#pandas 基本介绍
# numpy 和 pandas 不同点:
# pandas 更像字典形式的numpy
import pandas as pd
import numpy as np
s = pd.Series([1,3,4,np.nan,44,1])
print s
dates = pd.date_range('20160101',periods = 6)
print dates
df = pd.DataFrame(np.random.randn(6,4),index = dates,columns=['a','b','c','d'])
print df
df1 = pd.DataFrame(np.arange(12).reshape((3,4)))
print df1
df2 = pd.DataFrame({'A':1,
'B':pd.Timestamp('20130102'),
'C':pd.Series(1,index =list(range(4)),dtype = 'float32'),
'D':np.array([3] * 4,dtype = 'int32'),
'E':pd.Categorical(['test','train','test','train']),
'F':'foo'})
print df2
print df2.dtypes
print df2.index
print df2.columns
print df2.values
print df2.describe()
print df2.T
print df2.sort_index(axis=1,ascending = False)
print df2.sort_index(axis=0,ascending = False)
print df2.sort_values(by='E',ascending = False)
0 1.0
1 3.0
2 4.0
3 NaN
4 44.0
5 1.0
dtype: float64
DatetimeIndex(['2016-01-01', '2016-01-02', '2016-01-03', '2016-01-04',
'2016-01-05', '2016-01-06'],
dtype='datetime64[ns]', freq='D')
a b c d
2016-01-01 0.263569 -0.687714 -0.723049 1.115857
2016-01-02 -1.239271 -0.090627 0.652509 -1.693457
2016-01-03 0.278214 -0.338247 0.873545 -0.259281
2016-01-04 0.351920 0.003695 -0.259181 -1.924558
2016-01-05 -0.343248 -0.168607 -0.811324 -1.111886
2016-01-06 -1.224475 0.166382 -0.972534 -0.160138
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
A B C D E F
0 1 2013-01-02 1.0 3 test foo
1 1 2013-01-02 1.0 3 train foo
2 1 2013-01-02 1.0 3 test foo
3 1 2013-01-02 1.0 3 train foo
A int64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
Int64Index([0, 1, 2, 3], dtype='int64')
Index([u'A', u'B', u'C', u'D', u'E', u'F'], dtype='object')
[[1 Timestamp('2013-01-02 00:00:00') 1.0 3 'test' 'foo']
[1 Timestamp('2013-01-02 00:00:00') 1.0 3 'train' 'foo']
[1 Timestamp('2013-01-02 00:00:00') 1.0 3 'test' 'foo']
[1 Timestamp('2013-01-02 00:00:00') 1.0 3 'train' 'foo']]
A C D
count 4.0 4.0 4.0
mean 1.0 1.0 3.0
std 0.0 0.0 0.0
min 1.0 1.0 3.0
25% 1.0 1.0 3.0
50% 1.0 1.0 3.0
75% 1.0 1.0 3.0
max 1.0 1.0 3.0
0 1 2 \
A 1 1 1
B 2013-01-02 00:00:00 2013-01-02 00:00:00 2013-01-02 00:00:00
C 1 1 1
D 3 3 3
E test train test
F foo foo foo
3
A 1
B 2013-01-02 00:00:00
C 1
D 3
E train
F foo
F E D C B A
0 foo test 3 1.0 2013-01-02 1
1 foo train 3 1.0 2013-01-02 1
2 foo test 3 1.0 2013-01-02 1
3 foo train 3 1.0 2013-01-02 1
A B C D E F
3 1 2013-01-02 1.0 3 train foo
2 1 2013-01-02 1.0 3 test foo
1 1 2013-01-02 1.0 3 train foo
0 1 2013-01-02 1.0 3 test foo
A B C D E F
3 1 2013-01-02 1.0 3 train foo
1 1 2013-01-02 1.0 3 train foo
2 1 2013-01-02 1.0 3 test foo
0 1 2013-01-02 1.0 3 test foo
# 选择数据
import pandas as pd
import numpy as np
dates = pd.date_range('20130101',periods =6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index = dates, columns=['A','B','C','D'])
