NLP——基于seq2seq的简易中英文翻译系统
基于seq2seq的简易中英文翻译系统
1. 项目背景
项目地址:https://github.com/audier/my_deep_project/tree/master/NLP
1.1 seq2seq与lstm关系
之前我们利用lstm进行建模,设计了一个自动生成莫言小说的模型,这次想要利用rnn的特点搭建一个中英文的翻译系统。传统的RNN输入和输出长度要一致,而seq2seq在RNN的基础上进行改进,实现了变长序列的输入和输出,广泛的应用在了机器翻译、对话系统、文本摘要等领域。
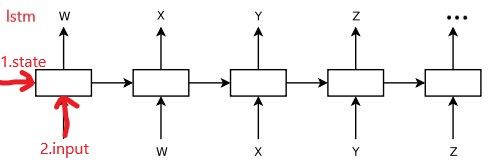
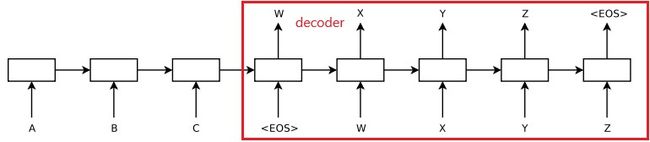
实际上,seq2seq模型和之前的lstm生成小说的模型非常相似,seq2seq多了个encoder端,decoder端只是训练的方法不同,生成输出所需初始化的参数不同。如下图所示:
- lstm的中文小说生成模型:
- 基于seq2seq的中英文翻译模型:
1.2 seq2seq与lstm的区别
我们可以看出lstm结构上和seq2seq的decoder端结构是一样的。实际上,他们确实是一模一样的,而他们唯一的区别在于两个结构的输入不同。

- lstm结构:1.state为固定值初始化,2.input为网络的输入
- seq2seq:2.state为encoder端编码得到的值,2.input为给定的起始输入
1.3 一些想法
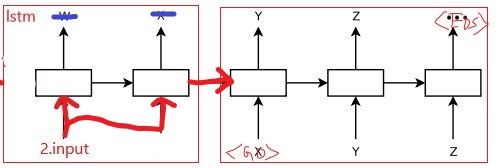
其实从另一种角度看,seq2seq和lstm可以看做完全一样的网络结构,我们既可以把seq2seq看成lstm的演化版本,也可以把lstm看成seq2seq的一部分。
如果把lstm从中间截断,并修改下一个的输入就能得到seq2seq:
参考文献:
- 论文地址:https://arxiv.org/pdf/1409.3215.pdf
- 代码参考:https://github.com/keras-team/keras/blob/master/examples/lstm_seq2seq.py
2. 项目数据
项目数据使用中英文翻译数据集,来实现字符级的seq2seq模型的训练。
该文件来自于:http://www.manythings.org/anki/
内容如下:
# ========读取原始数据========
with open('cmn.txt', 'r', encoding='utf-8') as f:
data = f.read()
data = data.split('\n')
data = data[:100]
print(data[-5:])
['Tom died.\t汤姆去世了。', 'Tom quit.\t汤姆不干了。', 'Tom swam.\t汤姆游泳了。', 'Trust me.\t相信我。', 'Try hard.\t努力。']
3. 数据处理
3.1 生成字典
我们需要将汉字和英文映射为能够输入到模型中的数字信息,就需要建立一个映射关系,需要生成汉字和数字互相映射的字典。
- 我们将英文按照每个字母对应一个index
- 我们将中文按照每一个汉字对应一个index
- 注意增加解码器的起始符合终止符:
3. 开始符号:\t
4. 结束符号:\n
# 分割英文数据和中文数据
en_data = [line.split('\t')[0] for line in data]
ch_data = ['\t' + line.split('\t')[1] + '\n' for line in data]
print('英文数据:\n', en_data[:10])
print('\n中文数据:\n', ch_data[:10])
# 分别生成中英文字典
en_vocab = set(''.join(en_data))
id2en = list(en_vocab)
en2id = {c:i for i,c in enumerate(id2en)}
# 分别生成中英文字典
ch_vocab = set(''.join(ch_data))
id2ch = list(ch_vocab)
ch2id = {c:i for i,c in enumerate(id2ch)}
print('\n英文字典:\n', en2id)
print('\n中文字典共计\n:', ch2id)
英文数据:
['Hi.', 'Hi.', 'Run.', 'Wait!', 'Hello!', 'I try.', 'I won!', 'Oh no!', 'Cheers!', 'He ran.']
