java内存中的对象
痴情研究java内存中的对象
博客分类: java底层 痴情研究java内存中的对象
前记:
几天前,在浏览网页时偶然的发现一道以前就看过很多遍的面试题,题目是:“请说出‘equals’和‘==’的区别”,当时我觉得我还是挺懂的,在心里答 了一点(比如我们都知道的:‘==’比较两个引用是否指向同一个对象,‘equals’比较两个对象的内容),可是总觉得心里有点虚虚的,因为这句话好像 太概括了,我也无法更深入地说出一些。于是看了几篇别人的技术博客,看完后我心里自信地说,我是真的懂了;后来根据我当时的理解,就在eclipse中敲 了些代码验证一下,发现有些运行的结果和我预期的又不一样,怎么找原因都找不到,呵呵~,这时就感觉太伤自尊了,于是我觉得我真的还是不懂得,又去上网查 找答案,呵呵,这个问题花了我整整三天的时间,现在想把我的一些总结写下来,以达到检测自己的目的,也欢迎大家浏览、批评、指正。
注:本文不仅研究类类型的对象,还研究基本数据类型
线索:
我想采用实例代码驱动的方式来一步步地分析,这也符合我们探知新事物的过程。
一、基本数据类型的内存分配
代码1:
- int p1= 1000 ;
- static int p2= 1000 ;
- public void myTest(){
- System.err.println("****************Integer*********************" );
- int i1= 1000 ;
- int i2= 1000 ;
- Integer i3=1000 ;
- Integer i4=1000 ;
- Integer i5=100 ;
- Integer i6=100 ;
- Integer i7=new Integer( 1000 );
- Integer i8=new Integer( 1000 );
- System.err.println(i1==p1); //true(输出结果) 1(编号,便于分析)
- System.err.println(i1==p2); //true 2
- System.err.println(i1==i2); //true 3
- System.err.println(i3==i4); //false 4
- System.err.println(i5==i6); //true 5
- System.err.println(i7==i8); //false 6
- System.err.println(i1==i3); //true 7
- System.err.println(i1==i7); //true 8
- System.err.println(i3==i7); //false 9
- System.err.println("****************Integer*********************" );
- }
看到上面的输出结果,如果你还是有些不能理解的,那就耐心地接着看我的分析吧。
分析:
编号1:在java编译时期,当编译到“int p1=1000; ”时会创建常量1000,放入常量池,其实后面的p2,i1,i2都是指向这个1000,这样可以提高java的性能,所以编号1、编号2、编号3的输出 结果都是true.其实char,float,double等基本数据类型都是这样的。
编号2、编号3:同编号1
编号4:这是java中的自动装箱机制,将基本数据类型int自动转为 类类型Integer,这是jdk1.5以上才有的功能,jdk1.5以下编译时会报错。自动装箱时java底层会调用 Integer.valueOf(int i)方法自动装箱,下面我们来看看Integer.valueOf(int i)的源码吧:
- /**
- * @param i an
intvalue. - * @return a Integer instance representing i.
- * @since 1.5
- */
- public static Integer valueOf( int i) {
- if (i >= - 128 && i <= IntegerCache.high)
- return IntegerCache.cache[i + 128 ];
- else
- return new Integer(i);
- }
注:分析源码我们知道IntegerCache.high其实就是127,在IntergerCache的静态块中定义的。
源码的意思是当i的值在-128—127之间时会返回 IntegerCache.cache[]中的对象,其他的新建一个Integer对象。其实Integer类是这样实现的:考虑到-128—127之间 的对象经常使用,就在Integer创建时将值在-128—127之间的对象先创建好,放在池中,以后要使用时,这些对象就不用重新创建了,目的在于提高 性能。其实这种机制在Character中也用到了,Character是创建ASCII在0—127之间的对象。补充说明:Integer创建的对象引 用在栈中,对象的内容在堆区,栈中的值是堆中对象的地址。Character、Long、Short等包装类都是这样的。所以编号4的输出结果是 false,因为值大于127,java新创建了一个对象。
编号5:因为值在-128—127之间,所以两个引用指向的是堆区的同一个对象。
编号6:当使用new创建对象时,都会新创建一个对象,即在栈中创建一个引用,在堆中创建该对象,引用指向对象。
编号7:这种情况有些人可能会不太清楚,其实这是java的自动拆箱机制,当 int和Integer发生操作时,Integer类型对象会自动拆箱成int值,这时比较的是两个int值,而我们前面分析了,int值都会指向常量池 中的数据,所以,两者指向的是同一块空间。结果编号7输出true
编号8:同编号7,也是Integer的自动拆箱。
编号9:我想,分析了这么多,编号9不用我说,你也应该懂了,呵呵,这里就不赘述了哦~
分析了这么多,终于第一块代码分析完了。
二、String类型的内存分配
大家都知道String类型是类类型,不过String类型是一个特殊的类类型,那它特殊在哪呢?