print df
print df['A']
print df.A
print df[0:3], df['2013-01-01':'2013-01-03']
#select by label:loc
print df.loc['2013-01-01']
print df.loc[:,['A','B']]
print df.loc['2013-01-01',['A','B']]
#select by position: iloc
print df.iloc[3]
print df.iloc[3,1]
print df.iloc[3:5,1:3]
print df.iloc[[1,3,5],1:3]
# mixed selection :ix
print df.ix[:3,['A','C']]
#Boolean indexing
print df[df.A > 8]
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
2013-01-01 0
2013-01-02 4
2013-01-03 8
2013-01-04 12
2013-01-05 16
2013-01-06 20
Freq: D, Name: A, dtype: int64
2013-01-01 0
2013-01-02 4
2013-01-03 8
2013-01-04 12
2013-01-05 16
2013-01-06 20
Freq: D, Name: A, dtype: int64
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11 A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
A 0
B 1
C 2
D 3
Name: 2013-01-01 00:00:00, dtype: int64
A B
2013-01-01 0 1
2013-01-02 4 5
2013-01-03 8 9
2013-01-04 12 13
2013-01-05 16 17
2013-01-06 20 21
A 0
B 1
Name: 2013-01-01 00:00:00, dtype: int64
A 12
B 13
C 14
D 15
Name: 2013-01-04 00:00:00, dtype: int64
13
B C
2013-01-04 13 14
2013-01-05 17 18
B C
2013-01-02 5 6
2013-01-04 13 14
2013-01-06 21 22
A C
2013-01-01 0 2
2013-01-02 4 6
2013-01-03 8 10
A B C D
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
# 选择数
import pandas as pd
import numpy as np
dates = pd.date_range('20130101', periods = 6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index = dates, columns=['A','B','C','D'])
print df
df.iloc[2,2] = 111
print df
df.loc['20130101','B'] = 222
print df
# df[df.A >4] = 0
# df.A[df.A >4] = 0
# print df
df.B[df.A >4] = 0
print df
df['F'] = np.nan
print df
df['E'] = pd.Series([1,2,3,4,5,6],index = pd.date_range('20130101',periods= 6))
print df
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 111 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
A B C D
2013-01-01 0 222 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 111 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
A B C D
2013-01-01 0 222 2 3
2013-01-02 4 5 6 7
2013-01-03 8 0 111 11
2013-01-04 12 0 14 15
2013-01-05 16 0 18 19
2013-01-06 20 0 22 23
A B C D F
2013-01-01 0 222 2 3 NaN
2013-01-02 4 5 6 7 NaN
2013-01-03 8 0 111 11 NaN
2013-01-04 12 0 14 15 NaN
2013-01-05 16 0 18 19 NaN
2013-01-06 20 0 22 23 NaN
A B C D F E
2013-01-01 0 222 2 3 NaN 1
2013-01-02 4 5 6 7 NaN 2
2013-01-03 8 0 111 11 NaN 3
2013-01-04 12 0 14 15 NaN 4
2013-01-05 16 0 18 19 NaN 5
2013-01-06 20 0 22 23 NaN 6
# 处理丢失数据
import pandas as pd
import numpy as np
dates = pd.date_range('20130101', periods = 6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index = dates, columns=['A','B','C','D'])
df.iloc[0,1] = np.nan
df.iloc[1,2] = np.nan
print df
