编写MapReduce基础程序
专利数据
MapReduce基础程序的练习主要是对《专利引用》和《专利描述》两份数据进行分析。
下载地址: http://www.nber.org/patents/→下载acite75_99.zip和apat63_99.zip→在压缩包中提取cite75_99.txt(专利引用,如图1)和apat63_99.txt(专利描述,如图2)

图1专利引用部分截图
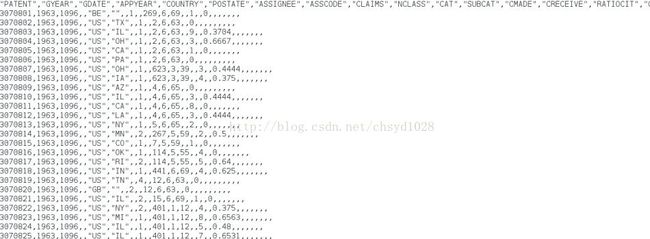
图2专利描述部分截图
专利引用数据涵盖了自1975年到1999年间对美国专利的引用。每行代表一份数据,第一个值代表专利编号,第二个值代表这个专利引用了哪个专利。另一个数据集:专利描述数据,其中包含了专利号、专利申请年份、专利批准年份、声明数目和其他与专利相关的元数据。
定义MapReduce作业→MyJob类(反向索引)
这个类的核心在run()方法中:
①实例化、配置并传递一个JobConf
②为每个作业定制基本参数(如Mapper,Reduce)
③或重置作业的默认属性(如InputFormat,OutputFormat)
④或调用JobConf的set()方法填充任意的配置参数
Mapper类和Reducer类都是MyJob类的内部类,Mapper的主要方法是map(),Reduce的主要方法是reduce()
例:
package org.apache.hadoop.pr;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.KeyValueTextInputFormat;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MyJob extends Configured implements Tool{
//Mapper类
publicstatic class MapClass extends MapReduceBase implementsMapper{
public voidmap(Text key, Text value, OutputCollector output, Reporterreporter) throws IOException {
output.collect(value, key);
}
}
//Reducer类
publicstatic class Reduce extends MapReduceBase implements Reducer{
public voidreduce(Text key, Iterator values, //K和V必须与Mapper类型相同
OutputCollector output,
Reporterreporter) throws IOException {
String csv ="";
//遍历出所有引用过这个专利的专利
while(values.hasNext()){
if(csv.length() > 0) csv += ",";
csv +=values.next().toString();
}
//输出
output.collect(key, new Text(csv));
}
}
public intrun(String[] args) throws Exception {
Configuration conf = getConf();
JobConf job= new JobConf(conf, MyJob.class);
//设置路径,在运行时需要传两个参数
Path in =new Path(args[0]);
Path out =new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName("MyJob");
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
job.setInputFormat(KeyValueTextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);//因为上面Mapper和Reducer中的K都是Text,这里必须保持一致
