中要求样本属性覆盖总体的60%,选定一个属性所需的样本数为600,选定两个属性需774个,选定三个属性则需要843个样本)
集成聚类评估
Day 16 | 算法集成聚类的集成效果分析 - 3.22
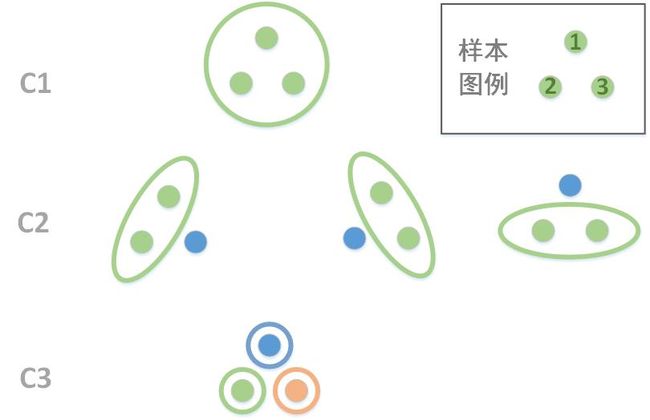
优秀的算法集成方法往往能发现数据的一致性并挖掘数据的互补信息,但是也存在引入冲突信息甚至得出错误结构的问题。关于这几种情况,通过下图一一介绍:
首先,为了简化分析,我们取局部结构进行对比,因为确保了局部结构的发掘也就逐渐确保了全局结构识别。因此,我们主要分析关于样本1、2的划分情况。
1、一致性:划分的子结果统一且正确或者错误的子结果相互抵消,子结果的集成增强了稳定性(如C1和C21或C22、C23、C3)
2、互补性:划分的子结果不统一,但是正确的子划分信号较强,带来了正确的互补信息(如C1和C22、C23、C3,这里没有显示强度)
3、矛盾性:划分的子结果不统一,正确和错误的子信号强度相当,混淆了正确的结构(同互补性)
4、错误性:错误的子信号掩盖了正确的子信号,导致判定的结构错误(同互补性)
Day 17 | 规范化互信息(NMI)- 4.9
首先,描述互信息I(X; Y)的一些性质:
(1) I(X; Y)≥0 (2)I(X; Y)=I(Y; X)
(3)X,Y独立时,I(X; Y)=0 (4)当X,Y能相互推出时,I(X; Y)=H(X)=H(Y)
其次,I(X; Y)的定义为
,实际上是更广泛的相对熵的特殊形式。如果X, Y不独立,可通过联合概率分布和边缘概率分布乘积的KL散度来判断他们是否接近独立,
这就是X和Y之间的互信息。同时它也能表示为自信息和条件熵的关系:
通俗地说,互信息可以看作知道y值而使得x不确定性的减少(即Y透露了多少关于X的信息量)因为X的熵H(X)指X的不确定度,H(Y|X)表示已知X的情况下,Y的不确定度。
互信息、条件熵和联合熵的关系图:
关于NMI的缺点:只考虑变量的分布而没有考虑变量的出现频率,如文本分类任务中判断一个词和某类的相关程度,但往往未考虑词频的影响。
Day 18 | *希尔伯特空间(Hilber Space) - 4.15(较散乱,有待梳理)
希尔伯特空间与线性空间有着不少的关联,可以将希尔伯特空间理解为:
把函数投影到函数空间(核函数)的一个点上,而这个点又能映射到一个无穷维的(特征函数)特征空间。最终,该特征空间的基底(特征函数向量)又能够重构出这个函数空间。
首先,需要介绍一下距离、范数以及内积。所有空间都有距离和角度的概念:
距离的定义要满足非负性、对称性和三角不等式三个条件;
范数的定义需要满足非负性、数乘性和三角不等式;
内积的定义也有对称性、数乘性和正定性;
内积可以导出范数,而范数也可以导出距离,同时内积还能导出角度。
其次,对一个函数按照以无穷小间隔采样就能将其表示为一个无穷维向量的形式,其内积可以定义为。
所以,具有线性结构且定义了内积的,具有完备性的无穷维空间就称为希尔伯特空间。
都知道一个矩阵可以进行特征值分解时,其特征向量构成了这n维空间的一组基底。
函数空间中的无穷维矩阵若满足:
正定性
对称性
则这个函数称为核函数,有特征函数,所有的特征函数就构成核函数空间的一组基地。
最后介绍再生希尔伯特空间 - RKHS
RKHS 是由核函数构成的空间,其中任意函数都可以由基底表示。将核函数的一个元素固定,其内积为,这就是RKHS的再生性。
Day 19 | Graph Embeddings - 4.16
Day 20 | L2 norm Regularization - 4.17
Day 21 | Lagrange Methods & KKT & 对偶问题 - 4.22
用于优化的Lagrange Multiplier(LM) 的缺点是收敛困难,在接近最优解的时候会有振荡。Augmented Lagrange Multiplier (ALM)加入二次偏差项,提高了Lagrange Function 的收敛性,但又会引入分解特性差的问题。所以有人提出Augmented lagrange + Alternating Direction Minimzation(ADMM),固定其他“方向”来优化其中一个“方向”,能进行二次项解耦并优化,进而保留了可分解性又能收敛。
⚪(Lagrange Multiplier)拉格朗日乘子法
拉格朗日乘子法能寻找多元函数在一组约束下的极值。通过引入拉格朗日乘子
⚪KKT 条件
⚪对偶问题
Day 22 | Pseudo Inverse 伪逆 - 4.28
在秩 的情况下,没有合适的左逆或者右逆矩阵来重构出单位矩阵。而阻碍求逆的因素在于零空间中的向量,所以采用伪逆矩阵是一种逼近单位矩阵的办法。
由于行列空间的秩都为,行空间中的点可以通过一一对应地映射到列空间的上,而列空间中的也可以通过伪逆矩阵映射回行空间中,分割开了零空间的影响。

伪逆可以通过SVD来求取。
Day 23 | Trace norm regularization - 5.20
低秩约束能应用在很多问题上,例如matrix completion。
低秩约束常用核范数 ,而
所以对有同样的低秩约束效果。
假设是原本的低秩矩阵,且有m 个非零项,。则低秩优化的问题写成:
*上式有个前提: ,C某个正数。
解上式常用SVT算法[cai, 2010],该算法能在一分钟内恢复低秩大样本(n=1000)的矩阵,且有稀疏的特性。算法具体如下:
是作用在奇异值上的软阈值函数,是步长序列。阈值和步长的设置见于后文。
最终收敛的条件为:
*奇异值阈值算子的迭代更新规则:
首先经验值取,再设奇异值数目,然后查看的前个奇异值是否有小于(最小的)的值,有就不用变更;否则更新,常取
步长的设法:一般能保证收敛,但其更新速度会很慢,作者建议采用