中文数据:
['\t嗨。\n', '\t你好。\n', '\t你用跑的。\n', '\t等等!\n', '\t你好。\n', '\t让我来。\n', '\t我赢了。\n', '\t不会吧。\n', '\t乾杯!\n', '\t他跑了。\n']
英文字典:
{'f': 0, 'w': 1, 'l': 2, 'n': 3, "'": 4, 'o': 5, '.': 6, 'Y': 7, 'h': 8, 'B': 9, 'D': 10, 'q': 11, 'r': 12, ' ': 13, 'a': 14, 'J': 15, 'K': 16, 'O': 17, 'v': 18, 'i': 19, 'C': 20, 'T': 21, 'G': 22, '!': 23, 'k': 24, 'S': 25, 'L': 26, 'W': 27, '?': 28, 'p': 29, 'g': 30, 'I': 31, 'c': 32, 'y': 33, 'A': 34, 'R': 35, 'm': 36, 's': 37, 'u': 38, 'e': 39, 'N': 40, 'H': 41, 'b': 42, 'd': 43, 't': 44, 'P': 45}
中文字典:
{'人': 0, '前': 1, '閉': 2, '開': 3, '没': 4, '的': 5, '到': 6, '们': 7, '完': 8, '趕': 9, '你': 10, '來': 11, '住': 12, '确': 13, '定': 14, '让': 15, '相': 16, '杯': 17, '公': 18, '再': 19, '把': 20, '很': 21, '飽': 22, '用': 23, '么': 24, '出': 25, '忙': 26, '泳': 27, '?': 28, '气': 29, '会': 30, '善': 31, '同': 32, '沒': 33, '一': 34, '点': 35, '吧': 36, '往': 37, '努': 38, '嗨': 39, '别': 40, '失': 41, '跳': 42, '谁': 43, '放': 44, '和': 45, '加': 46, '他': 47, '滾': 48, '美': 49, '告': 50, '!': 51, '。': 52, '平': 53, '她': 54, '入': 55, '知': 56, '开': 57, '坚': 58, '迎': 59, '听': 60, '干': 61, '是': 62, '着': 63, '信': 64, '抓': 65, '起': 66, '留': 67, '吻': 68, '忘': 69, '上': 70, '进': 71, '找': 72, '它': 73, '\t': 74, '!': 75, '为': 76, '立': 77, '道': 78, '走': 79, '联': 80, '管': 81, ',': 82, '友': 83, '生': 84, '玩': 85, '老': 86, '抱': 87, '随': 88, '好': 89, '拿': 90, '們': 91, '能': 92, '持': 93, '呆': 94, '当': 95, '帮': 96, '姆': 97, '系': 98, '迷': 99, '下': 100, '我': 101, '不': 102, '静': 103, '去': 104, '\n': 105, '得': 106, '醒': 107, '游': 108, '后': 109, '弃': 110, '快': 111, '汤': 112, '嘴': 113, '儿': 114, '见': 115, '辞': 116, '趴': 117, '吃': 118, '付': 119, '动': 120, '世': 121, '冷': 122, '就': 123, '来': 124, '退': 125, '关': 126, '欢': 127, '门': 128, '錢': 129, '等': 130, '乾': 131, '事': 132, '可': 133, '了': 134, '跑': 135, '试': 136, '个': 137, '始': 138, '意': 139, '赢': 140, '病': 141, '铐': 142, '问': 143, '心': 144, '力': 145, '清': 146, '什': 147, '洗': 148}
3.2 转换输入数据格式
建立字典,将文本数据映射为数字数据形式。
# 利用字典,映射数据
en_num_data = [[en2id[en] for en in line ] for line in en_data]
ch_num_data = [[ch2id[ch] for ch in line] for line in ch_data]
de_num_data = [[ch2id[ch] for ch in line][1:] for line in ch_data]
print('char:', en_data[1])
print('index:', en_num_data[1])
char: Hi.
