Lucence学习-初步使用
Lucence
1 概念
1.1 什么是全文检索
全文检索(Full-Text Retrieval)是指以文本作为检索对象,找出含有指定词汇的文本。全面、准确和快速是衡量全文检索系统的关键指标。
关于全文检索,往往只处理文本,不处理语义。结果列表有相关度排序。并且可以对结果具有过滤高亮等功能
1.2 全文检索与数据查询的区别
1)查询的方式与速度: 全文检索的速度大大快于SQL
2)相关度排序
3)定位不一样
4)其它
1.3 lucene介绍
我们使用Lucene,主要是做站内搜索,即对一个系统内的资源进行搜索。如BBS、BLOG中的文章搜索,网上商店中的商品搜索等。
Lucene是一个软件库,一个开发工具包,而不是一个具有完整特征的搜索应用程序。
它采用的是一种称为反向索引(invertedindex)的机制。反向索引简单理解就是维护一个词/短语表,对于这个表中的每个词/短语,都有一个相关信息描述了有哪些文档包含了这个词/短语。这样在用户输入查询条件的时候,就能非常快的得到搜索结果,它本身只关注文本的索引和搜索。Lucene使你可以为你的应用程序添加索引和搜索能力。通过lucene学习,我们就可以为自已的项目增加全文检索的功能。
2 Lucene环境与开发案例
2.1 新建java项目并导入包

2.2 新建实体类
publicclass Goods implements Serializable {
privatestaticfinallongserialVersionUID = 5251314995707817799L; private Integer goodsId; private String goodsName; private Double goodsPrice; private String goodsRemark;
public Goods() { super(); } public Goods(Integer goodsId, String goodsName,Double goodsPrice, StringgoodsRemark) { super(); this.goodsId = goodsId;//商品ID this.goodsName = goodsName;//商品名称 this.goodsPrice = goodsPrice;//商品价格 this.goodsRemark = goodsRemark;//商品备注、描述 } @Override public String toString() { return"Goods [goodsId=" + goodsId + ",goodsName=" + goodsName +",goodsPrice=" + goodsPrice + ", goodsRemark=" + goodsRemark +"]"; } public Integer getGoodsId() { returngoodsId; } publicvoid setGoodsId(Integer goodsId) { this.goodsId = goodsId; } public String getGoodsName() { returngoodsName; } publicvoid setGoodsName(String goodsName) { this.goodsName = goodsName; } public Double getGoodsPrice() { returngoodsPrice; } publicvoid setGoodsPrice(Double goodsPrice) { this.goodsPrice = goodsPrice; } public String getGoodsRemark() { returngoodsRemark; } publicvoid setGoodsRemark(String goodsRemark) { this.goodsRemark = goodsRemark; } } |
2.3 新建索引库操作类
2.3.1 新增操作说明
关键步骤与代码解说:
1.构建索引库
Directory directory= FSDirectory.open(new File("索引库目录"));
2.指定分词器,版本一般指定为最高
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
3.创建文档对象,并添加相关字段值
Document doc = new Document();
doc.add(new Field("goodsId",goods.getGoodsId().toString(),Store.YES,Index.NOT_ANALYZED));
4.创建增删改索引库的操作对象,添加文档并提交
IndexWriter indexWriter= new IndexWriter(directory, analyzer,MaxFieldLength.LIMITED);
indexWriter.addDocument(doc);
indexWriter.commit();
5.关闭操作对象
示例
public class FirstLuceneDaoImpl {
/** * 保存指定的商品信息 * @param goods 商品信息 */ public void saveGoods(Goods goods){ /* *系统可以先处理文件上传(如商品有图片),数据入库等操作,然后再进行索引库相关信息的处理 */
//指定索引库目录 Directory directory=null; IndexWriter indexWriter=null; try { directory = FSDirectory.open(new File("e:/testdir/lucenedir")); //指定分词器 Analyzer analyzer= new StandardAnalyzer(Version.LUCENE_30); /* *创建索引库管理对象(主要用来增删改索引库信息) * MaxFieldLength,用于限制Field的大小。这个变量可以让用户有计划地对大文档Field进行截取。假如取值为10000,就只索引每个Field的前10000个Term(关键字)。其它的部分都不会被Lucene索引,也不能被搜索到。 */ indexWriter = new IndexWriter(directory,analyzer,MaxFieldLength.LIMITED); //创建lucene文档对象,并添加字段 Document doc = new Document(); /* * Store.YES表示把当前字段存到文档中,Store.NO表示不把当前字段存到文档中 * Index: * ANALYZED,表示当前字段建立索引,并且进行分词,产生多个term * NOT_ANALYZED,表示当前字段建立索引,但不进行分词,整个字段值作为一个整体,产生一个term * NO,不创建索引,以后不能用此字段查询 */ if (goods.getGoodsId() != null) { doc.add(new Field("goodsId", goods.getGoodsId().toString(),Store.YES, Index.NO)); } if (goods.getGoodsName() != null) { doc.add(new Field("goodsName", goods.getGoodsName(), Store.YES, Index.ANALYZED)); } if (goods.getGoodsPrice() != null) { doc.add(new Field("goodsPrice", goods.getGoodsPrice() .toString(),Store.NO, Index.ANALYZED)); } if (goods.getGoodsRemark() != null) { doc.add(new Field("goodsRemark", goods.getGoodsRemark(), Store.YES, Index.NOT_ANALYZED)); } //添加文档对象 indexWriter.addDocument(doc); //提交到索引库 indexWriter.commit(); } catch (IOException e) { throw new RuntimeException(e); }finally{ if(indexWriter!=null){ try { indexWriter.close(); }catch (Exception e) { e.printStackTrace(); } } } } } |
