Apache Kafka 是一个高吞吐量分布式消息系统,由LinkedIn开源。引用官网对kafka的介绍:“Apache Kafka is publish-subscribe messaging rethought as a distributed commit log.” “publish-subscribe”是kafka设计的核心思想,也是kafka最具特色的地方。publish在kakfa中是一个producer的角色,subscribe是consumer,就像我们生活中的一样,生产商生产出来的产品,消费者一般不能够直接去工厂购买,还需要一个代理经销商,所以同样的在kafka的生态系统中,有一个broker的角色。所以kafka的生态系统大致可以表述如下:
"producer——>broker<——consumer"
大致的介绍就这么多,具体的大家可以移步官网: http://kafka.apache.org/
接下来是老生常谈的问题:为什么要用kafka?kafka适用什么样的场景?我先和大家分享一下自己再项目中的使用总结,有其他想法的同学欢迎补充:
使用kafka的理由:
1.分布式,高吞吐量,速度快(kafka是直接通过磁盘存储,线性读写,速度快:避免了数据在JVM内存和系统内存之间的复制,减少耗性能的对象创建和垃圾回收)
2.同时支持实时和离线两种解决方案(相信很多项目都有类似的需求,这也是Linkedin的官方架构,我们是一部分数据通过storm做实时计算处理,一部分到hadoop做离线分析)。
3.open source (open source 谁不喜欢呢)
4.源码由scala编写,可以运行在JVM上(笔者对scala很有好感,函数式语言一直都挺帅的,spark也是由scala写的,看来以后有空得刷刷scala)
使用场景:
笔者主要是用来做日志分析系统,其实Linkedin也是这么用的,可能是因为kafka对可靠性要求不是特别高,除了日志,网站的一些浏览数据应该也适用。(只要原始数据不需要直接存DB的都可以)
下面就简单的介绍一下kafka集群的搭建过程:
准备环境:至少3台的linux server(笔者是准备了5台redhat版本的cloud server)
第一步:安装JDK/JRE
第二步:安装Zookeeper(kafka自带有zookeeper服务,但是建议大家最好单独建立一个zookeeper集群,可以和其他应用共享,也便于管理)
zookeeper的安装,大家可以参考我的另一篇博文:http://bigcat2013.iteye.com/blog/2175538
第三步:下载kafka : http://kafka.apache.org/downloads.html (最好下载scala预编译好的package,例如我下的是kafka_2.10-0.8.1.1.tgz,意思就是用scala 2.10预编译好的0.8.1.1版本)
第四步:上传安装包到服务器(可以通过WinSCP等)
第五步:使用 " tar -xzvf kafka_2.10-0.8.1.1.tgz "来 解压安装包 :
解压后的目录结构:
第六步 :修改配置文件
简答配置的话修改/config/server.properties 就可以了
需要配置的属性有:broker.id(标示当前server在集群中的id,从0开始),port,host.name(当前的server host name),zookeeper.connect(连接的zookeeper集群),log.dirs(log的存储目录,记得对应的去建立这个目录)等,其他的一些配置可以看相应的注释:
第七步:通过“scp -r ”把配置好的kafka目录copy到其他几台server上:
第八步:修改每台server对应的配置文件,主要是修改其中的broker.id 和 host.name 属性:
broker.id从0开始递增,每台server必须唯一
第九步: 先启动zookeeper集群,再启动kakfa集群
kafka启动命令: sudo nohup ./bin/kafka-server-start.sh config/server.properties &
第十步:集群启动成功后,可以试着创建topic,在一台server上创建producer,另外一台创建consumer,从producer上发送信息,看consumer是否能接收到,以验证集群对否成功。
创建topic: sudo ./bin/kafka-topics.sh -zookeeper server1:2181,server2:2181,server3:2181 -topic test -replication-factor 2 -partitions 5 -create
查看topic:sudo ./bin/kafka-topics.sh -zookeeper server1:2181,server2:2181,server3:2181 -list
创建producer:sudo ./bin/kafka-console-producer.sh -broker-list kafkaServer1:9092,kafkaServer2:9092,kafkaServer3:9092 -topic test
创建consumer:sudo ./bin/kafka-console-consumer.sh -zookeeper server1:2181,server2:2181,server3:2181 - from-begining -topic test
通过在创建好的producer控制台输入信息,在consumer的控制台检测输出来测试,如果可以同步接受到信息就说明简单的kakfa 集群搭好了,另外可以根据项目的实际需求进一步做配置。
Kafka集群配置比较简单,为了更好的让大家理解,在这里要分别介绍下面三种配置
单节点:一个broker的集群
单节点:多个broker的集群
多节点:多broker集群
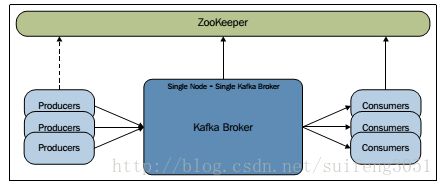
一、单节点单broker实例的配置
1.首先启动zookeeper服务
Kafka本身提供了启动zookeeper的脚本(在kafka/bin/目录下)和zookeeper配置文件(在kafka/config/目录下),首先进入Kafka的主目录(可通过 whereis kafka命令查找到):
[root@localhost kafka-0.8]# bin/zookeeper-server-start.sh config/zookeeper.properties
zookeeper配置文件的一些重要属性:
