很多人在决定是否看一部电影之前都会去豆瓣看下评分作为参考,看完电影也会给一个自己的分数。每个人对每个商品或者电影或是音乐都有一个心理的分数,这个分数标明用户是否对这个内容满意。作为内容的提供方,如果可以预测出每个用户对于内容的心理分数,就能更好的理解用户,并给用户提供好的内容推荐。今天就介绍下如何通过ALS矩阵分解算法实现用户对于音乐或者电影的评分预测。
ALS算法介绍
ALS算法是基于模型的推荐算法,基本思想是对稀疏矩阵进行模型分解,评估出缺失项的值,以此来得到一个基本的训练模型。然后依照此模型可以针对新的用户和物品数据进行评估。ALS是采用交替的最小二乘法来算出缺失项的,交替的最小二乘法是在最小二乘法的基础上发展而来的。
从协同过滤的分类来说,ALS算法属于User-Item CF,也叫做混合CF,它同时考虑了User和Item两个方面。
我们通过音乐打分这个案例介绍下交替最小二乘法的原理,首先拿到的原始数据是每个听众对每首歌的评分矩阵A,这个评分可能是非常稀疏的,因为不是每个用户都听过所有的歌,也不是每个用户都会对每首歌评分。
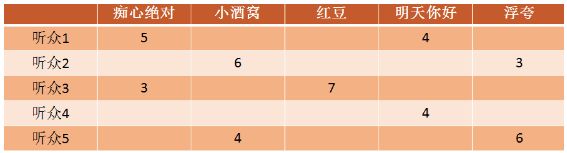
ALS矩阵分解会把矩阵A分解成两个矩阵的相乘,分别是X矩阵和Y矩阵,
矩阵A=矩阵X和矩阵Y的转秩的乘积x的列表示和Y的横表示可以称之为ALS中的因子,这个因子是有隐含定义的,这里假设有3个因子,分别是性格、教育程度、爱好。A矩阵经过ALS分解出的X、Y矩阵可以分别表示成:
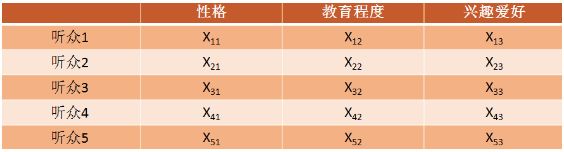
(上图为x矩阵)
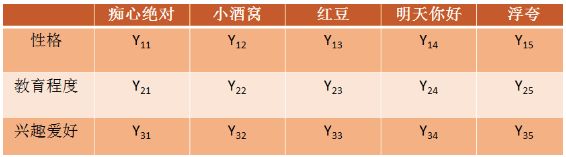
(上图为Y矩阵)
数据经过这样的拆解就很容易做用户对音乐的评分预测。比如有听众6,他从没听过“红豆“这首歌,但是我们可以拿到听众6在矩阵分解中X矩阵的向量M,这时候只有把向量M和”红豆“在Y矩阵中的对应向量N相乘,就能预测出听众6对于”红豆“这首歌的评分。
ALS在PAI实验
现在在PAI上面对ALS算法案例进行实验。整体流程只需要包含输入数据源和ALS矩阵分解组件即可。本案例已经集成于PAI-STUDIO首页模板:
创建后如图:
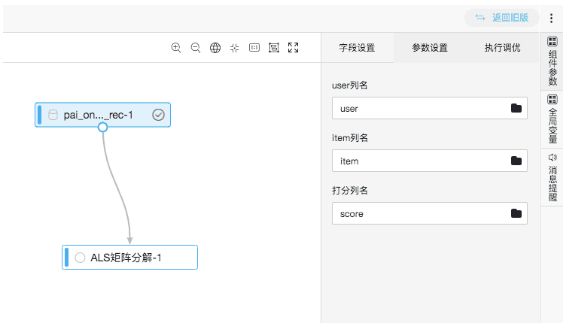
1.数据源
输入数据源包含4个字段
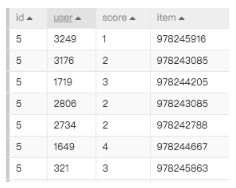
- User:用户ID
- Item:音乐ID
- score:user对item的评分
2.ALS矩阵分解
需要设置3个对应字段,
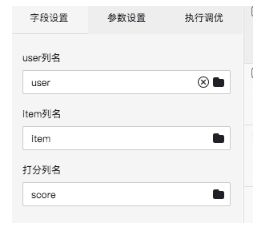
| 参数名称 | 参数描述 | 取值范围 | 是否必选,默认值 |
|---|---|---|---|
| userColName | user列名 | 列的类型必须是bigint,可以不连续编号 | 必选 |
| itemColName | item列名 | 列的类型必须是bigint,可以不连续编号 | 必选 |
| rateColName | 打分列名 | 列的类型必须是数值类型 | 必选 |
| numFactors | 因子数 | 正整数 | 可选,默认值100 |
| numIter | 迭代数 | 正整数 | 可选,默认值10 |
| lambda | 正则化系数 | 浮点数 | 可选,默认值0.1 |
| implicitPref | 是否采用隐式偏好模型 | 布尔型 | 可选,默认值false |
| alpha | 隐式偏好系数 | 浮点数,大于0 | 可选,默认值40 |
3.结果分析
本案例中会输出2张表,对应ALS算法介绍中说的X矩阵和Y矩阵。
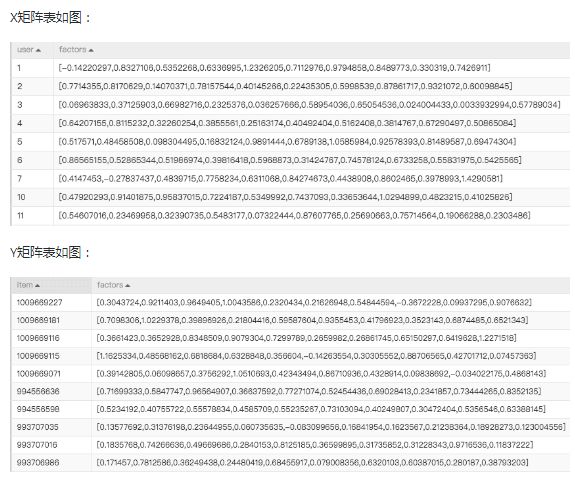
比如要预测user1对音乐item994556636的评分,只要将下方两个向量相乘即可
- User1:[-0.14220297,0.8327106,0.5352268,0.6336995,1.2326205,0.7112976,0.9794858,0.8489773,0.330319,0.7426911]
- item994556636:[0.71699333,0.5847747,0.96564907,0.36637592,0.77271074,0.52454436,0.69028413,0.2341857,0.73444265,0.8352135]
原文链接
本文为云栖社区原创内容,未经允许不得转载。