2.3.2 查询操作说明
关键步骤与代码解说:
1.打开索引库
directory = FSDirectory.open(new File("索引库目录"));
2.创建查询分词器,版本号与写入文档的查询分词器一样
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
3.创建查询解析器,参数为版本号,查询字段名,分词器
QueryParser parser = new QueryParser(Version.LUCENE_30, "goodsName", analyzer);
4.构建查询信息对象
Query query = parser.parse(keyWord);
5.构建查询工具
searcher= new IndexSearcher(directory);
6.通过查询工具执行查询。参数1,查询信息对象;参数2。返回记录数;TopDocs包括总记录数、文档重要信息(编号)的列表等
TopDocstopDocx=searcher.search(query, 20);
7.根据文档编号遍历真正的文档
ScoreDocsd[] = topDocx.scoreDocs;
for(ScoreDoc scoreDoc:sd){
Document doc = searcher.doc(scoreDoc.doc);
8.转为java对象
goods.setGoodsId(Integer.parseInt(doc.get("goodsId")));
lists.add(goods);
9.关闭查询操作对象
/** * 通过关键字查找匹配商品 * @param name 查询关键字 * @return匹配商品列表 */ public List List Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30); Directory directory = null; IndexSearche rindexSearcher = null; try { directory=FSDirectory.open(new File("e:/testdir/lucenedir"));
indexSearcher=new IndexSearcher(directory); //查询解析器,参数一:版本号,一般选择最高,参数二:字段名,参数三:分词器 QueryParser parser=new QueryParser(Version.LUCENE_30,"goodsName",analyzer); //把查询关键字交给查询解析器,如果由多个单词组成,将匹配多个term 关键字,只要能匹配上任意一个单词都可以返回 Query query = parser.parse(name); //查询索引库,参数一:指定的查询解析器,参数二:指定返回记录条数 TopDocs topDosc = indexSearcher.search(query, 5);
System.out.println("实际在库中匹配的总记录数:"+topDosc.totalHits); ScoreDoc[] scoreDocs = topDosc.scoreDocs; System.out.println("返回的记录数(ID)数目:"+scoreDocs.length);
for(ScoreDoc scoreDoc:scoreDocs){ System.out.println("当前的文档积分为:"+scoreDoc.score+",当前的文档编号为:"+scoreDoc.doc); //根据文档编写查询真正的文档对象 Document document=indexSearcher.doc(scoreDoc.doc); System.out.println("真正的文档内容:"+document.get("goodsId")+"|"+document.get("goodsName")+"|"+document.get("goodsPrice")+"|"+document.get("goodsRemark"));
Goodsgoods=new Goods(); if (document.get("goodsId") != null) { goods.setGoodsId(Integer.parseInt(document.get("goodsId"))); } if (document.get("goodsName") != null) { goods.setGoodsName(document.get("goodsName")); } if (document.get("goodsPrice") != null) { goods.setGoodsPrice(Double.parseDouble(document .get("goodsPrice"))); } if (document.get("goodsRemark") != null) { goods.setGoodsRemark(document.get("goodsRemark")); } goodses.add(goods); } } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } finally{ if(indexSearcher!=null){ try { indexSearcher.close(); }catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
return goodses; } |
2.4编写测试类
|
@Test public void testSaveGoods() { Goods goods = new Goods(2,"goods one",11.1,"goods one is good"); firstLuceneDaoImpl.saveGoods(goods); System.out.println("-------保存成功!-------"); }
@Test public void testselectGoodsList(){ List for(Goods goods : goodses){ System.out.println("-------test goods 信息-------"+goods); } } |
2.5 查询过程分析
2.5.1 代码处理流程
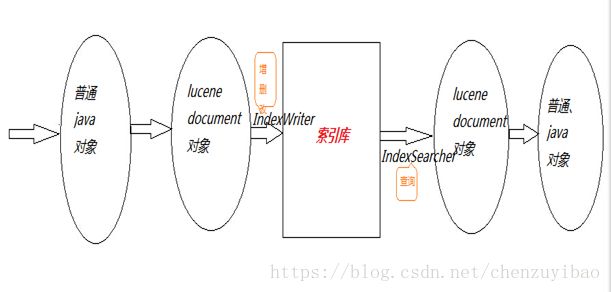
2.5.2 数据处理分析

2.6 使用总结
1、尽量减少不必要的字段存储.
2、不需要检索的内容不要建立索引.
3、非文本格式需要提前转化,字符串.
4、需要整体存放的内容不要分词,例如:ID、价格、专业词.