# A B C D
# 2013-01-01 0 NaN 2.0 3
# 2013-01-02 4 5.0 NaN 7
# 2013-01-03 8 9.0 10.0 11
# 2013-01-04 12 13.0 14.0 15
# 2013-01-05 16 17.0 18.0 19
# 2013-01-06 20 21.0 22.0 23
# print df.dropna(axis = 0,how ='any') # how = {'any',all}
# A B C D
# 2013-01-03 8 9.0 10.0 11
# 2013-01-04 12 13.0 14.0 15
# 2013-01-05 16 17.0 18.0 19
# 2013-01-06 20 21.0 22.0 23
# print df.dropna(axis = 1,how ='any') # how = {'any',all}
# A D
# 2013-01-01 0 3
# 2013-01-02 4 7
# 2013-01-03 8 11
# 2013-01-04 12 15
# 2013-01-05 16 19
# 2013-01-06 20 23
# print df.fillna(value = 0)
# A B C D
# 2013-01-01 0 0.0 2.0 3
# 2013-01-02 4 5.0 0.0 7
# 2013-01-03 8 9.0 10.0 11
# 2013-01-04 12 13.0 14.0 15
# 2013-01-05 16 17.0 18.0 19
# 2013-01-06 20 21.0 22.0 23
# print df.isnull()
# A B C D
# 2013-01-01 0 0.0 2.0 3
# 2013-01-02 4 5.0 0.0 7
# 2013-01-03 8 9.0 10.0 11
# 2013-01-04 12 13.0 14.0 15
# 2013-01-05 16 17.0 18.0 19
# 2013-01-06 20 21.0 22.0 23
# print np.any(df.isnull()) == True
# True
A B C D
2013-01-01 0 NaN 2.0 3
2013-01-02 4 5.0 NaN 7
2013-01-03 8 9.0 10.0 11
2013-01-04 12 13.0 14.0 15
2013-01-05 16 17.0 18.0 19
2013-01-06 20 21.0 22.0 23
True
# 导入导出
# pandas当中 哪些可以读取的格式
# read_csv
# read_excel
# read_hdf
# read_sql
# read_json
# read_msgpack
# read_html
# read_gbq
# read_stata
# read_sas
# read_clipboard
# read_pickle
import pandas as pd
data = pd.read_csv('student.csv')
data.to_pickle('student.pickle')
# 合并多个
import pandas as pd
import numpy as np
#concatenating
df1 = pd.DataFrame(np.ones((3,4)) * 0,columns = ['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4)) * 1,columns = ['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4)) * 2,columns = ['a','b','c','d'])
print df1
print df2
print df3
res = pd.concat([df1,df2,df3],axis = 0, ignore_index = True)
print res
res = pd.concat([df1,df2,df3],axis = 1)
print res
#join,['inner','outer']
df4 = pd.DataFrame(np.ones((3,4)) * 0,columns = ['a','b','c','d'],index = [1,2,3])
df5 = pd.DataFrame(np.ones((3,4)) * 1,columns = ['b','c','d','e'],index = [2,3,4])
print df4
print df5
res1 = pd.concat([df4,df5])#默认outer
print res1
res1 = pd.concat([df4,df5],join='inner',ignore_index = True)
print res1
res2 = pd.concat([df4,df5],axis=1 ,join_axes=[df1.index])
print res2
res3 = df1.append([df2,df1],ignore_index = True)
print res3
s1 = pd.Series([1,2,3,4],index=['a','b','c','d'])
res4 = df1.append(s1,ignore_index = True)
print res4
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
a b c d
0 1.0 1.0 1.0 1.0
1 1.0 1.0 1.0 1.0
2 1.0 1.0 1.0 1.0
a b c d
0 2.0 2.0 2.0 2.0
1 2.0 2.0 2.0 2.0
2 2.0 2.0 2.0 2.0
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
6 2.0 2.0 2.0 2.0
7 2.0 2.0 2.0 2.0
8 2.0 2.0 2.0 2.0
a b c d a b c d a b c d
0 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0 2.0 2.0 2.0 2.0
1 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0 2.0 2.0 2.0 2.0
