该系列将描述一些自然语言处理方面的技术,完整目录请点击这里。
在 NLP 问题中,有两个问题是比较重要的标记问题:词性标注和命名实体识别。
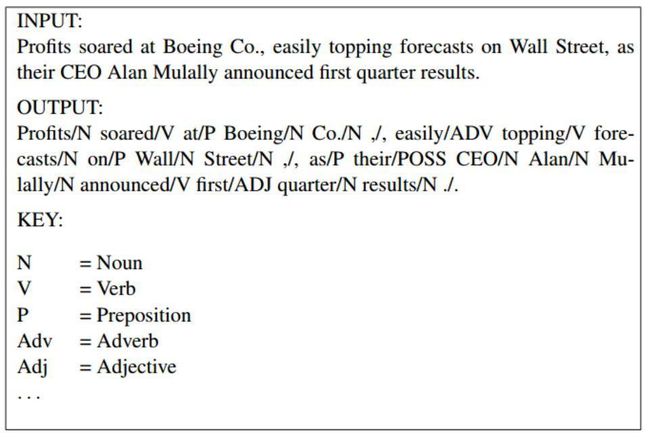
比如上图我们介绍了一个简单的词性标注问题。模型输入的是一个句子,输出是一个标记序列,模型会为每个词都产生一个标记。我们的目标是构建一个高精度的词性标注模型。词性标注问题是 NLP 中最基础的问题之一,在很多的应用中都有用。
我们假设我们有一个标记训练集,也就是每个句子都带有标记序列。比如,Penn WSJ 包含 100万字(包含 40000 句子),并且已经被标记。类似的数据集还有很多。
词性标注的一个最大的挑战是歧义。很多的英文单词可能有多种不同的划分,别的语言也同样存在这个问题。比如上图中,就有几个比较含糊的单词。比如,句子中第一个单词 “profits”,在这个上下文语境中,它是一个名词,但是在别的语境中它可能是一个动词(例如,句子 “in the company profits from its endeavors”)。单词 “topping” 在这个句子中是一个动词,但是它也可以作为一个名词,比如 “the topping on the cake” 。单词 “forecasts” 和 “results” 在这个句子中都是名词。但是在其他的语境中,这两个单词都可以表示动词。我们进一步观察,单词 “quarter” 在句子中是一个名词,但是它也可以作为一个动词,只是使用的频率很低。所以,从这句话中,我们就可以发现词性标注确实存在很多的歧义。
第二个挑战是对低频词的判断,特别是一些在训练集中没有出现的词。即使在 100 万词的训练数据中,我们在测试集中也会出现很多没有看到过的词。举个例子,词 “Mulally” 和词 “topping” 这样的词语可能是相当的稀少,可能不会出现在我们的训练数据集里面。所以,如何去解决一些没有出现在训练集中的词是一个比较迫切的问题。
在计算词性标注时,我们会考虑两种不同的信息来源。第一,从统计学来说,单词在一个句子中属于不同词性是有一定的概率的。比如,“quarter” 这个词可以是名词也可以是动词,但是从统计学来说,它作为一个名词的概率更大。第二,上下文的信息对词性标注也有很重要的作用。特别是,一些句子的序列标注比别的序列标注存在的可能性更大。比如,我们考虑一个三元组序列 (D N V) ,这个序列出现在英语中的概率非常大(比如,the/D dog/N saw/N),但是序列 (D V N) 在英文中出现的概率就小很多了。
但有时候这两种信息会产生冲突,比如这个句子:

在这个句子中,can 我们应该标注成名词。但是,can 也能被标注成动词的,而且这个被使用的更加频繁。在这个句子中,由于上下文的关系 can 被标注成动词的概率已经被覆盖了。

图1是另一个比较重要的标注问题——命名实体识别。在这个标注问题中,模型的输入还是一个句子,输出是一个命名实体识别标记好的句子。在这个例子中,我们假设只存在三种可能的实体类型:PERSON,LOCATION 和 COMPANY。在这个例子中,我们将 Boeing Co 识别为一个公司名,Wall Street 识别为一个地点,Alan Mulally 识别为一个任命。对人名、地点和组织机构的识别时非常重要的研究内容,而且这些研究已经被应用到了实际的 NLP 项目中。

乍一看,命名实体识别好像不是标注问题。在图 1 中,输出句子没有把每一个词都进行标注。然而,将命名实体识别认为是一个标注问题是最直接的。最基础的标注方法就如图 2 中所示,如果单词不是实体的一部分,那么就被标注为 NA,如果一个词是公司的第一个单词那么就被标注为 SC,如果是公司的后几个单词,那么就被标注为 CC。
一旦我们在训练集上面得到了这种映射关系,那么在新的测试集上面我们就可以对句子进行测试标记了。