# Data directory where the zookeeper snapshot is stored.
dataDir=/tmp/zookeeper
# The port listening for client request
clientPort=2181
默认情况下,zookeeper服务器会监听 2181端口,更详细的信息可去zookeeper官网查阅。
2.启动Kafka broker
运行kafka提供的启动kafka服务脚本即可:
[root@localhost kafka-0.8]# bin/kafka-server-start.sh config/server.properties
broker配置文件中的重要属性:
# broker的id. 每个broker的id必须是唯一的.
Broker.id=0
# 存放log的目录
log.dir=/tmp/kafka8-logs
# Zookeeper 连接串
zookeeper.connect=localhost:2181
3.创建一个仅有一个Partition的topic
[root@localhost kafka-0.8]# bin/kafka-create-topic.sh --zookeeper localhost:2181 --replica 1 --partition 1 --topic kafkatopic
4.用Kafka提供的生产者客户端启动一个生产者进程来发送消息
[root@localhost kafka-0.8]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic kafkatopic
其中有两个参数需要注意:
broker-list:定义了生产者要推送消息的broker地址,以
topic:生产者发送给哪个topic
然后你就可以输入一些消息了,如下图:

5.启动一个Consumer实例来消费消息
[root@localhost kafka-0.8]# bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic kafkatopic --from-beginning
当你执行这个命令之后,你便可以看到控制台上打印出的生产者生产的消息:
和消费者相关的属性配置存放在Consumer.properties文件中,重要的属性有:
# consumer的group id (A string that uniquely identifies a set of consumers
# within the same consumer group)
groupid=test-consumer-group
# zookeeper 连接串
zookeeper.connect=localhost:2181
二、单节点运行多broker实例

1.启动zookeeper
和上面的一样
2.启动Kafka的broker
要想在一台机器上启动多个broker实例,只需要准备多个server.properties文件即可,比如我们要在一台机器上启动两个broker:
首先我们要准备两个server.properties配置文件
server-1
brokerid=1
port=9092
log.dir=/temp/kafka8-logs/broker1
server-2
brokerid=2
port=9093
log.dir=/temp/kafka8-logs/broker2
然后我们再用这两个配置文件分别启动一个broker
[root@localhost kafka-0.8]# env JMX_PORT=9999 bin/kafka-server-start.sh config/server-1.properties
[root@localhost kafka-0.8]# env JMX_PORT=10000 bin/kafka-server-start.sh config/server-2.properties
可以看到我们启动是为每个broker都指定了不同的JMX Port,JMX Port主要用来利用jconsole等工具进行监控和排错
3.创建一个topic
现在我们要创建一个含有两个Partition分区和2个备份的broker:
[root@localhost kafka-0.8]# bin/kafka-create-topic.sh --zookeeper localhost:2181 --replica 2 --partition 2 --topic othertopic
4.启动Producer发送消息
如果我们要用一个Producer发送给多个broker,唯一需要改变的就是在broker-list属性中指定要连接的broker:
[root@localhost kafka-0.8]# bin/kafka-console-producer.sh --broker-list localhost:9092,localhost:9093 --topic othertopic
如果我们要让不同的Producer发送给不同的broker,我们也仅仅需要为每个Producer配置响应的broker-list属性即可。
5.启动一个消费者来消费消息
和之前的命令一样
[root@localhost kafka-0.8]# bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic othertopic --from-beginning
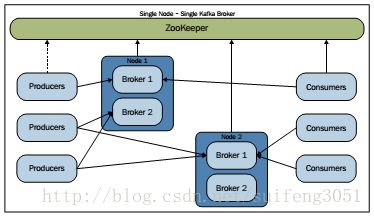
三、集群模式(多节点多实例)
介绍了上面两种配置方法,再理解集群配置就简单了,比如我们要配置如下图所示集群:
zookeeper配置文件(zookeeper.properties):不变
broker的配置配置文件(server.properties):按照单节点多实例配置方法在一个节点上启动两个实例,不同的地方是zookeeper的连接串需要把所有节点的zookeeper都连接起来
# Zookeeper 连接串
zookeeper.connect=node1:2181,node2:2181