爬虫爬取网页信息的思路:发送网页端请求—>获取响应内容—>解析内容—> 获取想要的数据—>保存数据
这次我们要实现的是爬取静态网页的股票数据,首先是获取沪深A股的所有股票代码,再用这些股票代码获取相应股票的信息
东方财富网有所有个股的股票代码(沪深A股所有股票)
查看其网页源代码
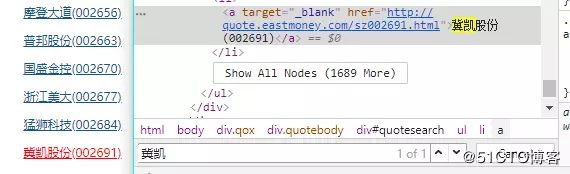
在网页源代码中可以搜索到相应的元素,判断其是数据是静态的
接下来是获取每只个股的信息,由于周六日没开市,东方财富网的个股信息没有显示

这里改用百度股市通(个股)
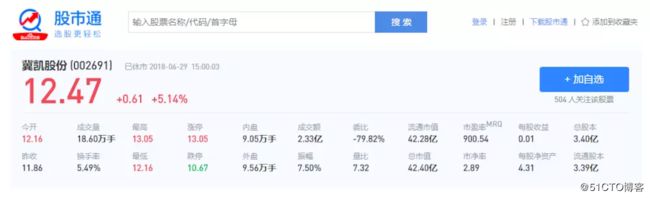
同样地检查元素可以发现个股的信息也是静态的
准备工作:通过pip导入beautifulsoup4模块
查看python目录下的文件 scripts/easy_install 存不存在
如果存在执行 easy_install.exe pip
安装成功后执行 pip install beautifulsoup4
首先获取所有股票的列表
一、获取东方财富网股票列表的网页源代码:
#--coding:utf-8 --
from urllib import request
对于python 3来说,urllib是一个非常重要的一个模块 ,可以非常方便的模拟浏览器访问互联网,对于python 3 爬虫来说, urllib更是一个必不可少的模块,它可以帮助我们方便地处理URL.
urllib.request是urllib的一个子模块,可以打开和处理一些复杂的网址
from bs4 import BeautifulSoup
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment|**
模拟浏览器爬取信息
在访问某些网站的时候,网站通常会用判断访问是否带有头文件来鉴别该访问是否为爬虫,用来作为反爬取的一种策略。
Python中urllib中的request模块提供了模拟浏览器访问的功能
url=r'http://quote.eastmoney.com/stocklist.html'
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
page = request.Request(url, headers=headers)
其中headers是一个字典,通过这种方式可以将爬虫模拟成浏览器对网站进行访问。
page_info=request.urlopen(page).read()
urllib.request.urlopen()方法实现了打开url,并返回一个 http.client.HTTPResponse对象,通过http.client.HTTPResponse的read()方法,获得response body,转码最后通过print()打印出来.
page_info=page_info.decode('GB2312',errors='ignore')
decode('GB2312',errors='ignore')用来将页面转换成GB2312-8的编码格式,否则会出现乱码,编码的格式取决于网页的编码形式,可在网页源代码head查看
获得网页的html代码后,自然就是要将我们所需要的部分从杂乱的html代码中分离出来。这里#使用Python中一种比较友好且易用的数据提取方式——BeautifulSoup
soup=BeautifulSoup(page_info,'html.parser')
将获取到的内容转换成BeautifulSoup格式,并将html.parser作为解析器,这是Python标准库中的解析器
用开发者查看网页源码发现股票代码包含在标签中
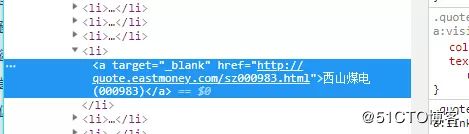
股票代码
由于百度股市通个股的网址信息使用的是完整的股票代码,深圳交易所的代码以sz开头,上海交易所的代码以sh开头,股票的数字有6位构成,因此我们要从a标签的链接中获取股票代码,而不是直接获取a标签的文本数据。
#从获取的内容中找到所有a标签
cnt=soup.find_all('a')
import re
#储存完整股票代码
lst=[]
#for循环历遍获取的a标签
for i in cnt:
try:
#获取a标签中的链接
href=i.attrs['href']
#正则表达式提取完整的股票代码
lst.append(re.findall(r'[s][hz]\d{6}',href)[0])
#这里[0]的作用是把获取到的列表转化为字符串添加到列表中
except:
continue
对文件操作,把获取的股票代码列表写入文档中,打开的文件一定要关闭,否则会占用相当大的系统资源,python中的with语句可以帮我们自动调用close()而不需要我们写出来,'w'以只写的方式打开文件,如果文件存在的话会先删除再重新创建
#写入D盘d.txt文件
with open(r'D:d.txt','w') as file:
file.write(str(lst))