job.setOutputValueClass(Text.class);//因为上面Mapper和Reducer中的V都是Text,这里必须保持一致
job.set("key.value.separator.in.input.line", ",");
JobClient.runJob(job);
return0;
}
public static void main(String[] args) throwsException{
int res =ToolRunner.run(new Configuration(), new MyJob(), args);
System.exit(res);
}
}
用Eclipse执行过程
在前几篇中有一篇推荐了如何安装Eclipse,并用它运行hadoop的伪分布式。这里重新用这个程序将下运行过程(假设你已经安装好Eclipse并配置了伪分布式环境)
①首先打开终端,并到Hadoop安装目录下输入./sbin/start-dfs.sh启动为分布式,然后进到你保存cite75_99.txt和apat63_99.txt的目录下,输入语句hadoopfs -putcite75_99.txt,将这个文件复制到默认工作目录(hdfs中),可以同样的方法把apat63_99.txt也复制过去,以后的程序多是对这两个文件分析。
②打开Eclipse,在菜单栏中选File→New→Project新建项目。选择Map/ReduceProjiect(如图3),然后点Next,在Projectname中添加项目名称,我随意添加的ha,然后点Finish完成。
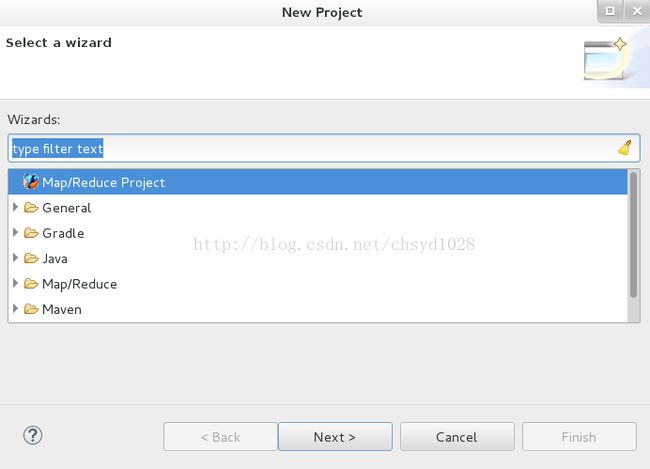
图3 新建Map/Reduce项目
③将你的core_site.xml,hdfs_site.xml和log4j.properties复制到项目的src目录下(找不到的看之前推荐的文章),再右键src→选择New→Class,在出现的窗体中,Package中写org.apache.hadoop.pr(这里是包名),在Name中写MyJob(这里是类名),完成后如图4。
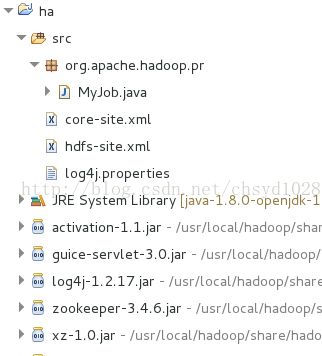
图4 项目内文件
④建好类后,将我上面的代码复制进去
⑤最后运行时,因为要填写参数,所以右键点击这个类→选择Run As→RunConfigurations...,在Arguments中填上两个参数(如图5),第一个参数为输入文件,即你要分析的文本。第二个参数为输出结果的文件夹位置,最后点Run运行。 ※输出文件夹不能存在,不然会报错。
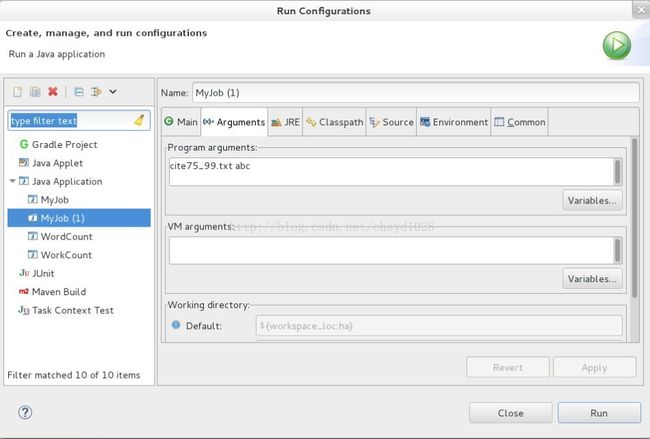
图5 添加参数
⑥如果想看到最后的结果并保存下来,可以用hadoop fs -get./abc/part-00000将这个文件复制到当前路径下,打开后的结果集就是这些专利被哪些专利引用过的集合(如图6)。

图6 反向索引结果
如果想要统计每个专利被引用的次数,只要稍微更改Reduce中的代码:
publicstatic class Reduce extends MapReduceBase implements Reducer{
public voidreduce(Text key, Iterator values, //K和V必须与Mapper类型相同
OutputCollector output,
Reporterreporter) throws IOException {
int count =0;
while(values.hasNext()){
values.next();
count++;
}
output.collect(key, new IntWritable(count));
}
}这样就成了一个新的MapReduce程序,因为是计算次数,所以最后的输出为IntWritable型,并更改里面的方法,在遍历时只要后面有值,就用count++来计数,而不用再考虑是被哪个专利引用了,结果如图7。

图7 专利被引用次数
※其他的MapReduce也是在这个框架上进行修改,成为新的MapReduce。