2 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0 2.0 2.0 2.0 2.0
a b c d
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0
b c d e
2 1.0 1.0 1.0 1.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
a b c d e
1 0.0 0.0 0.0 0.0 NaN
2 0.0 0.0 0.0 0.0 NaN
3 0.0 0.0 0.0 0.0 NaN
2 NaN 1.0 1.0 1.0 1.0
3 NaN 1.0 1.0 1.0 1.0
4 NaN 1.0 1.0 1.0 1.0
b c d
0 0.0 0.0 0.0
1 0.0 0.0 0.0
2 0.0 0.0 0.0
3 1.0 1.0 1.0
4 1.0 1.0 1.0
5 1.0 1.0 1.0
a b c d b c d e
0 NaN NaN NaN NaN NaN NaN NaN NaN
1 0.0 0.0 0.0 0.0 NaN NaN NaN NaN
2 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
6 0.0 0.0 0.0 0.0
7 0.0 0.0 0.0 0.0
8 0.0 0.0 0.0 0.0
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 2.0 3.0 4.0
## merge 合并
import pandas as pd
left = pd.DataFrame({'key':['K0','K1','K2','K3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
right = pd.DataFrame({'key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
print left
print right
res = pd.merge(left,right,on='key')
print res
left1 = pd.DataFrame({'key1':['K0','K0','K1','K2'],
'key2':['K0','K1','K0','K1'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
right1 = pd.DataFrame({'key1':['K0','K1','K1','K2'],
'key2':['K0','K0','K0','K0'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
# res1 = pd.merge(left1,right1, on=['key1','key2'],how = 'inner')
# res1 = pd.merge(left1,right1, on=['key1','key2'],how = 'outer',indicator= True)
res1 = pd.merge(left1,right1, on=['key1','key2'],how = 'outer',indicator= 'indicator_column')
print res1
res2 = pd.merge(left,right,left_index=True,right_index=True,how='outer')
print res2
boys = pd.DataFrame({'k':['K0','K1','K2'], 'age':[1,2,3]})
girls = pd.DataFrame({'k':['K0','K1','K2'],'age':[4,5,6]})
res3 = pd.merge(boys,girls,on='k',suffixes=['_boy','_girl'],how= 'inner')
print res3
A B key
0 A0 B0 K0
1 A1 B1 K1
2 A2 B2 K2
3 A3 B3 K3
C D key
0 C0 D0 K0
1 C1 D1 K1
2 C2 D2 K2
3 C3 D3 K3
A B key C D
0 A0 B0 K0 C0 D0
1 A1 B1 K1 C1 D1
2 A2 B2 K2 C2 D2
3 A3 B3 K3 C3 D3
A B key1 key2 C D indicator_column
0 A0 B0 K0 K0 C0 D0 both
1 A1 B1 K0 K1 NaN NaN left_only
2 A2 B2 K1 K0 C1 D1 both
3 A2 B2 K1 K0 C2 D2 both
4 A3 B3 K2 K1 NaN NaN left_only
5 NaN NaN K2 K0 C3 D3 right_only
A B key_x C D key_y
0 A0 B0 K0 C0 D0 K0
1 A1 B1 K1 C1 D1 K1
2 A2 B2 K2 C2 D2 K2
3 A3 B3 K3 C3 D3 K3
age_boy k age_girl
0 1 K0 4
1 2 K1 5
2 3 K2 6
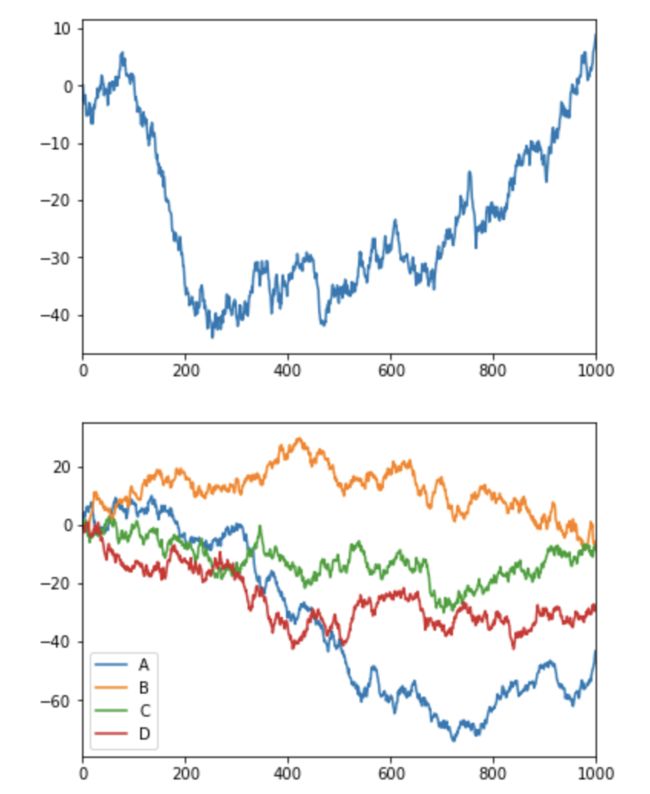
# plot图像
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#Series
data = pd.Series(np.random.randn(1000),index = np.arange(1000))
data = data.cumsum()
data.plot()
plt.show()
#dataFrame
data = pd.DataFrame(np.random.randn(1000,4), index = np.arange(1000),columns=list("ABCD"))
# print data
data = data.cumsum()
data.plot()
plt.show()
#plot methods:
#'bar' 'hist' 'box' 'kde' 'area' 'scatter' 'hexbin' 'pie'