index: [41, 19, 6]
3.3 将训练数据进行onehot编码
将数据格式改为onehot的格式:
-
输入示例:
[1,2,3,4] -
输出示例:
[1,0,0,0]
[0,1,0,0]
[0,0,1,0]
[0,0,0,1]
import numpy as np
# 获取输入输出端的最大长度
max_encoder_seq_length = max([len(txt) for txt in en_num_data])
max_decoder_seq_length = max([len(txt) for txt in ch_num_data])
print('max encoder length:', max_encoder_seq_length)
print('max decoder length:', max_decoder_seq_length)
# 将数据进行onehot处理
encoder_input_data = np.zeros((len(en_num_data), max_encoder_seq_length, len(en2id)), dtype='float32')
decoder_input_data = np.zeros((len(ch_num_data), max_decoder_seq_length, len(ch2id)), dtype='float32')
decoder_target_data = np.zeros((len(ch_num_data), max_decoder_seq_length, len(ch2id)), dtype='float32')
for i in range(len(ch_num_data)):
for t, j in enumerate(en_num_data[i]):
encoder_input_data[i, t, j] = 1.
for t, j in enumerate(ch_num_data[i]):
decoder_input_data[i, t, j] = 1.
for t, j in enumerate(de_num_data[i]):
decoder_target_data[i, t, j] = 1.
print('index data:\n', en_num_data[1])
print('one hot data:\n', encoder_input_data[1])
max encoder length: 9
max decoder length: 11
index data:
[41, 19, 6]
one hot data:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
4. 模型选择与建模
参数设置
包括网络结构以及训练相关的参数。
# =======预定义模型参数========
EN_VOCAB_SIZE = len(en2id)
CH_VOCAB_SIZE = len(ch2id)
HIDDEN_SIZE = 256
LEARNING_RATE = 0.003
BATCH_SIZE = 100
EPOCHS = 200
4.1 encoder建模
搭建encoder模型,我们利用keras的lstm层进行搭建,这里使用了两层的lstm作为编码器。需要注意参数:
- 第一层的输出需要传递到下一层的lstm,因此
return_sequences=True - 两层都需要输出最终得到的状态,
return_state=True
这里直接采用了onehot作为输出,我也尝试了加入词嵌入层,但是效果比onehot差很多,我也不知道是我用错了还是怎么回事。
# ======================================keras model==================================
from keras.models import Model
from keras.layers import Input, LSTM, Dense, Embedding
from keras.optimizers import Adam
import numpy as np
# ==============encoder=============
encoder_inputs = Input(shape=(None, EN_VOCAB_SIZE))
#emb_inp = Embedding(output_dim=HIDDEN_SIZE, input_dim=EN_VOCAB_SIZE)(encoder_inputs)
encoder_h1, encoder_state_h1, encoder_state_c1 = LSTM(HIDDEN_SIZE, return_sequences=True, return_state=True)(encoder_inputs)
encoder_h2, encoder_state_h2, encoder_state_c2 = LSTM(HIDDEN_SIZE, return_state=True)(encoder_h1)
4.2 decoder建模
decoder部分需要搭建两个,一个是训练所需的数据是一个序列化的数据,另一个是预测所需的数据包括当前状态以及当前的输入,然后输出的状态和输出作为下一步的输入。
下面的是训练所需的模型:
# ==============decoder=============
decoder_inputs = Input(shape=(None, CH_VOCAB_SIZE))
#emb_target = Embedding(output_dim=HIDDEN_SIZE, input_dim=CH_VOCAB_SIZE, mask_zero=True)(decoder_inputs)
lstm1 = LSTM(HIDDEN_SIZE, return_sequences=True, return_state=True)
lstm2 = LSTM(HIDDEN_SIZE, return_sequences=True, return_state=True)
decoder_dense = Dense(CH_VOCAB_SIZE, activation='softmax')
decoder_h1, _, _ = lstm1(decoder_inputs, initial_state=[encoder_state_h1, encoder_state_c1])
decoder_h2, _, _ = lstm2(decoder_h1, initial_state=[encoder_state_h2, encoder_state_c2])
decoder_outputs = decoder_dense(decoder_h2)
4.3 训练模型
搭建模型,利用准备好的数据进行训练:
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
opt = Adam(lr=LEARNING_RATE, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
validation_split=0.)
