C#和VB.NET中的LINQ提供了一种与SQL查询类似的“对象查询”语言,对于熟悉SQL语言的人来说除了可以提供类似关联、分组查询的功能外,还能获取编译时检查和Intellisense的支持,使用Entity Framework更是能够自动为对象实体的查询生成SQL语句,所以很受大中型信息系统设计者的青睐。
IEnumerable这个接口可以说是为了这个特性“量身定制”,再加上微软提供的扩展(Extension)方法和Lambda表达式,给开发者带来了无穷的便利。本人在最近的开发工作中使用了大量的这种特性,同时在调试过程中还遇到了一个小问题,那么正好趁此机会好好研究一下相关原理和实现。
先从一个现实的例子开始吧。假如我们要做一个商品检索功能(这只是一个例子,我当然不可能把公司的产品也业务在这里贴出来),其中有一个检索条件是可以指定厂家的名称并进行模糊匹配。厂家的包括两个名称:注册名称和一般性名称,我们只按一般性名称进行检索。当然你可以说直接用SQL查询就行了,但是我们的系统是以实体对象为核心进行设计的,厂家的数量也不会太多,大概1000条。为了不增加系统的复杂性,只考虑使用现有的数据访问层接口进行实现(按过滤条件获取商品,以及获取所有厂商),这时LINQ的便捷性就体现出来了。
借助IEnumerable接口和其辅助类,我们可以写出以下代码:
public GoodsListResponse GetGoodsList(GoodsListRequest request)
{
//从数据库中按商品类别获取商品列表
IEnumerable
//用户指定了商品名检索字段,进行模糊匹配
//如果没有指定,则不对商品名进行过滤
if (!String.IsNullOrWhiteSpace(request.GoodsName))
{
request.GoodsName = request.GoodsName.Trim().ToUpper();
//按商品名对 goods 中的对象进行过滤
//生成一个新的 IEnumerable
goods = goods.Where(g => g.GoodsName.ToUpper().Contains(request.GoodsName));
}
//如果用户指定的厂商的检索字段,进行模糊匹配
if (!String.IsNullOrWhiteSpace(request.ManufactureName))
{
request.ManufactureName = request.ManufactureName.Trim().ToUpper();
//只提供了获取所有厂商的列表方法
//取出所有厂商,筛选包含关键字的厂商
IEnumerable
manufactures = manufactures.Where(m => m.Name.GeneralName.ToUpper()
.Contains(request.ManufactureName));
//取出任何符合所匹配厂商的商品
goods = goods.Where(g => manufactures.Any(m => m.Id == g.ManufactureId));
}
GoodsListResponse response = new GoodsListResponse();
//将 goods 放到一个 List
response.GoodsList = goods.ToList();
return response;
}
假如不使用IEnumerable这个接口,所实现的代码远比上面复杂且难看。我们需要写大量的foreach语句,并手工生成很多中间的 List 来不断地筛选对象(你可以尝试把第二个if块改写成不用IEnumerable接口的形式)。
看上去一切都很和谐,但是上面的代码有一个隐含的bug,这个bug也是今天上午困扰了我许久的一个问题。
运行程序,当我不输入厂商检索条件的时候,程序运行是正确的。但当我输入一个厂商的名字时,系统抛出了一个空引用的异常。咦?为什么会有空引用呢?我输入的厂商是数据库中不存在的厂商,因此我觉得问题可以出在goods = goods.Where(g => manufactures.Any(m => m.Id == g.ManufactureId)) 这句话上。既然manufactures是空的,那么是不是意味着我不能调用其 Any 方法呢(lambda表达式中的部分)。于是我改写成以下形式:
if (manufactures != null)
//取出任何符合所匹配厂商的商品
goods = goods.Where(g => manufactures.Any(m => m.Id == g.ManufactureId));
还是不行,那么我对manufactures判断其是否有元素,就调用其无参数的Any方法,这时问题依旧:
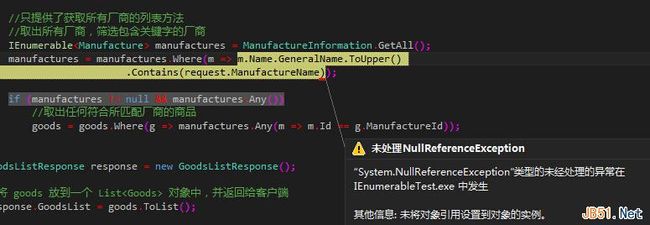
聪明的你肯定已经看出问题出在哪了,因为Visual Studio已经提示得很清楚了。但我当时还局限在“列表为空”这个框框中,因此迟迟不能发现原因。出错是发生在 manufactures.Any() 这句话上,而我已经判断了它不为空啊,为什么还会抛错呢?