代码2:
- System.err.println( "****************string*********************" );
- String s1="abc" ;
- String s2="abc" ;
- String s3=new String( "abc" );
- String s4=new String( "abc" );
- System.err.println(s1==s2);//true (输出结果) 1(编号)
- System.err.println(s3==s4);//false 2
- System.err.println(s1==s3);//false 3
- String a = "abc" ;
- String b = "ab" ;
- String c = b + "c" ;
- System.err.println(a==c);//false 4
- String s5 = "123" ;
- final String s6= "12" ;
- String s7=s6+"3" ;
- System.err.println(s5 == s7);//true 5
- System.err.println("****************string*********************" );
编号1:String类型是一个很特殊的类型,当我们使用String str=”abc”;这种定义方法时,”abc”会放入常量池中,以后如果再有定义String str2=”abc”时,其实str和str2指向的是常量池中同一个对象。而只有当使用new创建时才会每次都创建一个新的对象。(我觉得这是 String类型和其他类类型的特殊之处)
编号2、编号3:编号1已经分析了。
编号4:执行到 String c = b + "c"; 这一句时,java底层会先创建一个StringBuilder对象,封装b,接着再加上“c”,最后再创建一个String对象,将 StringBuilder中的值赋给该String对象,用c来指向它。.其实此时的c指向的对象已经不是a指向的对象了。
编号5:当用final修饰后,s6就变为了常量,在常量池中创建“12”,当执行到String s7=s6+"3";时,编译器直接就把s6当成了“12”,s7此时就已是“123”,它指向常量池中的“123”,所以s5和s7指向的是同一个对象,输出为true。
三、StringBuilder,StringBuffer,String的对比
(一)String
String类型的值是不可变的,听到这句话后可能你会有疑问,我们的String对象可以重新赋值呀,这里有两种情况,情况一:String str=”abc”; , 情况二:String str=new String(“abc”);采用情况一重新赋值时,java会先看常量池中有没有“abc”,如果有则直接指向它,如果没有,在编译时就创建一个常量放 入常量池中;对于情况二:str则重新指向一个先创建的对象,该新对象在堆中。下面提出问题:为什么String是不可变的呢?我们来看看String的 源码:
- public final class String
- implements java.io.Serializable, Comparable
, CharSequence - {
- /** The value is used for character storage. */
- private final char value[];
- /** The offset is the first index of the storage that is used. */
- private final int offset;
- /** The count is the number of characters in the String. */
- private final int count;
- //••••••••••••••••••••
我们看到String类型是用一个用final修饰的char数组来存储字符串 的,所以String类型是不可变的,(其实Short,Character,Long等包装类型也是这样实现的),根据上面对String类型的分析, 如果要改变String的值,就要重新创建一个对象,这无疑性能会很差。为了优化String,sun公司添加了StringBuffer,在 jdk1.5之后又添加了StringBuilder。
(二)下面我们来分析一下StringBuffer
StringBuffer作为字符串缓冲类,当进行字符串拼接时,不会重新创建一个StringBuffer对象,而是直接在原有值后面添加,因为 StringBuffer类继承了AbstractStringBuffer类,分析后者的源码后,我们发现存储字符串的char[]没有被final修 饰。至于StringBuffer类是怎样扩充自己的长度的,我们可以参考它的append()方法,这里不再赘述。不过一定要提出的 是:StringBuffer是线程安全的,它的方法体是被synchronized修饰了的。
(三)StringBuilder有是怎么样的呢?