# Save model
#model.save('s2s.h5')
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, None, 46) 0
__________________________________________________________________________________________________
input_2 (InputLayer) (None, None, 149) 0
__________________________________________________________________________________________________
lstm_1 (LSTM) [(None, None, 256), 310272 input_1[0][0]
__________________________________________________________________________________________________
lstm_3 (LSTM) [(None, None, 256), 415744 input_2[0][0]
lstm_1[0][1]
lstm_1[0][2]
__________________________________________________________________________________________________
lstm_2 (LSTM) [(None, 256), (None, 525312 lstm_1[0][0]
__________________________________________________________________________________________________
lstm_4 (LSTM) [(None, None, 256), 525312 lstm_3[0][0]
lstm_2[0][1]
lstm_2[0][2]
__________________________________________________________________________________________________
dense_1 (Dense) (None, None, 149) 38293 lstm_4[0][0]
==================================================================================================
Total params: 1,814,933
Trainable params: 1,814,933
Non-trainable params: 0
__________________________________________________________________________________________________
Epoch 1/200
100/100 [==============================] - 2s 24ms/step - loss: 2.3245 - acc: 9.0909e-04
Epoch 2/200
100/100 [==============================] - 0s 2ms/step - loss: 2.3002 - acc: 0.0909
Epoch 3/200
100/100 [==============================] - 0s 3ms/step - loss: 2.2386 - acc: 0.0909
...
...
...
Epoch 198/200
100/100 [==============================] - 0s 2ms/step - loss: 0.0138 - acc: 0.4564
Epoch 199/200
100/100 [==============================] - 0s 2ms/step - loss: 0.0138 - acc: 0.4564
Epoch 200/200
100/100 [==============================] - 0s 2ms/step - loss: 0.0138 - acc: 0.4564
5. 评估准则与效果
这里我们直接观察生成的结果。
5.1 搭建预测模型
预测模型中的encoder和训练中的一样,都是输入序列,输出几个状态。而decoder和训练中稍有不同,因为训练过程中的decoder端的输入是可以确定的,因此状态只需要初始化一次,而预测过程中,需要多次初始化状态,因此将状态也作为模型输入。
# encoder模型和训练相同
encoder_model = Model(encoder_inputs, [encoder_state_h1, encoder_state_c1, encoder_state_h2, encoder_state_c2])
# 预测模型中的decoder的初始化状态需要传入新的状态
decoder_state_input_h1 = Input(shape=(HIDDEN_SIZE,))
decoder_state_input_c1 = Input(shape=(HIDDEN_SIZE,))
decoder_state_input_h2 = Input(shape=(HIDDEN_SIZE,))
decoder_state_input_c2 = Input(shape=(HIDDEN_SIZE,))
# 使用传入的值来初始化当前模型的输入状态
decoder_h1, state_h1, state_c1 = lstm1(decoder_inputs, initial_state=[decoder_state_input_h1, decoder_state_input_c1])
decoder_h2, state_h2, state_c2 = lstm2(decoder_h1, initial_state=[decoder_state_input_h2, decoder_state_input_c2])
decoder_outputs = decoder_dense(decoder_h2)
decoder_model = Model([decoder_inputs, decoder_state_input_h1, decoder_state_input_c1, decoder_state_input_h2, decoder_state_input_c2],
[decoder_outputs, state_h1, state_c1, state_h2, state_c2])
5.2 利用预测模型进行翻译
我们对第40—50个例子进行测试。
for k in range(40,50):
test_data = encoder_input_data[k:k+1]
h1, c1, h2, c2 = encoder_model.predict(test_data)
target_seq = np.zeros((1, 1, CH_VOCAB_SIZE))
target_seq[0, 0, ch2id['\t']] = 1
outputs = []
while True:
output_tokens, h1, c1, h2, c2 = decoder_model.predict([target_seq, h1, c1, h2, c2])
sampled_token_index = np.argmax(output_tokens[0, -1, :])
outputs.append(sampled_token_index)
target_seq = np.zeros((1, 1, CH_VOCAB_SIZE))
target_seq[0, 0, sampled_token_index] = 1
if sampled_token_index == ch2id['\n'] or len(outputs) > 20: break
print(en_data[k])
print(''.join([id2ch[i] for i in outputs]))
Hold on.
坚持。
Hug Tom.
抱抱汤姆!
I agree.
我同意。
I'm ill.
我生病了。
I'm old.
我老了。
It's OK.
没关系。
It's me.
是我。
Join us.
来加入我们吧。
Keep it.
留着吧。
Kiss me.
吻我。
可以看出结果还不错。
另一个评估方法是bleu,我研究研究在测试一下。
6. 模型优化
关于nlp方面的模型优化方法,我知道也很少。之前加入了embedding层,结果很差,也在思考有用的方法。我的这个模型和参考代码相比,多了一些层的lstm,也姑且算一种优化方法了吧。