后来叫了一个同事帮我看,他说的四个字一下子就提醒了我“延迟计算”。哦,对!我怎么把这个特性给忘了。在最初的代码中(就是没有对 manufactures 为空进行判断),出错是发生在 goods.ToList() 这句话时,而图上的那个代码段出错是发生在调用Any()方法时(图中的灰色部分),而我单步跟踪到 Any() 这句话上时,出错的语句跳到 Where 子句(黄色部分),说明知道访问 Any 方法时lambda表达式才被调用。
那么很显然是 Where 语句中这个 predicate 有问题:Manufacture的Name字段可能为空(数据库中存在这样的数据,所以导致在 translate 的时候Name字段为空),那么改写成以下形式就能解决问题,当然我们不用对 manufactures 列表进行为空的判断:
manufactures = manufactures.Where(m => m.Name != null &&
m.Name.GeneralName.ToUpper().Contains(request.ManufactureName));
在此要感谢那位同事看出了问题所在,否则我不知道还得郁闷多久。
我之前在使用 LINQ 语句的时候知道它的延迟计算特性,但是没有想到从根本上自 IEnumerable 的扩展方法就有这个特性。那么很显然,C#的编译器只是把 LINQ 语句改写成类似于调用 Where、Select之类的扩展方法,延迟计算这种特性是 IEnumerable 的扩展方法就支持的!我之前一直以为我每调用一次 Where 或者 Select(其实我SelectMany用得更多),就会对结果进行过滤,现在看来并不是这样。
即使是使用 Where 等扩展方法, 执行这些 predicate 的时间是在 foreach 和 ToList 的时候才发生。
为什么会这样呢?看样子这完全不应该呀?Where子句的返回值就是一个IEnumerable的迭代器,按道理应该已经筛选了对象啊?为了彻底搞清楚这个问题,那么方法很明显――看 .NET 的源代码。
Where
好了,来看下代码吧。IEnumerable的扩展方法都在 Enumerable 这个静态类中,Where方法的实现代码如下:
public static IEnumerable
if (source == null) throw Error.ArgumentNull("source");
if (predicate == null) throw Error.ArgumentNull("predicate");
if (source is Iterator
if (source is TSource[]) return new WhereArrayIterator
if (source is List
return new WhereEnumerableIterator
}
很显然,M$会用到 source 的类型,根据不同的类型返回不同的 WhereXXXIterator。等等,这就意味着Where方法返回的不是IEnumerable。从这里我们就可以清晰地看到M$其实是包装了一层,那么显而易见,应该是只记录了一个委托。这些WhereXXXIterator都是派生自 Iterator 抽象类,这个类实现了 IEnumerable
我们暂时不看 Iterator 类的一些细节,继续看 WhereListIterator 的 Where 方法。这个方法在基类是抽象的,因此在这里实现它:
public override IEnumerable
return new WhereListIterator
}
CombinePredicates是Enumerable静态类提供的扩展方法,不过它不是public的,只有在内部才能访问:
static Func
return x => predicate1(x) && predicate2(x);
}
自然,WhereListIterator 有几个字段:
List
Func
List
这样,相信大家都已经知道了Where的工作原理,简单地总结一下:
1.当我们创建了一个 List 后,调用其定义在 IEnumerable 接口上的 Where 扩展方法,系统会生成一个 WhereListIterator 的对象。这个对象把 Where 子句的 predicate 委托保存并返回。
2.再次调用 Where 子句时,对象其实已经变成 WhereListIterator类型,此后再次调用 Where 方法时,会调用 WhereListIterator.Where 方法,这个方法把两个 predicate 合并,之后返回一个新的 WhereListIterator。
3.之后的每一次 Where 调用都是执行第2步操作。
可以看出,在调用 Where 方法时,系统只是记录了 predicate 委托,并没有回调这些委托,所以此时自然而然就不会产生新的列表。
当遇到foreach语句时,会需要生成一个 IEnumerator 类型的对象以便枚举,此时就开始调用 Iterator 的 GetEnumerator 方法。这个方法只有在基类中定义:
public IEnumerator
if (threadId == Thread.CurrentThread.ManagedThreadId && state == 0) {
state = 1;
return this;
}
Iterator
duplicate.state = 1;
return duplicate;
}
在获取迭代器的时候要考虑并发的问题,如果多个线程都在枚举元素,同时使用一个迭代器肯定会发生混乱。M$的实现方法很聪明,对于同一个线程只使用一个迭代器,当发现是另一个线程调用的时候直接克隆一个。