StringBuilder基本实现了StringBuffer的功能,最大的不同之处在于StringBuilder不是线程安全的。
(四)String、StringBuffer、StringBuilder的性能比较
代码三:
- StringBuffer b = new StringBuffer( "abc" );
- long t3 = System.currentTimeMillis();
- for ( int i = 0 ; i < 1000000 ; i++) {
- b = b.append("def" );
- }
- long t4 = System.currentTimeMillis();
- System.out.println("1000000次拼接,StringBuffer所花时间为:" + (t4 - t3));
- System.out.println("*************************************" );
- StringBuilder c = new StringBuilder( "abc" );
- long t5 = System.currentTimeMillis();
- for ( int i = 0 ; i < 1000000 ; i++) {
- c = c.append("def" );
- }
- long t6 = System.currentTimeMillis();
- System.out.println("1000000次拼接,StringBuilder所花时间为:" + (t6 - t5));
- System.out.println("*************************************" );
- String S1 = "abc" ;
- long t1 = System.currentTimeMillis();
- for ( int i = 0 ; i < 10000 ; i++) {
- S1 += "def" ;
- }
- long t2 = System.currentTimeMillis();
- System.out.println("10000次拼接,String所花时间为:" + (t2 - t1));
实验结果为:
- 1000000 次拼接,StringBuffer所花时间为: 203
- *************************************
- 1000000 次拼接,StringBuilder所花时间为: 79
- *************************************
- 10000 次拼接,String所花时间为: 640
显然,StringBuilder的性能最好,String的性能最差,而且差 很多;不过StringBuffer的线程安全性很好,性能也比较接近StringBuilder,所以我推荐的选择使用顺序 为:StringBuffer>StringBuilder>String;
四、java传参
下面我们我看一段代码,不过有点长,请大家有点耐心哦~
代码四:
- public class VariableTest {
- public static void main(String[] args) {
- VariableTest t = new VariableTest();
- t.test();
- }
- class Point {
- int x;
- String y;
- StringBuffer sb;
- public Point( int x, String y, StringBuffer sb) {
- this .x = x;
- this .y = y;
- this .sb = sb;
- }
- }
- public void test() {
- int i = 1 ;
- String str = "abc" ;
- StringBuffer bs = new StringBuffer( "abc" );
- Point p = new Point( 1 , "2" , new StringBuffer( "abc" ));
- System.out.println("***********函数调用之前****************" );
- System.out.println("i为:" + i);
- System.out.println("str为:" + str);
- System.out.println("bs为:" + bs);
- System.out.println("p的x为:" + p.x + " p的y为:" + p.y
- + " p的sb为:" + p.sb);
- change(i, str, bs, p);
- System.out.println("***********函数调用之后****************" );
- System.out.println("i为:" + i);
- System.out.println("str为:" + str);
- System.out.println("bs为:" + bs);
- System.out.println("p的x为:" + p.x + " p的y为:" + p.y
- + " p的sb为:" + p.sb);
- }
- public void change( int p1, String p2, StringBuffer p3, Point p4) {
- p1 = 2 ;
- p2 = "I have changed!" ;
- p3 = p3.append(" I have changed!" );
- p4.x = 5 ;
- p4.y = "I have changed!" ;
- p4.sb = p4.sb.append(" I have changed!" );
- }
- }
输出结果为:
- ***********函数调用之前****************
- i为:1
- str为:abc
- bs为:abc
- p的x为:1 p的y为: 2 p的sb为:abc
- ***********函数调用之后****************
- i为:1
- str为:abc
- bs为:abc I have changed!
- p的x为:5 p的y为:I have changed! p的sb为:abc I have changed!
分析:
这个例子我举得有点大,不过我觉得如果把我举得这个例子的参数传递完全搞懂了,你对java的参数传递过程就比较了解了。
不过在分析之前,我想给大家java传参的一个思想:java只有值传递,没有 引用传递,也没有指针传递。对于基本数据类型,java是直接传值,其实就是将形参指向常量池中的那个值;对于类类型(比如 String,StringBuffer,自定义类类型等)是传引用(在栈中)的值,也就是堆中对应对象的地址。这个在我认为也是值传递。
下面我们开始分析test()方法
1、首先定义了int类型变量,int类型变量传入change()方法是简单的值传递,这个大家都知道,所以就不说了;
2、下面是String类型的变量,大家可能会想,String类型是类类型啊,当调用change方法后test方法中也应该会发生变化呀,呵呵,其实 这时你忘了String类型是不可变的,因为它存储数据的char[]是用final修饰过的。当change方法中改变了p2的值后,其实p2指向的已 经是另一块内存空间了。