二、获取股票信息
首先查看股票信息的网页源码
个股信息
百度股票网的网址为:由于平台文章限制请自行查找
个股信息的网址为:由于平台文章限制请自行查找
想要获取每只个股的网址只需要历遍股票代码列表,再与首页网址拼接即可,代码如下
stockUrl='https://gupiao.baidu.com/stock/'
接下来是通过网址获取网页html数据,解析获取股票信息
#历遍股票代码列表构造个股网址
count=0
for stock in lst:
url=stockUrl+stock+'.html'
try:
#获取个股网页html代码
page = request.Request(url, headers=headers)
page_info=request.urlopen(page).read()
page_info=page_info.decode('utf-8','ignore').replace(u'\xa9', u'')
#直接解码这里会报错,原因是©不能直接解码,这里将©替换成空格
if page_info=='':
continue
#解析网页内容
soup=BeautifulSoup(page_info,'html.parser')
#字典储存股票信息
infoDict = {}
#查找包含个股信息的div标签
stockInfo = soup.find('div',attrs={'class':'stock-bets'})
#查找股票名字存入字典
name = stockInfo.find_all(attrs={'class':'bets-name'})[0]
infoDict.update({'股票名称': name.text.split()[0]})
#split()对字符串进行切片,去除后面的空格
#股票的其他信息存放在dt和dd标签中,查找标签
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
#把获得的键和值按键值对的方式村放入字典中
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
#字典中的个股信息写入文本文件中
with open(r'D:f.txt', 'w') as f:
f.write( str(infoDict) + '\n' )
count = count + 1
#打印当前进度
print("\r当前进度: {:.2f}%".format(count100/len(lst)),end="")
except:
count = count + 1
print("\r当前进度: {:.2f}%".format(count100/len(lst)),end="")
continue
由于股票信息太多,这里只爬取其中一百只股票的信息爬取结果如下:

整个实现过程的完整代码如下:
from urllib import request
from bs4 import BeautifulSoup
url = r'http://quote.eastmoney.com/stocklist.html'
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
page = request.Request(url, headers=headers)
page_info=request.urlopen(page).read()
page_info=page_info.decode('GB2312',errors='ignore')
soup=BeautifulSoup(page_info,'html.parser')
cnt=soup.find_all('a')
import re
lst=[]
for i in cnt:
try:
href=i.attrs['href']
lst.append(re.findall(r'[s][hz]\d{6}',href)[0])
except:
continue
stockUrl='https://gupiao.baidu.com/stock/'
count=0
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
for stock in lst[350:400]:
url=stockUrl+stock+'.html'
try:
page = request.Request(url, headers=headers)
page_info=request.urlopen(page).read()
page_info=page_info.decode('utf-8','ignore').replace(u'\xa9', u'')
if page_info=='':
continue
soup=BeautifulSoup(page_info,'html.parser')
infoDict = {}
stockInfo = soup.find('div',attrs={'class':'stock-bets'})
name = stockInfo.find_all(attrs={'class':'bets-name'})[0]
infoDict.update({'股票名称': name.text.split()[0]})
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
with open(r'D:f.txt', 'a') as f:
f.write( str(infoDict) + '\n' )
count = count + 1
print("\r当前进度: {:.2f}%".format(count100/len(lst[:100])),end="")
except:
count = count + 1
print("\r当前进度: {:.2f}%".format(count100/len(lst[:100])),end="")
continue