MoveNext方法在子类中定义,WhereListIterator的实现如下:
public override bool MoveNext() {
switch (state) {
case 1:
enumerator = source.GetEnumerator();
state = 2;
goto case 2;
case 2:
while (enumerator.MoveNext()) {
TSource item = enumerator.Current;
if (predicate(item)) {
current = item;
return true;
}
}
Dispose();
break;
}
return false;
}
switch语句写得不容易看懂。在获取迭代器后,逐个进行 predicate 回调,返回满足条件的第一个元素。当遍历结束后,如果迭代器实现了 IDispose 接口,就调用其 Dispose 方法释放非托管资源。之后设置基类的 state 属性为-1,这样今后就访问不到这个迭代器了,需要重新创建一个。
至此,终于看到只有在迭代时才进行计算的缘由了。其他的一些Iterator大体上都是类似的,只是MoveNext的实现方式不一样罢了。至于M$为什么要单独为 List 和 Array 写一个单独的类,对于数组来说可以直接根据下标访问下一个元素,这样就可以避免访问迭代器的 MoveNext 方法,可以提高一点效率。但对于列表来说,其实现方式和普通的类相同,估计是首先想使用不同的实现后来发现不好吧。
其他的扩展方法,比如Select、Repeat、Reverse、OrderBy之类的好像也能链式调用,并且可以不限顺序任意调用多次。这又是怎么实现的呢?
我们先来看Select方法。类似Where方法,Select也定义了对应的三个Iterator:WhereSelectListIterator、WhereSelectArrayIterator和WhereSelectEnumerableIterator。每一种都定义了Select和Where方法:
public override IEnumerable
return new WhereSelectListIterator
}
public override IEnumerable
return new WhereEnumerableIterator
}
CombineSelectors的代码如下:
static Func
return x => selector2(selector1(x));
}
这样子就把Select和Where连起来了。本质上,运行时的类型在WhereXXXIterator和WhereSelectXXXIterator之间进行变换,每次都产生一个新的类型。
你可能会觉得对于每一种方法,M$都定义了一个专门的类,比如OrderByIterator等。但这样做会引起类的爆炸,同时每一种Iterator为了兼容其他的类这样要重复写的东西简直无法想象。微软把这些函数分成了两类,第一类是直接调用迭代器,列举如下:
1.Reverse:生成一个Buffer对象,倒序输入后返回 IEnumerable 类型的迭代器。
2.Cast:以object类型取迭代器中的元素并转型yield return。
3.Union、Ditinct:生成一个Set类型的对象,这个对象会访问迭代器。
4.Concat、Zip、Take、TakeWhile、Skip、SkipWhile:yield return。
很显然,调用这些方法会导致访问迭代器,这样 predicate 和 selector 就会开始进行回调(如果是WhereXXXIterator或WhereSelectXXXIterator类型的话)。当然,访问聚集函数或者First之类的方法显而易见会导致列表进行迭代,这里不多说明了。
第二种就是微软进行特殊处理的 Join、GroupBy、OrderBy、ThenBy。这几个方法是 LINQ 中的核心,偷懒怎么行?我已经写累了,相信各位看官也累了。但是求知心怎么会允许我们休息呢?继续往下看吧。
先从最熟悉的排序开始。OrderBy方法最简单的重载如下(顺带一提,方法签名看似非常复杂,其实使用起来很简单,因为Visual Studio会自动帮你匹配泛型参数,比如 goods = goods.OrderBy(g => g.GoodsName);):
public static IOrderedEnumerable
哇塞,返回值终于不是IEnumerable了,这个IOrderedEnumerable很明显也是IEnumerable继承过来的。在实现上,OrderedEnumerable
OrderBy扩展方法会返回一个OrderedEnumerable类型的对象,这个类对外公开了 GetEnumerator 方法:
public IEnumerator
Buffer
if (buffer.count > 0) {
EnumerableSorter
int[] map = sorter.Sort(buffer.items, buffer.count);
sorter = null;
for (int i = 0; i < buffer.count; i++) yield return buffer.items[map[i]];
}
}
OK,重点来了:OrderBy也是进行延时操作!也就是说直到调用 GetEnumerator 之前,还是不会回调前面的 predicate 和 selector。这里的排序算法只是一个简单的快速排序算法,由于不是重点,代码省略。
到这里估计有些人已经晕了,所以需要再次进行总结。用一个例子来说明,假如我写了如下这样的代码,应该是怎么工作的呢(代码仅仅是为了说明,没有实际的意义)?