3、下面是StringBuffer类型,之前已说类类型传递变量的地址,所以bs和p3指向的是同一块内存空间,当p3重新赋值时,bs也会跟着变得。
4、下面是自定义的类类型,我不想再用文字述说了,就用一个图来表示吧,我相信你现在可以自己分析了。
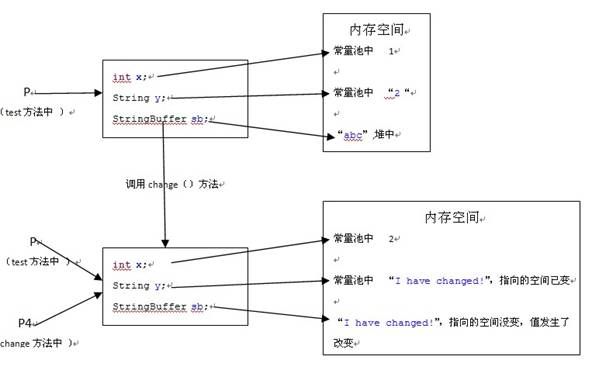
五、java对象的克隆机制(以上概念的应用)
概念引入:
我相信大家都听过java中的“克隆”这个名词,在Object类中有一个本地化clone()方法就是用来克隆对象的,其实我们自己也可以用new来克隆对象,但这样的效率会比较低。
概念名词:
浅度克隆:要克隆对象的属性如果是类类型变量,只在栈中创建一个该属性的新引用,指向源属性对象;如果是基本数据类型,还是常量池的运用,我相信你懂得。
深度克隆:对于类类型的属性,在栈中和堆中都重新开辟空间,创建一个全新的属性对象。基本数据类型和浅度克隆一样。
其实Object中的clone()方法就是一种浅度克隆,不过当我们重写该方法时一定要实现Cloneable接口,否则会报异常,代码验证如下:
代码五:
- public class CloneTest {
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- Point p1 = new CloneTest(). new Point( 1 , "abc" , new StringBuffer( "def" )); //源对象
- Point p2=p1.clone(); //克隆对象
- System.out.println("*************源对象的值如下****************" );
- System.out.println(p1.x);
- System.out.println(p1.y);
- System.out.println(p1.sb);
- System.out.println("************修改克隆对象的值*****************" );
- p2.x=2 ;
- p2.y="ddddddd" ;
- p2.sb=p2.sb.append("dfsfdsfsd" );
- System.out.println("************修改克隆对象的值后 ,源对象的值如下*****************" );
- System.out.println(p1.x);
- System.out.println(p1.y);
- System.out.println(p1.sb);
- }
- /**
- * 内部类,用于克隆实验
- */
- class Point implements Cloneable{
- int x;
- String y;
- StringBuffer sb;
- //构造方法
- public Point( int x, String y, StringBuffer sb) {
- this .x = x;
- this .y = y;
- this .sb = sb;
- }
- /**
- * 重写Object类的clone方法,不过默认情况下只能浅克隆,不过我们可以给类类型的变量
- * 重新new一块空间实现深度克隆,String类型就不用了哦~ ,呵呵,如果你现在还不知道
- * 为什么,那就把博客再看一遍吧,我充分相信你会懂得,这里我不想再赘述了,总之要知道,String
- * 类型和其他的类类型总是有一些区别,看到现在我希望你可以总结出一些
- */
- public Point clone(){
- Point o=null ;
- try {
- o = (Point)super .clone();
- //o.sb=new StringBuffer(); //实现深度克隆
- } catch (CloneNotSupportedException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- } return o;
- }
- }
- }
这时的运行结果如下,很显然是浅克隆。
- *************源对象的值如下****************
- 1
- abc
- def
- ************修改克隆对象的值*****************
- ************修改克隆对象的值后 ,源对象的值如下*****************
- 1
- abc
- defdfsfdsfsd
当我们把clone()方法中的注释语句“//o.sb=new StringBuffer(); ”启用后,这就是深度克隆了哦,运行结果如下:
- *************源对象的值如下****************
- 1
- abc
- def
- ************修改克隆对象的值*****************
- ************修改克隆对象的值后 ,源对象的值如下*****************
- 1
- abc
- def
上面实现深度克隆的方法是基于Object的clone()方法的,其实我们也 可以采用序列化的方式来实现深度克隆的,这样就不用重写clone()方法了,我们给Point类添加一个deepClone方法,不过一定要让 Point类实现Serializeble接口哦~,deepClone方法如下:
- /**
- * 采用序列化的方式实现深度克隆
- */
- public Point deepClone() throws IOException, ClassNotFoundException {
- //将对象写入流中
- ByteArrayOutputStream bs= new ByteArrayOutputStream();
- ObjectOutputStream os = new ObjectOutputStream(bs);
- os.writeObject(this );
- //从流中读取对象
- ByteArrayInputStream is= new ByteArrayInputStream(bs.toByteArray());
- ObjectInputStream ois=new ObjectInputStream(is);
- return (Point) ois.readObject();
- }
呵呵,通过这些实验,我想你对java的克隆机制还是比较了解了,具体的分析我也没有必要再说了。就到此为止吧•••
顶
踩
- 23:33
- 评论 / 浏览 (12 / 631)
- 分类:编程语言
- 相关推荐
评论
void change(Point p) {
p = new Point();
}
void test() {
Point p = null;
change(p);
sysout(p);//p is null
}
具体来说 就这形参中的P和test方法里的p不是同一个 当chang方法退出的时候。栈帧退出,所以chanag方法的一切都消失 ,但是,test方法里的p还是存在的,由此,更是证明,java是按值传递
void change(Point p) {
p = new Point();
}
void test() {
Point p = null;
change(p);
sysout(p);//p is null
}
分析得这么仔细,还真是痴情额