goods = goods.OrderBy(g => g.GoodsName);
goods.Where(g => g.GoodsName.Length < 10);
执行完第一句代码后,类型变成了 OrderedEnumerable ,那么又来一个 Where,情况会怎么样呢?
由于 OrderedEnumerable 没有定义 Where 方法,那么又会调用 IEnumerable 的 Where 方法。此时会发生什么呢?由于类型不是 WhereXXXIterator,那么…… 对!那么会生成一个 WhereEnumerableIterator,此时 List 这个信息就已经丢失了。
有个疑问,我接下来再次调用 Where,此时这个 Where 语句并不知道之前的一些 predicate,在接下来的迭代过程中,怎么进行回调呢?
不要忘了,每一个类似这种类型(Enumerable、Iterator),都有一个 source 字段,这个字段就是链式调用的关键。OrderedEnumerable 类型对象在初始的过程中记录了 WhereListIterator 这个类型对象的引用并存入 source 字段中,在接下来的 Where 调用里,新生成的 WhereEnumerableIterator 类型对象中,又将 OrdredEnumerable 类型的对象存入 source 中。之后在枚举的过程中,会按照如下步骤开始执行:
1.枚举时类型是 WhereEnumerableIterator,进行枚举时,首先要得到这个对象的 Enumerator。此时系统调用 source 字段的 GetEnumerator。正是那个不太好理解的 switch 语句,曾经一度被我们忽略的 source.GetEnumerator() 在此起了重要的作用。
2.source 字段存储的是 OrderedEnumerator 类型的对象,我们参考这个对象的 GetEnumerator 方法(就是上面那个带 Buffer 的),发现它会调用 Buffer 的构造方法将数据填入缓冲区。Buffer 的构造方法代码我没有列出,但是其肯定是调用其 source 的枚举器(事实上如果是集合会调用其 CopyTo)。
3.这时 source 字段存储的是 WhereListIterator 类型对象,这个类的行为在最开始我们分析过:逐个回调 predicate 和 selector 并 yield return。
4.最后,前面的迭代器生成了,在 MoveNext 的过程中,首先回调 WhereEumerableIterator 的委托,再继续取 OrderedEnumerable 的元素,直至完成。
看,一切都是如此地“顺理成章”。都是归功于 source 字段。至此,我们已经几乎了解了 IEnumerable 的全部玄机。
对了,还有 GroupBy 和 Join 没有进行说明。在此简单提一下。
这两个方法的基础是一个称之为 LookUp 的类。LookUp表示一个键到多个值的集合(比较Dictionary),在实现上是一个哈希表对应到可以扩容的数组。GroupBy 和 Join 借助 LookUp 实现对元素的分组与关联操作。GroupBy 语句使用了 GroupEnumerator,其原理和上面所述的 OrderedEnumerator 类似,在此不再赘述。如果对 GroupBy 和 Join 的具体实现感兴趣,可以自行参看源代码。
好了,这次关于 IEnumerable 的研究总算告一段落了,我也总算是弄清了其工作原理,解答了心中的疑虑。另外可以看到,在研究的过程中要有耐心,这样事情才会越来越明朗的。